Decoding RAG Evaluation: When Your Pipeline Fails, Who is to Blame?
Retrieval-Augmented Generation (RAG) has rapidly become a widely used architecture for bridging the gap between static Large Language Models (LLMs) and dynamic, proprietary data. By fetching relevant documents and injecting them into the LLM’s prompt, RAG can ground answers in current or private evidence the model never saw in training. What it does not do is guarantee correctness: retrieval can miss the right passage, the prompt can bury it, and the model can still ignore what it was handed. RAG changes where the evidence comes from; it does not, on its own, promise hallucination-free answers.
So what happens when the system generates a bad answer?
If we simply look at the final output and declare, “This is wrong,” we are treating a complex, multi-stage pipeline as a black box. A bad response could stem from a faulty search query, a poorly constructed prompt, or a confused LLM. To effectively evaluate and debug a RAG pipeline, we must assess it from first principles: Retrieval, Augmentation, and Generation.
Let’s break down where things go wrong in each of these three distinct phases, how to measure them quantitatively, and how to fix them.
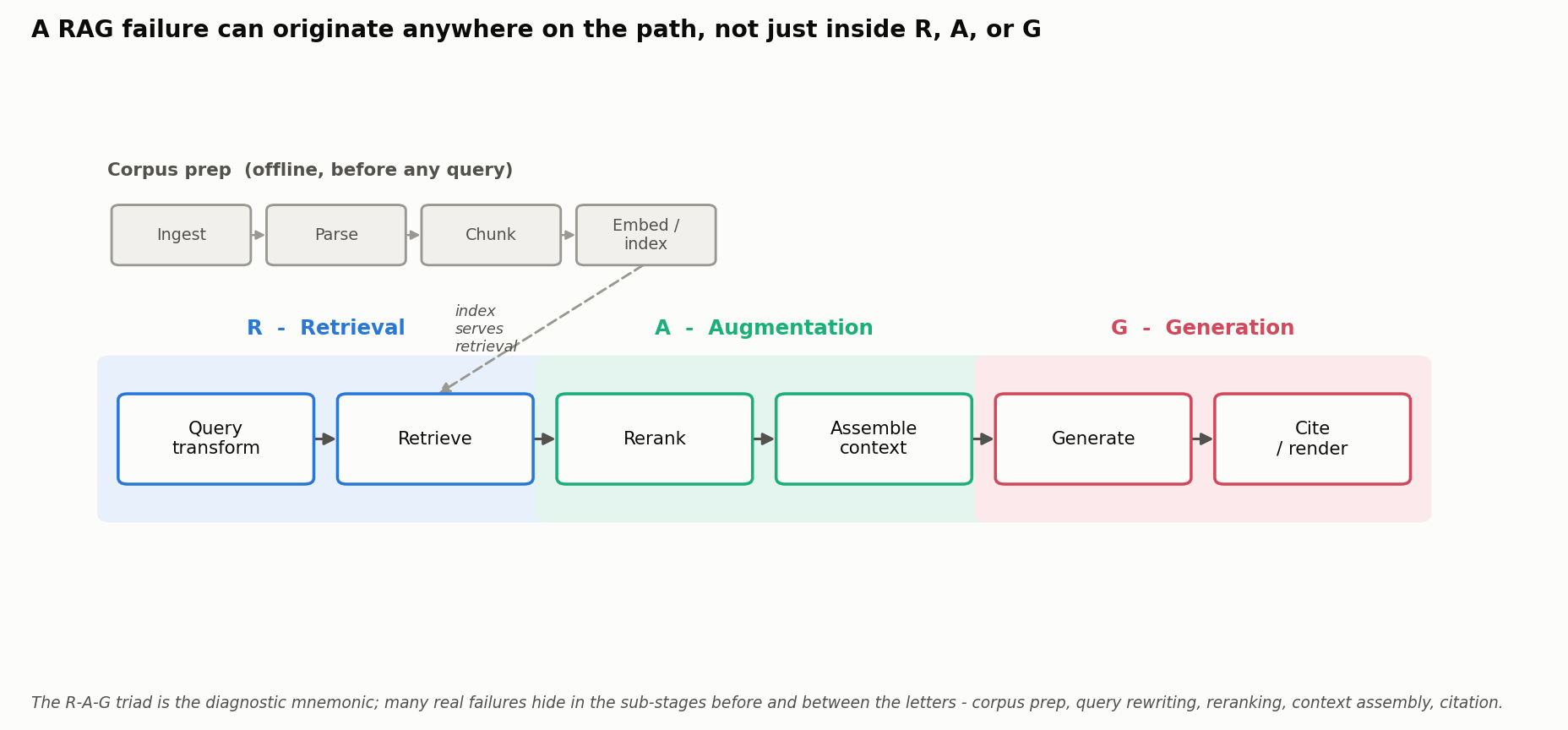
One caution before we start: the R-A-G triad is a diagnostic mnemonic, not the full list of places a pipeline can break. A real system also has an offline corpus-prep path (ingestion, parsing, chunking, indexing) and, at query time, sub-stages like query transformation, reranking, context assembly, and citation rendering. A failure at any of these masquerades as an “R,” “A,” or “G” problem downstream, so we keep the triad as the organizing frame while staying alert to the sub-stages between the letters.
