KV Cache: The Trick That Lets LLMs Remember Without Recomputing
KV Cache: How LLMs Avoid Recomputing the Past
Large language models generate text one token at a time. At every step, the model attends to all previous tokens. Naively, this would require recomputing the Key (K) and Value (V) projections for the whole sequence every time a new token is generated.
KV cache fixes this inefficiency.
Instead of recomputing those K and V projections for past tokens, the model stores them once and reuses them. Two precise points to keep from the start, because the word “cache” (and the title’s “remember”) invites the wrong mental model:
- The cache stores K/V projections, not attention outputs. The new token’s query still has to attend over all cached positions - that work does not disappear. What the cache removes is the recomputation of past K and V.
- This is transient, per-request inference state, not memory in any semantic sense. It doesn’t teach the model facts, it doesn’t persist across independent requests, and it doesn’t extend the context window. It is a scratchpad that lives and dies with a single generation.
Let’s walk through a tiny example.
Toy Setup
Vocabulary:
1
["<s>", "the", "cat", "sat"]
Prompt:
1
"<s> the cat"
Goal: predict "sat"
Model setup:
1
2
3
d_model = 4
num_heads = 1
num_layers = 1 # simplification: real models stack many layers
One simplification to flag before the walkthrough. Below we write K = embedding(token) * W_K, as if K and V were projections of the raw token embedding. That is only true at the first layer. At every subsequent transformer layer, K and V are projections of that layer’s input hidden states (the output of the layer below), not the raw embedding. So a real decoder with $L$ attention layers keeps $L$ separate KV caches, one per layer. And note the query is not cached: ordinary causal decoding only ever needs the current token’s query, so there is nothing to reuse.
Without KV Cache (Naive Approach)
Each generation step recomputes attention for all previous tokens.
Step 1: Predict "cat"
Input:
1
["<s>", "the"]
Compute query for the current token:
1
Q2 = embedding("the") * W_Q
Compute keys and values for all tokens so far:
1
2
K1,K2 = embedding(["<s>","the"]) * W_K
V1,V2 = embedding(["<s>","the"]) * W_V
Run attention:
1
Attention(Q2, K1:K2, V1:V2) → logits("cat")
Step 2: Predict "sat"
Input:
1
["<s>", "the", "cat"]
Compute query:
1
Q3 = embedding("cat") * W_Q
Recompute keys and values for all tokens again:
1
2
K1,K2,K3 = embedding(["<s>","the","cat"]) * W_K ❌ recompute
V1,V2,V3 = embedding(["<s>","the","cat"]) * W_V ❌ recompute
Run attention:
1
Attention(Q3, K1:K3, V1:V3) → logits("sat")
The model repeatedly recomputes attention for earlier tokens.
With KV Cache (Efficient Approach)
Instead of recomputing keys and values, we store them once and reuse them.
Step 1: Predict "cat"
Same as before.
After computing keys and values:
1
2
K_cache = [K1, K2]
V_cache = [V1, V2]
Step 2: Predict "sat"
Input:
1
["<s>", "the", "cat"]
Only compute new projections:
1
2
3
Q3 = embedding("cat") * W_Q
K3 = embedding("cat") * W_K
V3 = embedding("cat") * W_V
Append to cache:
1
2
K_cache = [K1, K2, K3]
V_cache = [V1, V2, V3]
Run attention:
1
Attention(Q3, K_cache, V_cache) → logits("sat")
Past tokens are never recomputed.
Prefill vs. Decode: Two Phases
The example above quietly spans two distinct phases of inference, and it is worth separating them because they have very different cost profiles:
- Prefill. The prompt is processed in one shot. All prompt tokens go through the model together (their attention can be computed in parallel), and this populates the initial KV cache - every layer’s K/V for every prompt position. Prefill is compute-heavy but happens once.
- Decode. New tokens are generated one at a time. Each step computes the K/V for only the new token at each layer, appends them to the cache, and attends over everything cached so far.
