Introduction to AdTech: The Intelligence Layer - Machine Learning in the Millisecond
In the previous posts, we explored the plumbing of AdTech: how ad tags, redirects, pixels, and browsers coordinate to make a single impression possible. But for a data scientist or engineer, the most fascinating part isn’t just that the handshake happens - it’s the intelligence behind it.
What makes AdTech unique is not merely the use of Machine Learning, but the fact that multiple independent models must collaborate inside a single, hard real-time decision window, often under 50 milliseconds. Within that tiny slice of time, systems must reason about user intent, value, fraud, budgets, competition, and long-term objectives without the luxury of retries or human intervention.
This post explores the core Machine Learning problems that power this intelligence layer, focusing on how DSPs decide what to pay and how SSPs decide how to sell, all within the same millisecond auction.
DSP-specific ML Problems
At a high level, DSP intelligence can be divided into three layers:
- Prediction models - which estimate probabilities and values (pCTR, pCVR, CLV).
- Control and optimization systems - which decide how aggressively to act under constraints like budget, time, and competition (pacing, bid shading).
- Policy and eligibility filters - which decide whether to act at all (fraud/IVT, brand-safety, targeting and consent gates).
Together, these layers translate raw signals into a single bid. Keep the three straight: prediction answers “how valuable?”, control answers “how hard should we push?”, and policy answers “are we even allowed?”.
1. Bid Price Optimization & Probability Prediction (pCTR/pCVR)
This is the most critical DSP decision: for every bid request, how much should be bid?
- Bid too high, and the advertiser overpays.
- Bid too low, and valuable impressions are lost.
The Problem Formulation
The goal is to estimate the maximum rational value of an impression given the advertiser’s objective.
For a sales-focused campaign like Urban Hiker, with a Target CPA of ₹1,500:
First, a definitional care point, because “pCVR” is used two ways in practice. The value that matters for a bid is the per-impression conversion probability, $P(\text{conversion}\mid\text{impression})$. When a DSP runs separate click and post-click models, that decomposes as:
\[P(\text{conversion}\mid\text{impression}) = pCTR \times pCVR_{\text{post-click}}\]Suppose this product works out to a 0.5% per-impression conversion probability. With a break-even value of ₹1,500 per conversion, the maximum truthful per-impression value is:
\[0.005 \times \text{₹}1500 = \text{₹}7.50 \text{ per impression}\]Units matter enormously here, and this is the single most common place to go wrong: ₹7.50 is the expected value of one impression. Exchanges usually expect the bid CPM-denominated (per thousand impressions), so the mechanically comparable number submitted into the auction is ₹7,500 CPM. Confusing the two is a factor-of-1000 error.
₹7.50 is the highest bid that preserves non-negative expected surplus under these simplified assumptions. Bidding above it does not “guarantee a loss” on any single won auction - the realized outcome is still random - but it produces negative expected surplus.
NOTE: We are also folding several distinct quantities together for clarity - expected conversion value, the target CPA as a policy constraint, and product revenue versus contribution margin are not the same thing. Treating break-even value as ₹1,500 captures the core intuition while glossing those distinctions.
The Predictive Models
DSPs typically train two core binary classification models:
- pCTR: Probability that the ad will be clicked
- pCVR: Probability that a click will result in a conversion
Model choices
- Logistic Regression as a fast, interpretable baseline
- Gradient Boosted Machines (LightGBM / XGBoost) as a common, strong choice for tabular data
- Deep networks where embeddings of high-cardinality features (user, publisher, creative) pay off
Feature space
- User features (pseudonymous behavioral signals and segments - not anonymous; they remain linkable to a browser or ID)
- Contextual features (publisher, page category)
- Technical features (device, OS, geo)
Key challenge Clicks and conversions are rare events, requiring careful handling of class imbalance and extreme sparsity.
The Optimization Layer: Bid Shading
Modern exchanges mostly run first-price auctions. Bidding the full value would frequently overpay, so the DSP submits a shaded bid below its true value $v(x)$.
