Introduction to AdTech: The Post-Cookie Frontier - Identity, Privacy, and What Comes Next
In the previous posts, we explored how an ad impression is auctioned in milliseconds and how machine learning models decide whether and how much to bid. However, every system we’ve discussed - from retargeting to lookalike modeling to budget pacing - rests on one fragile foundation:
the ability to recognize a browser or identifier across time and context.
For over a decade, third-party cookies quietly solved this problem. They allowed the ecosystem to stitch together impressions, clicks, and conversions across websites with surprising effectiveness.
That foundation is no longer something the ecosystem can take for granted. The point is not that “cookies are gone” - a tidy story that is simply false. Behavior differs by browser, mode, settings, and policy: Safari and Firefox block third-party cookies by default, whereas Google’s April 2025 Privacy Sandbox update kept Chrome on its existing user-choice approach rather than launching a new standalone deprecation prompt. The accurate framing is narrower and more durable:
Cross-site identity can no longer assume uniform third-party-cookie availability. Availability depends on browser, mode, settings, policy, storage partitioning, consent, and channel.
That single change of assumption is enough to reshape AdTech’s most profound architectural questions - not just replacing an identifier, but redefining how identity, trust, and learning work on the open internet. This post explores what stands in for cookies where they are unavailable, what becomes harder, and how the system adapts. A note before we start: where this article describes a vendor framework, it is summarizing the intended controls that product documentation claims, not independent proof that those privacy outcomes hold in practice.
1. The Identity Puzzle: Deterministic vs. Probabilistic
At its core, identity answers a question that sounds simple:
“Do these two events belong together?”
But “belong to whom?” is where the honesty lives, and it is worth being precise before going further. Identity systems rarely resolve a person. They link some weaker entity:
- one account across devices;
- one browser over time;
- several devices in a household;
- events believed to belong to one person;
- pseudonymous identifiers shared between authorized parties.
The distinction is not pedantic, because errors cut two ways. A false merge (stitching two different people into one profile) leaks one person’s behavior into another’s; a false split (failing to connect the same person) inflates reach and breaks frequency capping. Every mechanism below trades these off differently, so each example should name the entity it actually resolves.
Deterministic Matching (High Precision, Limited Reach)
Deterministic identity relies on explicit user authentication - a login event that links an identifier (email or phone) to a browser or device. If we log into a service on both our phone and laptop, the platform does not have to infer the connection - it observes that the same account authenticated on both.
That is high confidence, not omniscience. Shared accounts, recycled phone numbers, aliases, family devices, and sloppy email normalization all still create merge errors. The platform observes account and device relationships under its own policies and models; it does not literally “know” a human.
Strengths
- High accuracy for the account it resolves
- Stable across devices where the account logs in
- Well suited to measurement and attribution
Limitations
- Only works where users log in
- Concentrated among large logged-in platforms
Probabilistic Matching (High Reach, Uncertain Truth)
When deterministic signals are absent, systems fall back to probabilistic identity.
Models correlate:
- IP addresses
- Device characteristics
- Temporal usage patterns
- Behavioral similarity
and estimate a likelihood that two identifiers represent the same user or household. Two cautions travel with any such number. First, a bare confidence figure is meaningless without a stated calibration, an evaluation ground truth, and its performance per segment - so this article deliberately avoids quoting invented percentages. Second, the very inputs that make probabilistic matching work (IP, device characteristics, behavior) are the same signals that constitute browser fingerprinting, so “high reach” is not an unqualified good: it can mean expanded surveillance of people who never logged in or opted in. In an identity-constrained world, confidence replaces certainty - and that confidence must itself be measured, not asserted.
2. Login-Based Identifiers: Hashed Emails and UID2
Where cross-site cookies are unavailable, the industry leans on user-provided identifiers - typically an email or phone number entered during login. It is common to hear these described as “knowingly shared for advertising,” but that framing only holds if the product experience and consent flow actually established that purpose; a login is not automatically ad consent.
Why Hashed Emails Are Used
A hashed email (e.g., SHA-256) lets two independent systems derive the same identifier from the same email without exchanging the raw address.
Key properties, stated carefully:
- The hash is deterministic (same input → same output).
- The function is one-way in the cryptographic sense: the hash cannot be inverted algebraically.
- No cleartext email moves through the bidstream.