The cache is what makes decode cheap: it removes the repeated projection of the prompt and of previously generated tokens. It does not make prefill free - the prompt still has to be ingested once. A three-token trace makes the split concrete:
| Phase | Newly computed | Reused from cache |
|---|---|---|
| Prompt prefill | all prompt tokens’ hidden states + every layer’s K/V | nothing |
| First decode step | the new token’s state + its K/V (per layer) | all prompt K/V |
| Next decode step | one new token’s state + its K/V (per layer) | prompt + all prior generated K/V |
Visualizing Cache Growth
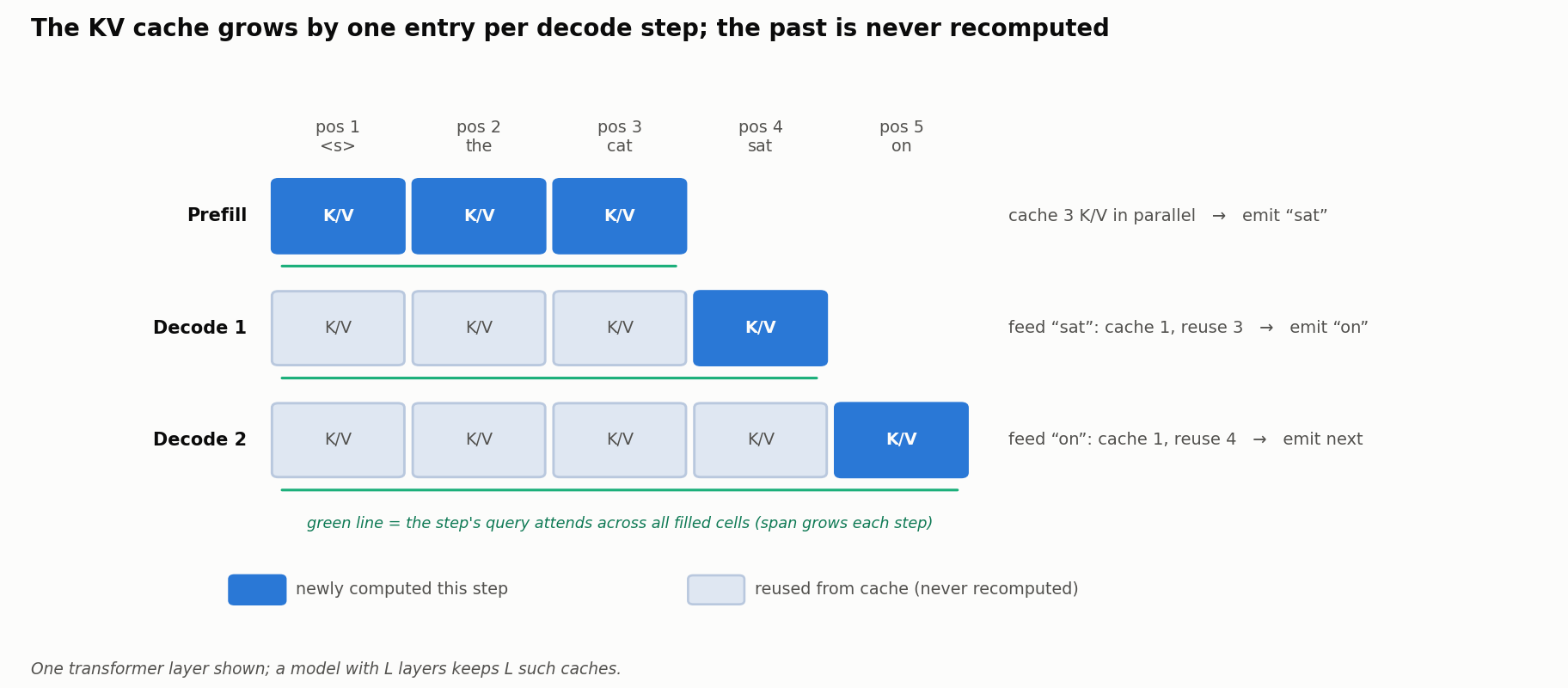
The one detail worth pausing on is the one-step lag between caching and emitting. A step caches the K/V of the token it was handed as input - the token the previous step emitted - and the token it emits is only cached on the next step. Prefill emits the first generated token; each decode step then feeds that token back in and produces the following one. Written out along the prefill/decode split:
Prefill (positions 1-3, in parallel)
1
2
3
4
Process "<s> the cat"
[ Q1 Q2 Q3 | K1 K2 K3 ] [ V1 V2 V3 ]
Cache = [K1,K2,K3] → emit "sat"
Decode step 1 (feed “sat” as position 4)
1
2
[ Q4 | K1 K2 K3 K4 ] [ V1 V2 V3 V4 ]
Cache = [K1,K2,K3,K4] → emit "on"
Decode step 2 (feed “on” as position 5)
1
2
[ Q5 | K1..K5 ] [ V1..V5 ]
Cache = [K1..K5] → emit next token
Time Complexity Analysis
To understand the time complexity of the attention mechanism, we need to establish two variables: $n$ (the sequence length) and $d_{model}$ (the embedding dimension or hidden state size).