It is tempting to describe shading as “predict the clearing price and bid a hair above it,” and a naive version does exactly that. But shading is really an optimization under uncertainty, not a point prediction. The bidder wants the bid that maximizes expected surplus, trading off the chance of winning against the price paid:
\[b^\star(x) = \arg\max_b\; P(\text{win}\mid b, x)\,\big[v(x) - b\big]\]The win-probability curve $P(\text{win}\mid b,x)$ is the hidden object here, and it depends on competition, the (unseen) floor, time of day, and channel - and it drifts as everyone else re-shades. The bid must also stay eligible and respect floors and deals. Estimating that win/cost curve from censored auction feedback is exactly the subject of our bid-landscaping deep dive; here it is enough to see that a shaded bid (say ₹4.50 of per-impression value instead of ₹7.50) comes out of this trade-off, not a lookup.
This is the first place where prediction feeds directly into decision-making.
2. Audience Extension and Lookalike Modeling
Most advertisers start with a small, high-quality seed audience. The DSP’s task is to find the next best users at scale.
The Problem Formulation
This is a binary classification task:
- Positive class: Seed users (onboarded via hashed identifiers through onboarding partners). Hashing is pseudonymization, not anonymization - a hashed email is still a stable identifier that can be matched, so it stays firmly inside consent and purpose-limitation obligations.
- Negative class: Sampled internet users treated as (noisy) negatives.
The model nominally learns what distinguishes high-value users from the general population - but seed-versus-random is a leaky target, and it is worth naming what can go wrong:
- It can learn the wrong thing. The classifier may separate seed from random by data source, activity level, or consent state rather than genuine product affinity - artifacts, not signal.
- Calibration and lift, not just ranking. A high propensity score is not incremental value; the useful question is whether targeting these users causes more conversions than not, which needs a holdout.
- Proxy discrimination. Behavioral features can proxy for protected attributes, so lookalike expansion needs auditing for sensitive-segment leakage.
- Feedback loops. Because we only observe outcomes for users we actually bid on, the labels are selectively observed, and naive retraining reinforces whoever the model already favored.
Scoring the Universe
Thousands of behavioral, contextual, and temporal features are used to produce a propensity score for each reachable user.
Users are then ranked and bucketed into tiers such as:
- Top 1% (performance-focused campaigns)
- Top 10% (upper-funnel reach)
In practice, DSPs must also guard against feedback loops, where models repeatedly target the same profiles and reinforce existing bias.
3. Customer Lifetime Value (CLV) Prediction
Sophisticated advertisers realize not all conversions are equal. Acquiring a high-value segment customer who will buy premium gear repeatedly is worth a higher initial bid than a one-time discount shopper, even if their first purchase looks identical.
The ML Approach
Building a CLV model is often framed as a regression problem where the target is the total value a customer generates over a fixed future horizon (e.g. 12 months). “Often,” not “simply,” because the honest version is harder than plain revenue regression:
- Horizon and margin. Fix the prediction horizon explicitly, and predict contribution margin, not gross revenue - a customer who only buys deep-discount items can have high revenue and negative margin.
- Censoring. Most customers have incomplete histories (they have not finished their 12 months), so naive training on completed customers is selection-biased; survival/repeat-purchase or churn models handle the censoring.
- Selection from advertising itself. Advertising changes who becomes observable as a customer, which biases the training population.
- Uncertainty. A CLV point estimate without a spread is dangerous input to an aggressive bid.
A common feature scaffold is the RFM Framework: Recency (days since last purchase), Frequency (purchase count in an early window), and Monetary Value (early transaction value).
- DSP Action: If the CLV model predicts a high potential value (e.g. ₹12,000 with a stated confidence range), the bidding logic can justify a more aggressive bid to acquire that customer, even when short-term pCVR is low.
- Data-flow constraint: CLV is usually built on the advertiser’s first-party data, so it may enter DSP bidding only through permitted, purpose-limited data flows - not as a free-floating feature.
This connects long-term value to real-time bidding decisions.
4. Budget Pacing: The PID Controller
Spending a ₹3,00,000 monthly budget smoothly is not a simple linear task. Traffic varies by hour, day, season, and event. If user traffic surges on weekends and dips on Tuesday mornings, a smart algorithm must adapt to these fluctuations.
Step 1: Forecasting
The DSP uses time-series models (Prophet, ARIMA etc.) to analyze historical data and predict impression volume and competition levels. This creates an “ideal spending curve” for the month.