Before the metrics: build the evaluation set
Metrics are meaningless without judgments to score against, so the first artifact is not a number, it is a gold evaluation set. Each example should specify, where applicable:
- the query, plus the user or context slice it belongs to;
- whether the question is even answerable from the corpus (unanswerable cases test abstention);
- the relevant passages, ideally with graded relevance;
- the specific facts a complete answer must contain;
- a reference answer or scoring rubric, and the citations we expect;
- any permission boundary or freshness requirement.
Just as important, we slice the set: temporal, multilingual, ambiguous, adversarial, and unanswerable queries each stress a different failure mode, and a single overall mean hides all of them. Without this scaffolding, “Context Recall = 66%” is a number with no denominator we can trust.
1. Retrieval (R): The Search Failure
The foundational step of a RAG pipeline is the Retriever. Its sole job is to search our vector database and return the chunks of text most relevant to the user’s query.
How it goes wrong
If a user asks about “Q3 profit margins” and the retriever pulls up documents about “Q1 employee onboarding,” the entire pipeline is doomed before the LLM even sees the prompt. Retrieval failures usually stem from poor embedding models that misunderstand semantic intent, inappropriate chunk sizes (cutting off vital context midway through a sentence), or relying solely on vector search without keyword fallback.
Measuring Retrieval: Traditional & RAG-Native Metrics
Before we even involve an LLM to generate text, we must evaluate the quality of the documents our retriever returns. We do this using a mix of traditional Information Retrieval (IR) math and RAG-native evidence checks.
RAG-Native Metrics: Context Precision and Context Recall
While traditional metrics evaluate document ranking, RAG-native metrics measure information usefulness. Let’s look at a toy example:
The Scenario
A user asks, “What were the Q3 revenue, profit, and user growth numbers?” To fully answer this, we need 3 specific facts. Our retriever fetches 5 text chunks from the database to feed to the LLM.
- Chunk 1: Contains the revenue number (Relevant).
- Chunk 2: Contains the profit number (Relevant).
- Chunk 3: Unrelated marketing fluff (Irrelevant).
- Chunk 4: Discusses Q1 data, not Q3 (Irrelevant).
- Chunk 5: CEO’s opening remarks (Irrelevant).
- (The user growth number is missing entirely).
Context Recall (Did we find everything we needed?)
- What it is: The ratio of required facts successfully retrieved vs. total facts needed to answer the question perfectly.
- Calculation: We needed 3 facts. We found 2 (Revenue and Profit).
- Result: Context Recall = 2 / 3 = 66.6%.
- Why it matters: If Context Recall is low, the Generation phase is guaranteed to fail. The LLM is starved of evidence and forced to either hallucinate or reply “I don’t know”.
Context Precision (How much of what we retrieved was actually useful?)
- What it is: The ratio of relevant chunks retrieved vs. the total number of chunks retrieved.
- Calculation: We retrieved 5 chunks. Only 2 were relevant.
- Result: Context Precision = 2 / 5 = 40.0%.
- Why it matters: If Context Precision is low, we are stuffing the LLM’s context window with noise, leading to higher API costs and triggering the “Lost in the Middle” phenomenon where the LLM forgets the useful facts.