Here is the crucial correction to a common myth: a hashed email is not anonymous. It is a stable pseudonymous identifier, and it is guessable. The space of real email addresses is small and structured, so anyone can normalize and hash a dictionary of likely emails and match them against the hashes they see - no “reversing” required. So replace “the email cannot be reconstructed” with the honest version: the hash is not decrypted, but likely emails can be normalized, hashed, and compared, and the privacy of the scheme depends on governance and the full protocol, not on the hash itself. Hashing by itself supplies no consent, purpose limitation, deletion, expiry, or access control.
Raw hashed emails therefore have real limitations as an identity system:
- They are static (the identifier never changes).
- They lack built-in expiry.
- They offer no standardized way to enforce user consent or revocation.
This is the gap UID2 tries to close - with governance, not cryptographic magic.
Unified ID 2.0 (UID2)
UID2 formalizes the hashed-email idea into a governed identity framework with lifecycle controls, rather than a bare identifier. Whether that governance delivers privacy in practice is a question of enforcement and trust, not a property we can read off the design - so this section describes the mechanism and its threat model rather than awarding it a “privacy-aware” label.
At a high level, UID2 separates identity generation from identity usage.
How UID2 Works (Conceptually)
- A user logs into a participating publisher using an email address.
- With explicit consent, that email is transformed into a UID2 token.
- Instead of sharing a static hash, the system issues:
- An encrypted token
- With a limited lifetime
- That can be rotated or revoked
This token - not the email or its hash - is what enters the advertising workflow.
Why this Matters
UID2 adds lifecycle machinery that raw hashes lack:
- Encrypted advertising tokens, not static hashes. The token that travels in the bidstream is encrypted and short-lived, so a passive observer who intercepts one cannot reuse it indefinitely. This is not a claim that the underlying identity is unrecoverable: an authorized DSP decrypts the token back into a raw UID2 in order to use it (see the official DSP integration guide). The protection is against unauthorized parties, not authorized ones.
- Rotation and expiry. Tokens refresh and expire, which limits passive long-term cross-site tracking. Note that token expiry is not the same as deletion of the raw UID2 or of any data a receiver already derived from it.
- Opt-out propagation. Users can opt out, and authorized participants are required to honor it. “Required to” is a governance and enforcement property, with real-world latency between opt-out and effect - not an instantaneous guarantee.
In other words, UID2 introduces lifecycle management to identity - something cookies and raw hashes never had. What it does not do is make identity invisible to the parties authorized to use it.
A threat model, not a privacy verdict
Whether an identity mechanism is “private” depends entirely on whom it protects against. Spelling that out for UID2 is more honest than any single label:
| Protected from… | Meaningfully? |
|---|---|
| Passive network observer | Yes - token is encrypted and rotates |
| Unauthorized participant (no decryption keys) | Largely - cannot turn the token into a raw UID2 |
| Authorized DSP | No - it decrypts to the raw UID2 by design |
| Publisher collecting the login | No - it holds the original email |
| UID2 operator | No - it derives the raw identifier |
| Data breach at an authorized party | No - depends on that party’s security |
| Compelled access (legal process) | No - governance does not stop lawful compulsion |
The pattern is the point: UID2 narrows who can recognize a user relative to open third-party cookies, but it does not remove recognition for the authorized ecosystem. That is a meaningful shift, and it is also not “anonymity.”
How UID2 Fits into the Auction Flow
From the perspective of the auction:
- The UID2 token is simply another signal attached to the bid request.
- DSPs that are authorized to decrypt or interpret UID2 can use it for:
- Frequency capping
- Measurement
- Audience targeting
- DSPs without access still operate contextually.
Crucially, UID2 does not guarantee universal reach. It only works where:
- Users are logged in
- Consent is granted
- And publishers participate
That constraint is intentional.
A Shift in Philosophy
UID2 doesn’t attempt to recreate third-party cookies one-for-one. Instead, it reflects an intended shift in how identity is treated:
- From implicit tracking toward login-gated participation
- From permanent identifiers toward time-bound tokens
- From assumed access toward governed access
Whether that intent is realized depends on enforcement, but the design direction is clear: identity moves from silent, universal observation toward participation that is scoped, revocable, and auditable in principle. That is a genuine improvement on open cross-site cookies for the people it covers - and it simultaneously concentrates identity among logged-in platforms, which is its own kind of power. Both things are true.
3. The Identity Graph: From Identifiers to Relationships
Real users don’t behave cleanly.