Step 2: Control via PID
Prophet/ARIMA-plus-PID is one reasonable architecture, not the standard recipe. Real pacing systems also use allocation optimization, model-predictive control, simple throttling (dropping a fraction of bid requests), dual-variable / shadow-price methods, or bandit and reinforcement-learning approaches. PID is popular for the same reason it shows up in thermostats: it is stable, interpretable, and debuggable under latency constraints. It maintains the “level” of spend by acting on an error term:
- Proportional (P): Reacts to the current error (e.g., “We’re behind, bid 5% higher”).
- Integral (I): Corrects for persistent, long-term drift from the curve (and needs anti-windup so a saturated actuator doesn’t accumulate a huge correction).
- Derivative (D): Responds to the rate of change to damp oscillation. In practice the derivative term is noise-sensitive and is often filtered or dropped; it damps overshoot, but it does not literally “predict” future overspend.
The controller continuously adjusts a bid multiplier (the actuator), thousands of times per minute, against a setpoint defined by the ideal spend curve - with the multiplier clamped to a sane range so control saturation and delayed spend feedback don’t send it wild.
5. Fraud Detection: Invalid Traffic (IVT)
At bid time, a DSP wants to filter obvious invalid traffic early - no optimization matters if the traffic is fake. But it is worth being precise: IVT is not caught only, or first, by the DSP. It is a multi-party, multi-stage effort. Exchanges, SSPs, and third-party verification vendors all filter, and much detection happens after the impression, feeding billing adjustments rather than a real-time drop. The stages use different signals because they have different information:
- Pre-bid (what fits in ~a millisecond): cheap heuristics on the bid request - datacenter IP ranges, suspicious user-agent / “headless” strings, implausible request rates for an ID. These are hints, not proof: legitimate traffic does come through cloud IPs and headless browsers (previews, accessibility tools), so pre-bid filters are tuned to avoid over-blocking.
- Post-bid / creative verification: once a creative is involved, vendors check for auto-redirects, malware, and hidden/stacked ads.
- Post-impression behavioral detection: signals like mouse-movement geometry, dwell time, and interaction patterns live here, not in the bid request - the browser has not rendered anything yet at bid time, so those features simply do not exist to a pre-bid model.
- Billing reconciliation: confirmed IVT is deducted after the fact.
For the modeling itself, unsupervised anomaly detection (an Isolation Forest is one option among many - autoencoders, clustering, density methods) flags “few and different” requests such as an ID requesting 150 ads a minute. Supervised classifiers (e.g., LightGBM) trained on labels from verification partners assign a “pBot” score. Two cautions: those labels are delayed and noisy and encode each vendor’s policy, and fraud is adversarial - filters that work today are probed and evaded tomorrow. And because a false positive discards real inventory (lost revenue) while a false negative pays for a bot, the threshold is an economic choice, not just an accuracy one.
Conclusion: The Unified Intelligence
These models do not operate in silos. In a single bid window (often quoted as ~50 ms, though the real deadline varies by hop and channel):
- The Fraud/IVT filter drops an obviously invalid request.
- The Lookalike Model flags the user as high-potential.
- The Budget Pacer applies a multiplier because spend is lagging.
- The pCVR Model calculates the probability of a sale.
- The Bid Shader turns value into a final, optimized price.