A caveat on names. The “2 out of 3” and “2 out of 5” definitions above are deliberately simplified to build intuition. In practice, “context precision” and “context recall” are framework-specific terms, and the framework’s version may not match this arithmetic. Ragas, for instance, computes a rank-aware context precision (it rewards putting relevant chunks higher, not just present) and derives context recall against annotated reference facts or a ground-truth answer, not a number we eyeball. So the fact-recall denominator only exists once we have actually labeled the required facts, which is exactly why the gold set comes first. When we quote a metric, we pin the framework and version that produced it.
Traditional IR Metrics
While RAG-native metrics evaluate facts, traditional Information Retrieval (IR) metrics evaluate the ranking and relevance of the retrieved documents.
Mean Reciprocal Rank (MRR)
- What it is: MRR measures the effectiveness of a system trying to return a single correct answer. It evaluates how high up the first relevant item is in the recommended list.
- How it’s calculated: The Reciprocal Rank (RR) is the inverse of the rank of the first relevant item ($RR = \frac{1}{\text{rank}}$). MRR is the average across all queries:
- Example:
User 1:
\[\text{Item A, Item B ✓, Item C} \rightarrow \text{First relevant item is at rank 2. RR = 1/2.}\]User 2:
\[\text{Item D ✓, Item E, Item F} \rightarrow \text{First relevant item is at rank 1. RR = 1/1.}\]User 3:
\[\text{Item G, Item H, Item I ✓} \rightarrow \text{First relevant item is at rank 3. RR = 1/3.}\]
(Note: MRR has no universal good/bad cutoff - a “0.7 is good, 0.9 for QA” rule of thumb does not survive contact with different tasks, corpora, judgment quality, and product tolerances. Read it relative to a baseline and our own answerable-query slice, not an absolute bar. MRR also only looks at the first relevant result, so it is a weak signal when an answer needs several pieces of evidence - use Recall@k for coverage there.)
Precision@k
- What it is: Answers the question: “Out of the top k items we recommended, how many were actually relevant?”
- How it’s calculated: $\text{P@k} = \frac{\text{Number of relevant items in top-k}}{k}$
- Example: We recommend 10 movies (k=10). The user liked 4 of them.
Recommended:
\[M1✓, M2, M3, M4✓, M5, M6✓, M7, M8, M9✓, M10\]$\text{P@10} = \frac{4}{10} = 0.4$ (40% of the top 10 were relevant).
Recall@k (Document-Level Recall)
- What it is: Answers the question: “Out of all the documents the user would have liked, how many did we successfully find in our top k recommendations?” (Contrasts with Context Recall, which looks for facts, not specific documents).
- How it’s calculated: $\text{R@k} = \frac{\text{Number of relevant items in top-k}}{\text{Total number of relevant items}}$
- Example: There are 8 total relevant movies in the database. Our top 10 list captured 4 of them. $\text{R@10} = \frac{4}{8} = 0.5$ (We found 50% of all possible relevant movies).
Mean Average Precision (mAP)
- What it is: mAP considers the order of recommendations, rewarding systems that place relevant items higher on the list.
- How it’s calculated: Calculate Precision@k at every position
kwhere a relevant item is found, average them to get Average Precision (AP), and then find the mean across all users. - Example: Items 1, 3, and 5 are relevant in a 5-item list.
- Pos 1: P@1 = 1.0
- Pos 3: P@3 = 2/3 $\approx$ 0.67
- Pos 5: P@5 = 3/5 = 0.60
- $AP = \frac{1.0 + 0.67 + 0.6}{3} \approx 0.756$
Normalized Discounted Cumulative Gain (nDCG)
- What it is: Used when items have different levels of relevance (e.g., 0=bad, 3=perfect). It emphasizes highly relevant items and penalizes relevant items that appear later in the list using a logarithmic discount.
- How it’s calculated: Calculate Discounted Cumulative Gain (DCG) using the exponential formulation - which heavily rewards the most relevant items - and divide by the Ideal DCG (IDCG - the score if ranked perfectly).