They:
- Use multiple emails
- Switch devices
- Clear cookies
- Move between logged-in and anonymous states
To reconcile this, platforms build identity graphs - large structures that connect identifiers into probabilistic clusters. Note that “graph” does not imply “anonymous”: a structure whose whole purpose is to link a person’s identifiers is, if anything, more identifying than any single ID.
An identity graph may link:
- Hashed emails
- Phone numbers
- Mobile advertising IDs (MAIDs)
- Device-level signals
Importantly, identity graphs don’t just store IDs - they store relationships and confidence scores. Each edge carries metadata worth interrogating rather than trusting: is the link deterministic or inferred? What is the confidence, and how was it calibrated? Who operates the graph, how long is each edge retained, and what happens on revocation? What is the harm if a given edge is wrong? A worked view of one such chain makes this concrete:
1
2
3
4
5
6
publisher login
-> normalized contact input (deterministic, but normalization can err)
-> provider-specific identifier (deterministic within that provider)
-> rotating sharing token (governed, expiring)
-> authorized DSP mapping (decrypts to a raw ID)
-> impression and conversion events (inferred joins, confidence < 1)
The links near the top are deterministic; the joins near the bottom are inferred, and a bare “high-confidence” claim on them is only as meaningful as its calibration and ground truth. In an identity-constrained world, identity becomes a graph problem, not a lookup table - and the graph is a governance object, not a neutral data structure.
4. What Breaks Without a Shared Cross-Site ID (and How Systems Adapt)
Losing a shared cross-site identifier does not break everything equally, and it is a mistake to imply every workflow fundamentally requires persistent identity. Contextual buying, aggregate measurement, publisher first-party systems, clean rooms, and experiments each degrade differently. The honest picture is a matrix of tradeoffs:
| Use case | Without a shared cross-site ID | Alternative | What stays degraded |
|---|---|---|---|
| Frequency control | Per-domain only | Publisher / account / cohort caps | Cross-publisher deduplication |
| Attribution | Fewer deterministic joins | Aggregate, modeled, experiments | User-path observability |
| Audience activation | Reduced match reach | Contextual / first-party / on-device | Portability across sites |
| Fraud detection | Fewer shared signals | Contextual / network / aggregate signals | Cross-site pattern detection |
To compensate, systems increasingly rely on:
- Stronger first-party data
- Shorter feedback loops
- Cohort-level and aggregate learning
- Contextual signals
In practice, this shifts optimization from individual users toward populations and intent clusters - trading some precision and portability for approaches that lean less on persistent identity.
5. The Future Beyond Identity: Context, Semantics, and LLMs
As third-party identity weakens, the industry’s focus is shifting from who the user is to what the user is doing right now.
This marks a deeper transition - not just identity replacement, but identity minimization. Instead of reconstructing individuals across the web, systems increasingly extract meaning from the moment itself.
From User-Centric to Moment-Centric Targeting
In an identity-rich world, targeting revolved around persistent user profiles. In a post-cookie world, those profiles are incomplete, probabilistic, or absent altogether.
The alternative is contextual understanding.
Rather than asking:
“Who is this user?”
Modern systems ask:
“What is the intent, tone, and relevance of this page or interaction?”
This is where semantic understanding becomes critical.
Semantic Contextual Intelligence
Earlier contextual targeting relied heavily on keywords - often crude and misleading.
Large Language Models enable a fundamentally richer approach:
- Page-level semantic comprehension, not just keyword matching
- Intent and sentiment detection, distinguishing concern from optimism
- Disambiguation of similar topics with different meanings
For example, an article discussing market volatility and one focused on financial resilience may share vocabulary, but represent very different user mindsets. LLM-powered semantic models can distinguish between them without knowing anything about the individual reader.
In this sense, context becomes a proxy for intent - without requiring identity. Two honest caveats keep this from being a free lunch. First, context is not automatically non-sensitive: a page about a health condition, a religious practice, or financial distress can support a sensitive inference about the reader even with no identifier attached, so “contextual” is not a synonym for “harmless.” Second, semantic relevance is not proof of incremental ad value - a model that confidently matches an ad to a page has still not shown the ad caused an outcome, which only an experiment can establish.
Where LLMs Actually Fit in the Stack
LLMs do not replace the real-time ML systems described earlier. They are too slow, too expensive, and too opaque for millisecond bidding decisions.
Instead, they operate around and above the core decision loop.