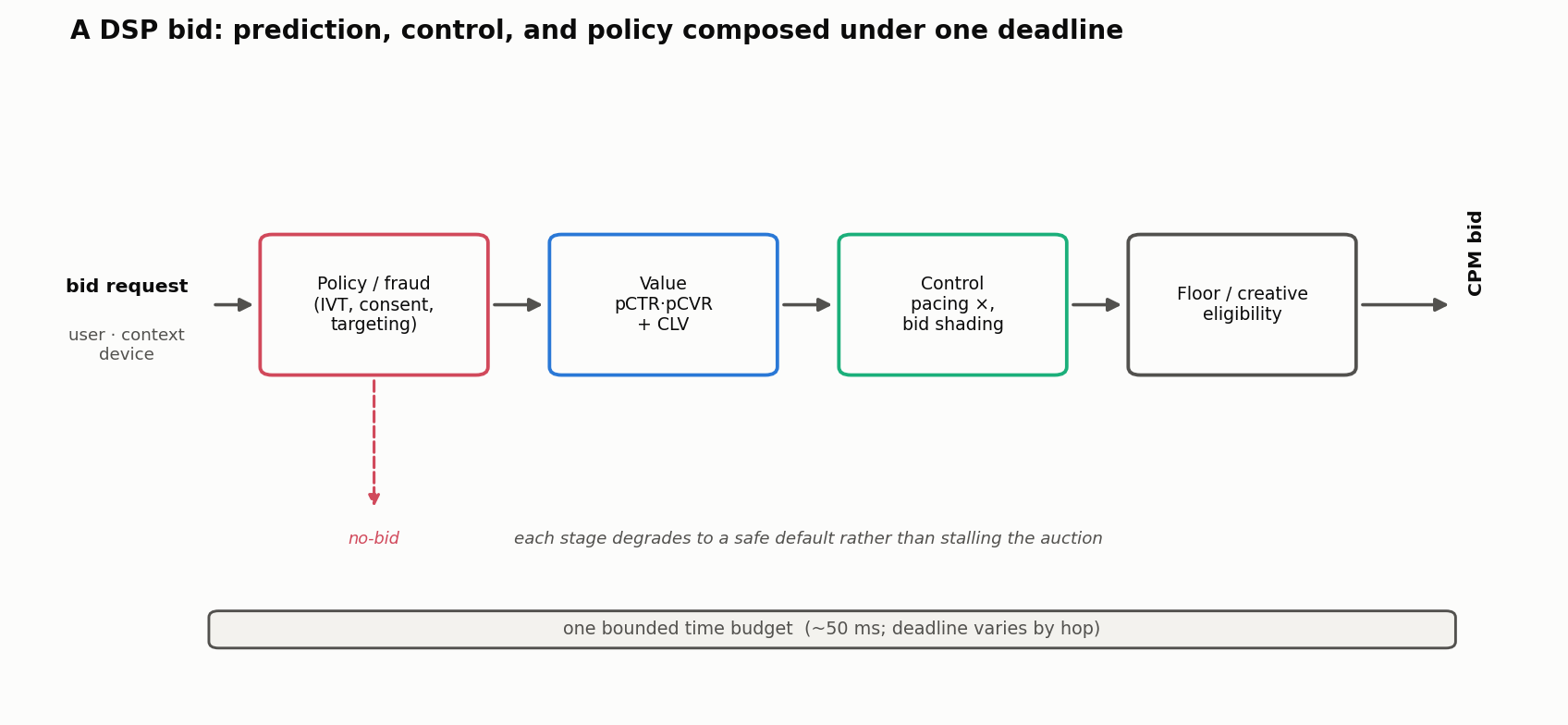
The challenge is not any single model - but orchestrating them into one coherent decision under time pressure. That orchestration is really an online serving system, and it is worth seeing the stages as a latency budget with fallbacks, because a model that misses its deadline must degrade gracefully rather than stall the auction:
| Stage | Online / offline | Output | Failure fallback |
|---|---|---|---|
| Eligibility + consent | online | allowed campaigns, feature gates | contextual bid / no-bid |
| Feature retrieval | online | bounded feature vector | cached values / defaults |
| Value model (pCTR·pCVR, CLV) | online | calibrated value | simpler baseline model |
| Pacing / control | online | bid multiplier, shadow price | conservative cap |
| Market model (shading) | online | win/cost response | last cached curve |
| Policy / creative / floor checks | online | eligible bid | no-bid |
| Training + calibration | offline / streaming | versioned model artifacts | last-known-good version |
Crucially, not every system gets the same 50 ms - the consent check gates whether later calls happen at all, and a slow feature store can starve the value model, so each stage carries its own deadline and its own safe default.
This real-time intelligence is the reason AdTech is one of the most demanding and innovative fields in modern engineering.
SSP-specific ML Problems
In our previous deep dive into the DSP’s “brain,” we looked at how advertisers use machine learning to buy the right impression at the right price. However, the other side of the transaction is equally sophisticated. While a DSP uses ML to buy effectively, a Supply-Side Platform (SSP) uses it to sell a publisher’s ad inventory for the highest possible price, ensuring every ad slot reaches its maximum revenue potential.
For an SSP, the core objective is Yield Optimization: maximizing total revenue across all impressions. This involves solving several high-stakes engineering and data science challenges in real-time.