- Example: Recommended list scores: $3, 1, 2, 0, 2$
- Ideal list scores: $3, 2, 2, 1, 0$
- $DCG_5 \approx \frac{7}{\log_2(2)} + \frac{1}{\log_2(3)} + \frac{3}{\log_2(4)} + \frac{0}{\log_2(5)} + \frac{3}{\log_2(6)} \approx 7.0 + 0.63 + 1.5 + 0 + 1.16 = 10.29$
- $IDCG_5 \approx \frac{7}{\log_2(2)} + \frac{3}{\log_2(3)} + \frac{3}{\log_2(4)} + \frac{1}{\log_2(5)} + \frac{0}{\log_2(6)} \approx 7.0 + 1.89 + 1.5 + 0.43 + 0 = 10.82$
- $nDCG_5 = \frac{10.29}{10.82} \approx 0.95$
(Note: While the exponential numerator $2^{rel_i} - 1$ is the default and most popular formulation because it emphasizes highly relevant results, a simpler linear formulation $\sum \frac{rel_i}{\log_2(i+1)}$ is also widely used depending on the specific search objective).
Remedies: Fixing the Retrieval Module
If our metrics (like Context Recall or MRR) are low, here is how we fix the Retriever:
- Hybrid Search: Don’t rely solely on dense vector embeddings. Combine Vector Search (semantic meaning) with BM25 / Keyword Search (exact phrasing) to capture specialized vocabulary or acronyms.
- Optimize Chunking Strategy: If chunks are too small, they lose context. If they are too large, they dilute the semantic meaning. Experiment with parent-child chunking.
- Metadata Filtering: Tag the chunks with metadata (e.g., date: 2023, department: HR) so we can pre-filter the vector database before performing the semantic search.
- Query Expansion & Decomposition (To fix Context Recall): If Context Recall is suffering, use a fast LLM to break a user’s complex question into several smaller sub-queries. Execute retrieval for each sub-query independently to drastically increase the odds of capturing all the necessary facts.
2. Augmentation (A): The Formatting Failure
Even if we retrieve the perfect documents, we still have to hand them over to the LLM. The Augmentation phase dictates how that retrieved context is packaged into the final prompt alongside the user’s question.
How it goes wrong
This is the most frequently overlooked failure mode. The most common pitfall is the “Lost in the Middle” phenomenon. If we retrieve 20 excellent documents and stuff them all into a massive prompt, the LLM will likely struggle to process them. Studies show that LLMs pay heavy attention to the very beginning and the very end of a long prompt, but tend to ignore or forget information buried in the middle.
Remedies: Fixing the Augmentation Module
Augmentation failures aren’t solved by better embeddings, they are solved by pipeline architecture:
- Implement a Re-ranker (Cross-Encoder): Our vector database might return 20 documents quickly, but a Cross-Encoder (like Cohere Rerank) can re-score them with extreme precision right before they are injected into the prompt, ensuring the absolute most critical document is at position #1.
- Strict Top-K Limits: Resist the urge to stuff the context window. Limiting the prompt to the Top 3 or Top 5 most relevant chunks dramatically reduces LLM confusion.
- Context Compression: Use a smaller, faster LLM to summarize or extract the key facts from the retrieved documents before passing them into the final prompt for the main LLM.
3. Generation (G): The Synthesis Failure
In the final phase, the LLM acts as the Generator. It must read the retrieved (and correctly augmented) context and synthesize an answer to the user’s question.
How it goes wrong
A generation failure occurs when we have provided perfect documents in a perfectly formatted prompt, but the LLM still messes up. This typically manifests in two ways:
- Hallucination: The LLM ignores the provided context and confidently invents a fact based on its pre-training data.
- Evasion/Misalignment: The LLM summarizes the context perfectly but completely misses the point of the user’s actual question.
How to measure it
Two of these terms, faithfulness and groundedness, are used interchangeably often enough to cause real confusion, so it helps to fix a single stable taxonomy and hold to it. We evaluate three distinct properties:
- Support (faithfulness): is every claim in the answer entailed by the retrieved evidence? This is the core hallucination check. A claim the evidence does not support is unfaithful, even if it happens to be true out in the world. Many frameworks (Ragas included) define faithfulness exactly this way, and use “groundedness” as a near-synonym, so we adopt the support-based definition here and drop the separate label.