The impact of the Key-Value (KV) cache only applies to the autoregressive decoding phase (when the model is generating text token-by-token).
Here is the breakdown of the time complexity for generating the $n$-th token in a sequence.
1. Without KV Cache (Naive Generation)
If we do not use a KV cache, the model has no “memory” of the calculations it performed for previous tokens. To generate the $n$-th token, the model must re-process the entire sequence of $n$ tokens from scratch.
- Linear Projections ($Q, K, V$): Multiplying the $n \times d_{model}$ input matrix by the $d_{model} \times d_{model}$ weight matrices takes $O(n \cdot d_{model}^2)$.
- Attention Scores ($Q \cdot K^T$): Multiplying the $n \times d_{model}$ Query matrix by the $d_{model} \times n$ Key matrix takes $O(n^2 \cdot d_{model})$.
- Weighted Sum (Scores $\cdot V$): Multiplying the $n \times n$ attention matrix by the $n \times d_{model}$ Value matrix takes $O(n^2 \cdot d_{model})$.
Time Complexity for the $n$-th token: $O(n^2 \cdot d_{model} + n \cdot d_{model}^2)$
Because sequence length ($n$) is usually the scaling bottleneck, the attention complexity alone is typically expressed as $O(n^2 \cdot d_{model})$.
Note: If we are generating a full sequence of $n$ tokens without a cache, this step runs $n$ times, making the cumulative complexity a massive $O(n^3 \cdot d_{model})$.
2. With KV Cache (Optimized Generation)
During generation, the past tokens do not change, which means their Key ($K$) and Value ($V$) vectors do not change either. A KV cache stores these previously computed $K$ and $V$ vectors in memory.
When generating the $n$-th token, the model only needs to process the single new token (a $1 \times d_{model}$ vector):
- Linear Projections: Compute $q, k, v$ for just the 1 new token. This takes $O(d_{model}^2)$.
- Update Cache: The new $k$ and $v$ vectors are appended to the cached matrices (which now become size $n \times d_{model}$).
- Attention Scores ($q \cdot K^T$): Multiply the $1 \times d_{model}$ query vector by the $d_{model} \times n$ cached Key matrix. This takes $O(n \cdot d_{model})$.
- Weighted Sum (Scores $\cdot V$): Multiply the $1 \times n$ score vector by the $n \times d_{model}$ cached Value matrix. This takes $O(n \cdot d_{model})$.
Time Complexity for the $n$-th token: $O(n \cdot d_{model} + d_{model}^2)$
By caching the past, the attention bottleneck for generating a new token drops from quadratic to linear: $O(n \cdot d_{model})$.
Note: generating a full sequence of $n$ tokens with a cache runs this step $n$ times, so the cumulative attention cost is $O(n^2 \cdot d_{model})$ - quadratic in total, but paid one linear slice at a time rather than re-doing the whole prefix at every step.
Summary Comparison
Here is how the time complexity compares when generating the $n$-th token:
| Generation Phase | Attention Complexity | Total Complexity (incl. Projections) |
|---|---|---|
| Without KV Cache | $O(n^2 \cdot d_{model})$ | $O(n^2 \cdot d_{model} + n \cdot d_{model}^2)$ |
| With KV Cache | $O(n \cdot d_{model})$ | $O(n \cdot d_{model} + d_{model}^2)$ |
Two honest caveats on these numbers. First, they count only the attention and projection work; the per-token feed-forward (MLP) cost, which is often the larger constant in practice, is left out, so this is not the complete transformer cost. Second, the win is best read as prompt length $p$ plus generated length $g$: the cache eliminates re-projecting the $p+g-1$ prior tokens at each decode step, so the per-token cost grows linearly with the current context while the total across a long generation stays quadratic. The KV cache trades memory (space) for speed (time) - it does not make attention sub-quadratic overall.