1. Yield Decisioning and Routing
This is the central nervous system of an SSP. For every single ad request, the platform must decide how to sell it to generate the most money for the publisher. It is not always as simple as running a single auction: the SSP must navigate dozens of demand sources, including DSPs, ad exchanges, and ad networks. Google’s platform calls its version of this “Dynamic Allocation,” but that is product-specific terminology; the generic function is yield decisioning.
A common misconception is worth clearing up first. Most auction bids arrive already CPM-denominated over OpenRTB, so the SSP usually does not need to predict a buyer’s pCTR/pCVR to convert their bid into eCPM at auction time - the buyer already did that math to produce their bid. Seller-side prediction is aimed at different targets:
- The Problem: Decide which demand path is likely to pay the most and is worth calling at all, and whether a standing direct deal (like the ones from Post 2) beats the open auction.
- ML Approach: predict what the seller doesn’t already know. Useful seller-side models estimate a partner’s response probability (will they bid, and not time out?), the distribution of bids/net revenue a path tends to return, and timeout risk - then route to maximize expected net revenue. The rare case where converting CPC/CPA to eCPM genuinely applies is legacy ad-network demand that reports on a performance basis, not a clean CPM auction bid.
- Model Choice: Gradient Boosted Machines (LightGBM, XGBoost) are a strong, common choice for this tabular problem.
- Features: The models use a rich set of data points:
- User Features: Geographic location (country, city), device type, and operating system.
- Publisher Features: The specific website/app (e.g., The Times of India vs. a niche blog), the ad unit size, and the ad’s position on the page.
- Temporal Features: Day of the week and hour of the day, as prices often spike during peak browsing times.
- Historical Demand Partner Performance: How much a specific partner has historically paid, and how often it responds in time, for similar inventory.
- Real-Time Action: Upon receiving a request, the SSP generates these features, predicts which paths are worth calling and what they will net, and routes the request to maximize the publisher’s expected net revenue - not merely the highest nominal bid.
2. Floor Price Optimization
A floor price is the minimum amount a publisher is willing to accept for showing an ad. Setting it correctly is a high-wire balancing act between certainty and upside.
The Problem: Certainty vs. Ambition
Consider a single ad slot on a premium news site.
- If the floor price is set at ₹20, the slot will almost always be filled - but often cheaply.
- If the floor is set at ₹100, the publisher might earn more per impression, but many auctions will fail, resulting in no ad shown at all.
A missed impression earns ₹0, which is worse than a low-paying one. (That itself is a simplifying assumption: if a passback or house ad recovers some value from unfilled slots, failed auctions earn a little more than zero, which pulls optimal floors down.)
So the real question is not:
“What is the highest price I can ask for?”
but:
“At what minimum price does this impression maximize expected revenue?”
The ML Framing: Predicting Bidder Behavior
To answer that, SSPs don’t try to predict a single winning bid. Instead, they model the entire distribution of bids likely to appear for a given impression.
For a specific opportunity (user, page, time, device), the model asks:
- What bids are likely to show up?
- How many bidders will participate?
- How does demand vary under similar conditions?
This is known as bid distribution forecasting.
Predictive Modeling: Estimating the Bid Curve
Using historical auction data (for ad-impressions), SSPs train models to estimate probabilities such as:
- P(bid ≥ ₹30)
- P(bid ≥ ₹50)
- P(bid ≥ ₹70)
Instead of predicting the winning bid, SSPs reframe the problem as:
“Given this context, will at least one bidder bid above X?”
That is a binary classification problem.
For each threshold (₹30, ₹50, ₹70), we can generate labels:
| Threshold | Label |
|---|---|
| ₹30 | 1 (yes, bids ≥ ₹30 existed) |
| ₹50 | 1 |
| ₹70 | 0 |
Now repeat this across millions of auctions.
These probabilities implicitly capture:
- Demand intensity
- Advertiser competition
- Time-of-day effects
- Geo and device differences
Instead of guessing, the SSP now has a probabilistic view of demand.
One consistency requirement matters here: the predicted probabilities must be monotone - $P(\text{bid} \ge 50)$ can never exceed $P(\text{bid} \ge 30)$, because both are points on a single survival curve of the highest bid. Independently trained per-threshold classifiers do not guarantee this, so production systems either enforce it (isotonic constraints across thresholds) or model the full bid distribution directly. Training and calibrating exactly these monotone threshold classifiers is the subject of the dedicated floor-price optimization deep dive; it is the seller-side mirror of the censored win-curve estimation problem in our bid-landscaping deep dive.