- Correctness: is the claim actually true under a reference answer or rubric? Support and correctness can diverge: an answer can faithfully repeat wrong evidence, or state a true fact the evidence never mentioned (correct but unsupported).
- Answer Relevance: does the answer actually address the user’s question rather than evade it or drift onto a tangent?
Let’s imagine the retrieved context says: “The flagship phone costs \$800 and features a titanium frame”. The user asks: “Tell me about the new phone”. Three candidate answers:
- Answer A: “The phone costs \$800, features a titanium frame, and has great battery life”.
- Support: Low. “Great battery life” is nowhere in the evidence - an invented, unfaithful claim.
- Answer Relevance: High. It directly describes the phone.
- Answer B: “The phone costs \$800 and is made of titanium, which makes it very durable”.
- Support: Low/Moderate. Price and material are supported, but “very durable” is an inference the LLM added from its own world knowledge - the evidence never states it. Under a strict support definition, that one unsupported claim makes the answer unfaithful, not “faithful but merely ungrounded.” This is precisely the case the old faithfulness-versus-groundedness split scores inconsistently.
- Answer Relevance: High. It solves the query with relevant facts.
- Answer C: “Titanium is a chemical element”.
- Support: Low. It leans on general knowledge rather than the retrieved text.
- Answer Relevance: Low. Technically true, but it evades the actual question about the phone.
The lesson: a claim can be relevant, and even correct, while still being unsupported. Faithfulness is strictly about the tie between a claim and the evidence, and that tie is what a RAG system must control.
The “LLM-as-a-Judge” Approach
At this point, a natural question arises: How do we automatically calculate scores for Faithfulness, Groundedness, or Answer Relevance without a human manually reading every single response?
The industry standard is the “LLM-as-a-judge” approach. Historically, NLP developers used metrics like BLEU or ROUGE, which measure exact word overlaps. However, these are terrible for RAG pipelines because an LLM can provide a perfectly correct, highly relevant answer using entirely different vocabulary than the source text.
Instead, we use a powerful frontier LLM (like GPT-5, Gemini 3 etc.) as an automated grader. We prompt the Judge LLM with the retrieved context, the user’s query, and our pipeline’s generated answer. We ask the Judge to extract claims, check each against the evidence, and output a numeric score for support and relevance, together with a short cited rationale (a visible justification we can audit, not a hidden chain of thought we cannot).
This is useful and scalable, but it is not a free substitute for human judgment, and calling it “the industry standard” oversells it. LLM judges have well-documented failure modes: sensitivity to prompt wording, position and ordering effects when comparing answers, self-preference (favoring outputs from their own model family), domain blind spots, and plain run-to-run variance. To trust a judge’s numbers we have to calibrate it: score a human-labeled subset, measure agreement (and inter-rater agreement among the humans), swap answer ordering or blind it for comparisons, record the exact judge model, version, and prompt, and report uncertainty rather than a single point score. A judge whose agreement with humans was never measured is an opinion, not a metric.
Remedies: Fixing the Generation Module
If the LLM is hallucinating or missing the mark, these are candidate interventions - each to be tested against the eval set, not assumed to work:
- Strict System Prompting: Add guardrails to the prompt. Use explicit instructions like: “Answer ONLY using the provided context. If the answer is not contained in the context, output exactly: ‘I don’t know.’”
- Lower the Temperature: RAG rewards faithful synthesis over creative phrasing, so a low temperature (
0.0-0.2) is a reasonable default. Note the limits, though: temperature 0 does not guarantee bit-identical determinism (kernel and batching effects remain), and it does not make an answer grounded - a confidently wrong claim at temperature 0 is still wrong. It reduces variance, not error. - Chain of Thought (CoT): Ask the LLM to show its reasoning. Add “Think step-by-step and cite the document ID used before giving the final answer” to the prompt, so the citation trail is auditable.
- Upgrade the Generator: Sometimes a smaller model simply cannot synthesize complex context, and a stronger generator helps. But “upgrade the model” is not an automatic fix: if the real fault is retrieval or context assembly, a larger model just fails more fluently. Diagnose the failing component first. Likewise, context compression can save tokens but may strip the very evidence the answer needed, so measure recall after compressing.