LLMs are increasingly used to:
- Enrich contextual signals before auctions occur
- Generate semantic embeddings for pages, creatives, and queries
- Assist humans in configuring and interpreting campaigns
These enriched signals then feed into the same lightweight, fast models (GBMs, linear models) that execute under strict latency constraints.
Assistive Intelligence, not Bidding Intelligence
LLMs also reduce friction on the human side of the system:
- Translating natural-language campaign goals into structured targeting rules
- Summarizing performance trends and anomalies
- Helping creative teams generate variants aligned with contextual themes
Rather than making bidding decisions themselves, LLMs help align human intent, system configuration, and machine optimization.
A Coherent Shift, not a Collection of Tools
Taken together, these changes reflect a consistent direction:
- Less reliance on persistent identity
- More emphasis on meaning, context, and intent
- Clearer separation between fast decision models and slow reasoning systems
LLMs matter in AdTech not because they replace existing ML - but because they can make context rich enough to partially offset a weaker identity signal. “Partially” and “can” are load-bearing: whether richer context actually recovers lost performance is an empirical question to be measured campaign by campaign, not a claim to assert.
6. The Privacy and Power Ledger
Before the detailed comparison, one picture captures why there is no clean winner. Plot the mechanisms on two axes - reach (the share of impressions an approach can actually resolve) and linkage confidence (how sure it is that two events belong together) - and they fall along a descending frontier. Login IDs are precise but low-reach; contextual has near-universal reach but resolves no identity at all. Third-party cookies were the historical outlier that scored high on both, which is precisely why their erosion is disruptive rather than cosmetic.
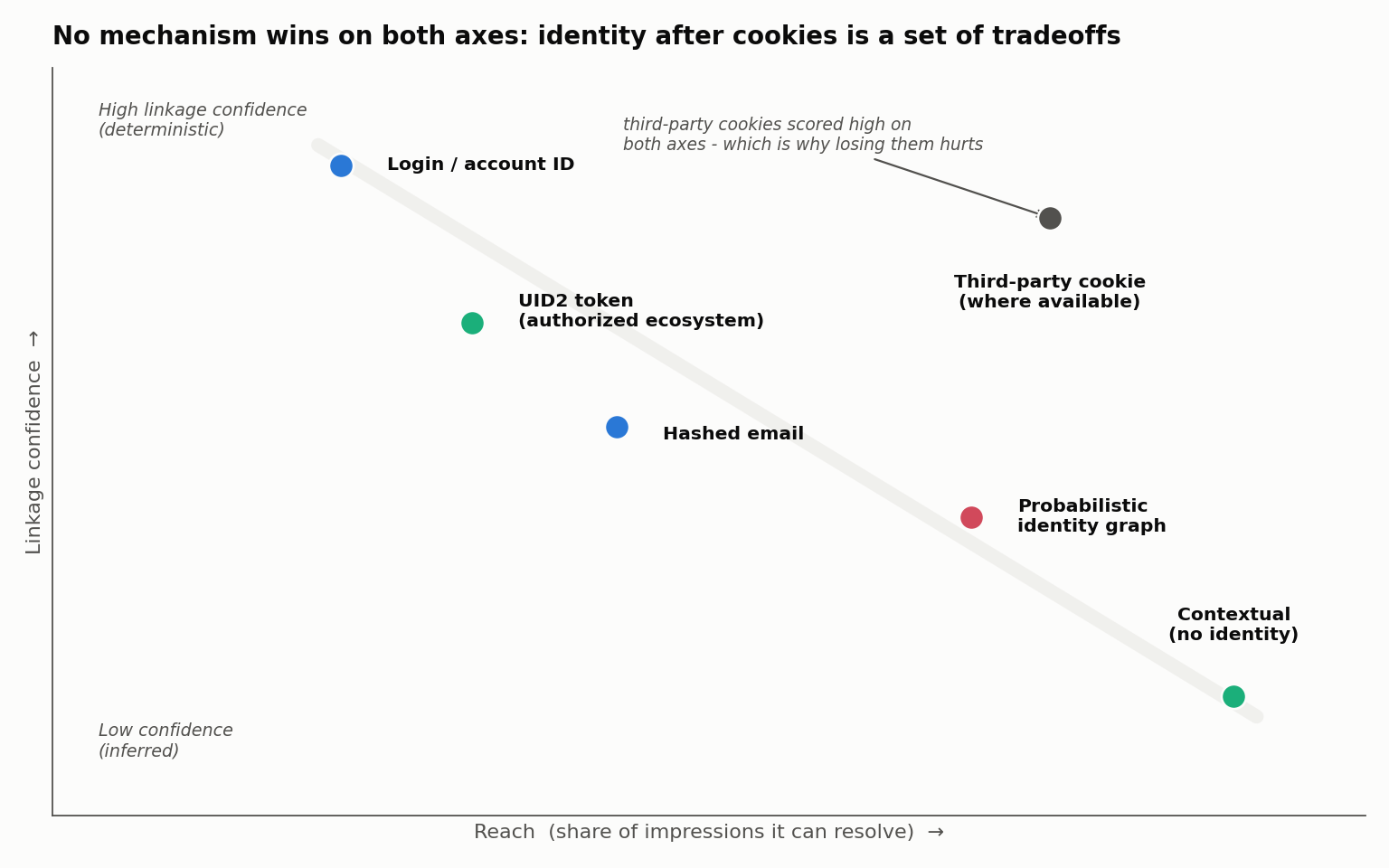
Every mechanism in this article is a different answer to the same set of questions: who can recognize whom, in which context, from what input, for which purpose, with what controls, and what residual risk remains? Laying them side by side is the most honest summary of the post-cookie landscape, because it refuses to collapse into either “tracking is dead” or “nothing changed”:
| Mechanism | Linkability scope | Trusted parties | User control | Residual risk |
|---|---|---|---|---|
| Third-party cookie | One browser across embedding sites | Browser + embedded party | Settings/consent (varies by browser) | Cross-site tracking by default |
| Login / account ID | Services tied to the account | Account provider | Account + consent controls | Platform concentration |
| Hashed contact info | Any party holding the matching input | All matching recipients | Depends on governance | Dictionary matching / linkage |
| Rotating token (UID2) | The authorized ecosystem | Publisher, operator, receivers | Opt-out protocol | Full visibility to authorized parties |