Turning Prediction into a Decision: Expected Revenue
Once the bid distribution is estimated, the optimization step is straightforward.
For each candidate floor price, the SSP computes:
Expected Revenue = Floor Price × Probability(at least one bid ≥ Floor Price)
Expected Revenue Derivation
One simplifying assumption first, because the formula is only honest with it stated: assume every successful sale clears at exactly the floor $F$ (all prices here are per impression). That is exact for a posted, take-it-or-leave-it price, and nearly exact when demand is thin - a single serious bidder clearing the floor. In a competitive auction the winner often pays more than the floor, so this formula is a lower bound on revenue - we will complete the picture below.
Let $p = P(\text{at least one bid} \ge F)$. Then:
- With probability $p$, revenue = $F$ (by the assumption above)
- With probability $(1 - p)$, revenue = $0$
So the expected revenue is:
\[E[R] = (F \times p) + \big(0 \times (1 - p)\big) = F \times p\]For example:
- Floor ₹30 × 90% chance → ₹27 expected revenue
- Floor ₹50 × 60% chance → ₹30 expected revenue
- Floor ₹70 × 30% chance → ₹21 expected revenue
Even though ₹70 is higher, it produces less expected revenue because too many auctions fail.
Under this simplified model, the best of the three candidate floors is ₹50 - not because it’s high, but because it balances price and fill.
The Full Auction Picture
In a real second-price auction, revenue is $\max(B_2, F)$ if $B_1 \ge F$ and zero otherwise, where $B_1$ and $B_2$ are the top two bids (take $B_2 = 0$ when fewer than two bids arrive). The exact objective is:
\[E[R(F)] = \underbrace{E\big[B_2 \cdot \mathbb{1}\{B_2 \ge F\}\big]}_{\text{floor didn't bind}} + \underbrace{F \cdot P(B_2 < F \le B_1)}_{\text{floor set the price}}\]The intuition: the floor only earns its keep when it lands between the top two bids - there it lifts the price from $B_2$ up to $F$. Below both bids it changes nothing; above both it kills the auction.
Writing $S_1(t) = P(B_1 \ge t)$ and $S_2(t) = P(B_2 \ge t)$ for the survival curves of the top two bids, the same objective rearranges into a more revealing form:
\[E[R(F)] = \underbrace{F \cdot S_1(F)}_{\text{the simple model}} \; + \; \underbrace{\int_F^\infty S_2(t)\, dt}_{\text{what it omits}}\]The simple model is the first term; the second term - the expected runner-up value above the floor - is exactly what it throws away. Two consequences follow:
- The bias. Because $F \times p$ credits a filled auction with only $F$ even when the runner-up bid would have cleared higher anyway, it systematically undervalues low floors - and optimizing it tends to pick floors that are too high.
- The modeling requirement. The threshold classifiers above estimate $S_1$, which is all the simple model needs. The exact optimizer also needs $S_2$ - so production systems train the same thresholds on the second-highest bid as well, or simulate clearing revenue directly from the predicted bid distribution. $F \times p$ is the teaching version.
What about first-price? The post noted earlier that modern exchanges mostly run first-price auctions - and there the story inverts. The winner pays their own bid, so revenue is $B_1 \cdot \mathbb{1}\{B_1 \ge F\}$, and for a fixed bid distribution, raising the floor can only reject sales - it never raises a price. A first-price floor creates value only by changing bidder behavior: bidders shade less aggressively when floors are higher. Its true objective is policy-dependent, $E\big[B_1(F) \cdot \mathbb{1}\{B_1(F) \ge F\}\big]$, where the top bid $B_1(F)$ itself moves with the floor - which is why the behavior-shift caveat below is not a footnote but the entire mechanism.
Real-time Action: Floors Adapt to Context
This calculation isn’t static.
The same ad slot behaves very differently depending on context:
- A user in Mumbai on a Saturday night
- A user in a Tier-2 city on a Tuesday morning
- A sports final vs. a routine news article
The SSP continuously recomputes floor prices in real time using:
- Fresh auction outcomes
- Time-based patterns
- Demand shifts from advertisers
As a result, floor prices become dynamic, not fixed numbers.