4. Standardizing Evaluation: The Ragas Framework
Building custom evaluation scripts for Context Recall, Faithfulness, and Answer Relevance from scratch is tedious and error-prone. This is where frameworks like Ragas (Retrieval Augmented Generation Assessment) come in. Ragas is an open-source library specifically designed to standardize the evaluation of RAG pipelines.
How it helps
Ragas provides out-of-the-box Python functions that take our pipeline’s inputs (Question, Retrieved Contexts, Generated Answer, and optionally Ground Truth) and automatically calculates the RAG metrics using the LLM-as-a-judge approach under the hood.
Benefits of using Ragas
- Standardization: It provides mathematically rigorous definitions for metrics like Context Precision and Faithfulness, ensuring the AI community is measuring success the same way.
- CI/CD Integration: We can easily embed Ragas into our testing pipelines to automatically evaluate if a new embedding model, chunking strategy, or prompt tweak improved or degraded our system before deploying to production.
- Actionable Insights: By isolating the R-A-G phases, Ragas tells us exactly whether we need to fix the retriever or the generator.
Potential Drawbacks
- Judge Bias: Ragas relies on an LLM to grade our pipeline. If the Judge LLM has inherent biases, prefers certain writing styles, or struggles with highly complex domain-specific logic (like legal texts), our evaluation scores will be skewed.
- Cost and Latency: Running an evaluation dataset of 1,000 queries means making thousands of API calls to a Judge LLM. This can become expensive and slow compared to simple deterministic metrics.
5. Tying It Together: The Evaluation Matrix
The R-A-G phases each have their own question to answer and their own lever to pull. Laying them out as a matrix turns “the answer was bad” into a directed search for the failing layer:
| Layer | Offline measure | Failure question | Candidate intervention |
|---|---|---|---|
| Corpus / index | coverage, freshness, permission tests | Is the evidence even present and accessible? | ingestion / re-index / access fix |
| Retrieval / rerank | Recall@k, nDCG@k, latency | Is relevant evidence ranked within budget? | hybrid search, reranker, query rewrite |
| Context assembly | evidence coverage, token use, duplication | Did the useful evidence survive construction? | dedupe, ordering, chunk / parent strategy |
| Answer | support, correctness, completeness, abstention | Did the model use the evidence properly? | prompt, model, structured citations |
| Product | task success, escalation, latency, cost | Does the system help users safely? | end-to-end product change |
Two disciplines make this matrix trustworthy. First, treat evaluation as paired regression testing: run the old and new configuration on the same eval set and compare, rather than eyeballing an absolute score. Second, attach uncertainty: an LLM-judge score that moved from 0.81 to 0.83 across a few hundred noisy examples may be indistinguishable from no change, so report confidence intervals and only act on differences that clear them.
Offline is not enough: online and safety
Every metric so far is measured on a fixed eval set, offline. A RAG system that scores well there can still fail in production, so the evaluation has to extend to live behavior and safety:
- Cost and latency distributions, not just averages - the p95 tail is what users feel.
- User correction / escalation rate and successful task completion - the only end-to-end truth.
- Stale-answer rate - evidence that was fresh at indexing time but is now wrong.
- Access-control leakage - does retrieval ever surface documents a given user is not permitted to see?
- Prompt injection from retrieved content - a malicious passage in the corpus can hijack the generator; the retrieval step is now an untrusted-input channel.
- Sensitive-data exposure - personally identifiable or confidential text leaking into answers or logs.
These are not optional extras. For anything touching real users or proprietary data, the access-control and injection checks often matter more than another point of nDCG.
Conclusion
Evaluating a RAG pipeline requires a modular mindset. We cannot fix a hallucinating Generator by tweaking the Vector Database, and we cannot fix a poor search algorithm (indicated by a low Context Recall or nDCG) by changing the LLM prompt. The workflow is: build a sliced gold evaluation set first, then measure Retrieval with coverage and ranking metrics, check that Augmentation preserves the useful evidence, and judge Generation on support (with a calibrated LLM judge, not a blind one) - using frameworks like Ragas to standardize the mechanics. Pin the metric definitions and versions, attach uncertainty to every score, and validate the offline signals against online and safety outcomes. Done this way, “the answer was wrong” stops being a verdict on a black box and becomes a directed search for the one component that failed.