KV Cache Memory Footprint
The cache consumes memory proportional to the number of cached tokens. For ordinary dense storage:
\[\text{bytes} = 2 \times B \times L \times T \times H_{kv} \times d_{h} \times b\]Where:
- the leading 2 accounts for both the Key and Value tensors;
- $B$ = active batch / concurrent-sequence count (easy to forget, and it scales everything linearly);
- $L$ = number of attention layers;
- $T$ = number of cached tokens;
- $H_{kv}$ = number of KV heads (not query heads - see below);
- $d_{h}$ = head dimension;
- $b$ = bytes per element (2 for FP16/BF16).
At one layer, the tensors have shapes: the current query is $[B, H_q, 1, d_h]$, while the cached keys and values are each $[B, H_{kv}, T, d_h]$ and grow to $[B, H_{kv}, T{+}1, d_h]$ after appending the new token.
$H_{kv}$ is the big memory lever. This is exactly what the attention variants trade on:
- MHA (Multi-Head Attention): $H_{kv} = H_q$ - every query head has its own K/V. Largest cache.
- GQA (Grouped-Query Attention): several query heads share a KV head, so $1 < H_{kv} < H_q$. Smaller cache.
- MQA (Multi-Query Attention): $H_{kv} = 1$ - all query heads share one K/V. Smallest cache. (MQA is just the $H_{kv}=1$ edge case of GQA.)
Example (dense, all layers full attention). Take a Gemma-3-270M-like configuration - 18 layers, head dimension 256, and one KV head - at $T=2048$, $B=1$, BF16:
\[2 \times 1 \times 18 \times 2048 \times 1 \times 256 \times 2 = 37{,}748{,}736 \text{ bytes} \approx 36 \text{ MiB}.\]But that figure assumes every layer caches all 2048 tokens, which real models increasingly avoid. Gemma 3 270M actually uses GQA with a single KV head (the value above), and, more importantly, 15 of its 18 layers use sliding-window attention with a 512-token window; only 3 layers use full attention (Gemma 3 technical report). A sliding-window layer never caches more than its window, so at $T=2048$:
\[\underbrace{3 \times 2048}_{\text{full layers}} + \underbrace{15 \times 512}_{\text{window layers}} = 13{,}824 \text{ layer-tokens} \;\Rightarrow\; 2 \times 1 \times 13{,}824 \times 1 \times 256 \times 2 \approx 13.5 \text{ MiB}.\]So the sliding-window design cuts the cache to roughly a third of the naive dense estimate - a concrete example of the biggest lever in production: some layers stop growing. Real deployments also pay for batch size, beam width, concurrent requests, and padding/allocation policy on top of this per-sequence figure, so treat it as a floor, not a budget.
Production Cache Strategies
Once the cache is the memory bottleneck (and at long context, decode is often memory-bandwidth-bound - dominated by reading the growing cache, not by arithmetic), a whole toolbox appears. None is a free win; each trades something:
- Paged attention + continuous batching. Store the cache in fixed-size “pages” (like OS virtual memory) instead of one contiguous block, so many requests of different lengths pack into GPU memory without wasteful padding, and new requests can join a running batch.
- Sliding-window / chunked attention. As we just saw with Gemma 3, some layers only attend to a recent window, so their cache stops growing - trading a little long-range recall for a bounded footprint.
- Prefix sharing. Requests with a common prefix (a shared system prompt) can share that portion of the cache instead of duplicating it.
- Offloading. Move cold parts of the cache to CPU RAM. Saves GPU memory, but the transfer back can worsen latency.
- KV-cache quantization. Store K/V in 8-, 4-, or even 2-bit instead of 16-bit. This is the same idea as weight quantization, applied to the cache - covered in the quantization series; it cuts memory but adds de-quantization work.
- Eviction / recomputation. Drop or recompute low-importance entries under pressure.
The through-line: there is no universally best cache strategy. Quantizing or offloading saves memory while often costing latency; sliding windows save memory while capping recall. The Hugging Face docs on cache internals and cache strategies are a good next stop for the implementation details.
Key Insight
KV cache stores the Key and Value projections of past tokens.
Each new token only computes:
- Its own query
- Its own key/value
- Attention against cached history
This avoids recomputing attention for previous tokens and enables fast autoregressive generation.