One caveat worth respecting: floors trained on historical bids change bidder behavior once deployed - first-price shading responds directly to the floors it sees - so the bid distribution drifts under the new policy, and the models must be re-fit on data collected after the change. In second-price auctions this drift is a nuisance to correct for; in first-price it is the point - as the objective above showed, the response of $B_1(F)$ to the floor is the only reason a first-price floor earns anything at all.
Why this Matters for Publishers
Floor price optimization is one of the most leverage-heavy decisions an SSP makes:
- Small improvements compound across billions of impressions
- Overly aggressive floors quietly destroy revenue
- Conservative floors systematically under-monetize premium inventory
The ML system’s job is not to be optimistic or pessimistic - but calibrated.
3. Ad Quality and Brand Safety Control
Publishers are protective of their brand and user experience. They rely on the SSP to block malicious, inappropriate, or low-quality ads because unchecked low-quality ads degrade user trust and reduce long-term inventory value.
- The Problem: The SSP must automatically scan and classify millions of ad creatives in real-time to filter out malware, phishing, adult content, and auto-redirects.
- ML Approach: Multi-Modal Classification: This complex problem involves analyzing multiple components of an ad.
- Image Recognition (Computer Vision): Convolutional Neural Networks (CNNs) scan ad images for nudity, violence, or brand safety violations.
- Natural Language Processing (NLP): Text is analyzed to flag sensitive keywords or misleading phrases like “Click here for a free iPhone”.
- URL/Domain Analysis: Landing page URLs are checked against blocklists of malicious domains and suspicious patterns.
- Behavioural Analysis: Models detect JavaScript within an ad that exhibits bot-like behavior, such as trying to hijack the browser.
- Real-Time Action: When a DSP wins an auction, the SSP performs a final scan. If the creative is flagged as unsafe, the SSP refuses to serve it and often penalizes the DSP.
4. Demand and Revenue Forecasting
Publishers require predictable revenue streams for financial planning.
- The Problem: Based on historical data and market trends, how much ad revenue can a publisher expect next week or next month?
- ML Approach:
- Time-Series Forecasting: The SSP uses models like ARIMA/Prophet/TFT etc. to capture complex seasonality, such as traffic spikes during holidays like Diwali or weekend vs. weekday patterns.
- Features: Forecasts can be based on useful features given below:
- historical revenue
- impression volume
- eCPM trends
- seasonal spikes (e.g., Diwali, sports events)
- Action: These forecasts help publishers plan their finances and allow SSP account managers to provide data-driven growth advice. They also serve as critical inputs for floor price optimization models.
Reading the models as ledgers
The roadmap’s privacy spine becomes concrete when we ask, of each model, not “how accurate is it?” but “whose interest does it serve, and who pays when it is wrong?” A compact ledger:
| Model | Optimizes whose objective | Label = truth from | Who bears a wrong call | Selectively observed? |
|---|---|---|---|---|
| pCTR / pCVR | Advertiser’s cost efficiency | Logged clicks/conversions | Advertiser (wasted spend) | Yes - only for impressions won |
| Lookalike | Advertiser’s reach | Seed vs. sampled users | Users mis-segmented; advertiser | Yes - outcomes seen only for bid-on users |
| CLV | Advertiser’s acquisition value | Advertiser first-party history | Advertiser; censored customers | Yes - advertising shapes who is observed |
| Fraud / IVT | Advertiser + market integrity | Delayed vendor labels | Publisher (false positive) / advertiser (false negative) | Yes - and adversarially gamed |
| Floor / yield | Publisher revenue | Historical auction bids | Publisher (lost fill or lost price) | Yes - floors change the bids later observed |
Two patterns run down the right-hand columns. Almost every label is selectively observed - we learn outcomes only for the auctions we acted on - which is why naive retraining drifts. And the “who bears a wrong call” column is rarely the model’s operator, which is exactly why calibration and consent are not optional niceties.
Conclusion: The Two-Sided Intelligence
DSPs and SSPs solve different problems - but their intelligence collides in the same millisecond auction.
- One optimizes bids, the other yield.
- One protects budget, the other inventory value.
Together, they form the invisible decision engine of the modern internet.
In the next post, we’ll explore how this intelligence adapts to an identity-constrained, browser-divergent environment - and what replaces the stable cross-site identifier this whole machine grew up assuming. Later posts then take the deep dives this overview only gestured at: bid landscaping and floor-price optimization.