| Contextual | The page/content moment | Publisher, buyer | Less identity-dependent | Sensitive-context inference |
Read down the columns and the tradeoffs are stark: nothing here is simply “private” or simply “invasive.” Each mechanism narrows some risks while concentrating others, and the right question is never “is this private?” but “private from whom, and who is trusted instead?”
Which is also why no single technology closes the gap. Reducing exposure realistically takes three distinct levels, and confusing them is how responsibility gets misassigned:
- Individual action - browser settings, opt-outs, and identity compartmentalization reduce personal exposure but cannot fix the market.
- Responsible engineering - data minimization, retention limits, aggregation, and access control determine how much risk a system creates in the first place.
- Systemic intervention - platform rules, standards, enforcement, and regulation are the only lever for problems no individual setting can reach.
Self-defense helps, but it does not repair opaque data markets on its own - a thread later articles in this series pick up directly.
Series Conclusion: The Shape of the New Stack
Across this series, we followed an ad impression end to end:
- from browser execution,
- through real-time auctions,
- into ML-driven bidding,
- across identity stitching,
- and finally into an identity-constrained, more governed future.
What emerges is not a system in decline, but one being reshaped with intent.
The post-cookie world doesn’t eliminate personalization - it forces discipline.
Identity becomes:
- Explicit instead of implicit
- Probabilistic instead of absolute
- Governed instead of assumed
AdTech remains one of the most demanding engineering domains: massive scale, extreme latency constraints, adversarial incentives, and constant regulatory pressure. Yet that challenge is exactly what makes it fascinating. The problems are harder, the constraints tighter, and the solutions - when they work - far more elegant.
What changes is not the need for intelligence, but how carefully that intelligence must be earned: through better modeling, clearer consent, richer context, and more thoughtful system design.
This ecosystem is complex, often opaque, and easy to oversimplify, and the aim of these posts was to demystify how the pieces actually fit together. Thanks to everyone who followed the series this far; hopefully it was time well spent.
This post opens the identity, privacy, and power thread rather than closing it. Later articles go deeper into the pieces this overview only sketched: the bid-landscaping and floor-price deep dives on the modeling side, and, on the privacy side, the consent infrastructure, the data exhaust of a single page load, and a practical guide for people who still want to use the web. The stack will keep evolving, but the core questions - trust, value, and decision-making under uncertainty - are not going away. If anything, the next phase of AdTech’s evolution will be even more interesting than the last.