Probability Distribution: Log-Normal
The Log-Normal models positive multiplicative variation: median, mode, and mean, why sigma controls the skew, the CDF via the Normal, and why stock-price claims are model-dependent.
Probability distributions, a field guide (10 posts). This is Log-Normal. See the series overview for the full map.
The Question It Answers
What happens when many positive factors multiply? Where the Normal arises from adding small effects, the Log-Normal arises from multiplying them: a series of percentage changes compounding, a growth process, a quantity built from proportional steps. The defining fact is simple: if $\ln X$ is Normal, then $X$ is Log-Normal, so $X = e^Y$ with $Y \sim N(\mu, \sigma^2)$.
| Field | Content |
|---|---|
| Type | Continuous |
| Random variable | $X > 0$, a positive multiplicative quantity |
| Support | $X > 0$ |
| Parameters | $\mu, \sigma$ = mean and standard deviation of $\ln X$ (log-space; their meaning depends on the measurement units of $X$) |
| Mean | $e^{\mu + \sigma^2/2}$ |
| Variance | $(e^{\sigma^2} - 1)\, e^{2\mu + \sigma^2}$ |
| Signature | The log is Normal; the product of many positive factors |
Shape Before Formula
The Log-Normal is right-skewed and strictly positive, but how skewed depends entirely on $\sigma$: a small $\sigma$ looks almost Normal, while a large $\sigma$ stretches a long right tail. It is not “always heavily skewed.”
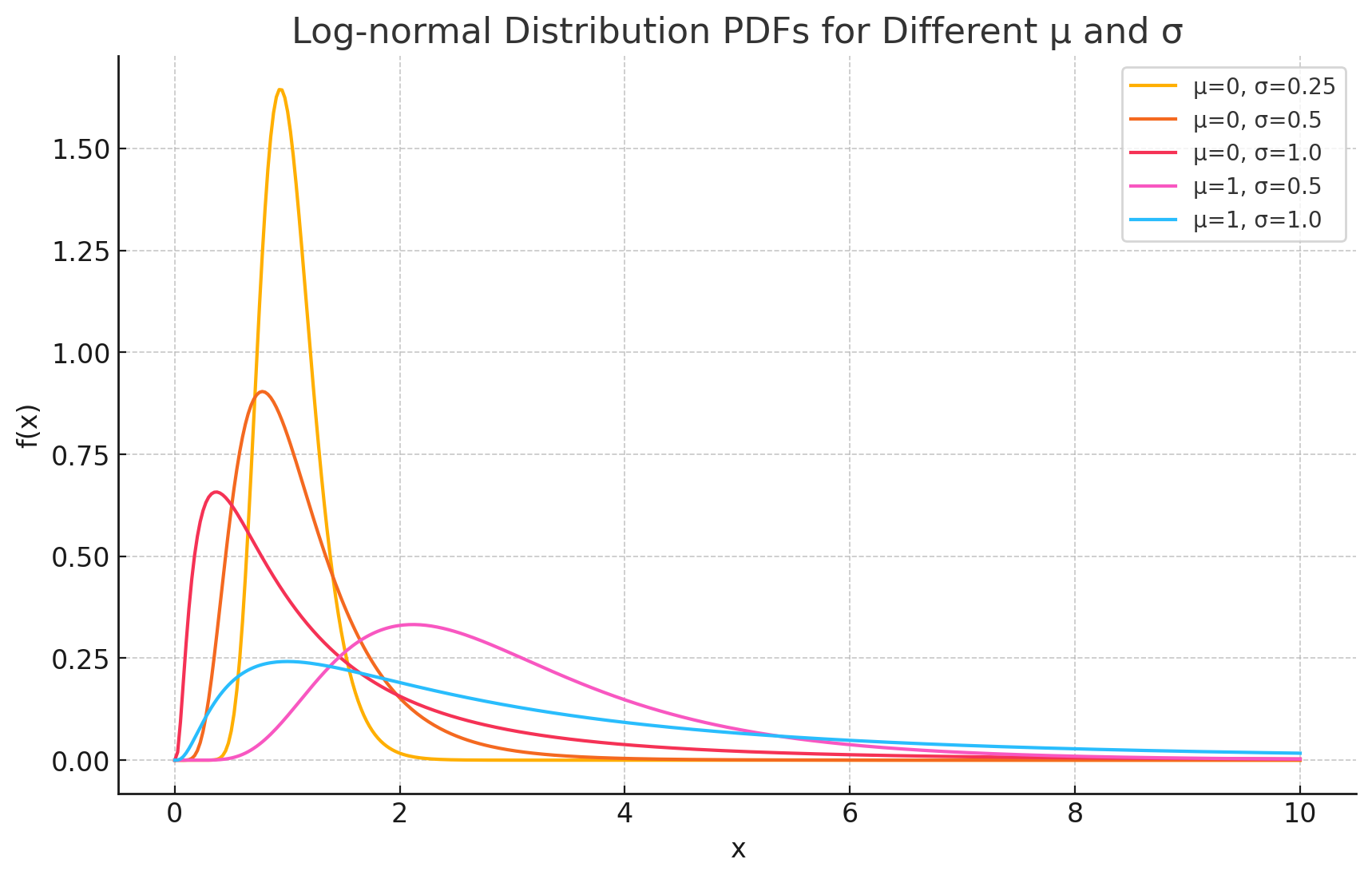
The core term measures the distance of $\ln x$ (not $x$) from $\mu$, which is what makes the logarithm Normal. The leading $1/x$ is the Jacobian of the $x = e^Y$ change of variables; it correctly conserves probability under the transformation, but it does not by itself “push the curve up for small $x$”, the actual shape comes from the full transformed density, not one factor.
Median, Mode, and Mean
This is the distribution where the three centers genuinely differ, and the gap is the lesson:
\[\operatorname{median}(X) = e^{\mu}, \qquad \operatorname{mode}(X) = e^{\mu - \sigma^2}, \qquad E[X] = e^{\mu + \sigma^2/2}.\]They always order as mode $<$ median $<$ mean, and the spread between them grows with $\sigma$. The median $e^\mu$ is the geometric mean of $X$: if we log the data, average, and exponentiate, we recover the median, not the arithmetic mean on the original scale. That is why reporting a plain average of multiplicative data (incomes, latencies) can be misleading, dragged upward by the tail.
A Worked Example: Incubation Periods
Setup. A virus has a median incubation period of 5 days, and log-day variation $\sigma = 0.5$, so $\mu = \ln 5 \approx 1.609$.
- Median $e^{\mu} = 5$ days, but the mean is $e^{\mu + \sigma^2/2} \approx 5.7$ days and the mode (most common) is $e^{\mu - \sigma^2} \approx 3.9$ days: fast onset, slow tail.
- Chance of a long incubation past 10 days uses the CDF via the Normal, $P(X > x) = 1 - \Phi!\left(\frac{\ln x - \mu}{\sigma}\right)$: here $z = (\ln 10 - 1.609)/0.5 \approx 1.39$, so $P(X > 10) \approx 0.083$.
Intuitively, multiplying many independent “delay factors” (immune response, dose, individual variation) produces exactly this shape, the multiplicative analogue of the CLT.
When It Fits, and When It Fails
| Assumes | A positive quantity built from multiplied independent factors; $\ln X$ genuinely Normal |
| Common violation | Mixtures of subpopulations, truncation, or tails heavier than Log-Normal; taking logs does not automatically make skewed data Normal (check the transformed data) |
| Closest relatives | Normal (its log); Gamma and Weibull as other positive skewed models |
Two claims to state carefully. Stock prices are Log-Normal only under a specific model (geometric Brownian motion, as in Black-Scholes), which is an assumption, not an empirical law. And quantities like web-session lengths or file sizes are often described as Log-Normal, but real data may be a mixture, truncated, or heavier-tailed, so the fit must be verified rather than assumed.
A Minimal Code Check
1
2
3
4
5
6
7
import numpy as np
from scipy.stats import lognorm
mu, sigma = np.log(5), 0.5 # scipy: shape s = sigma, scale = exp(mu)
lognorm.median(sigma, scale=np.exp(mu)) # e^mu -> 5.0
lognorm.mean(sigma, scale=np.exp(mu)) # e^(mu+sigma^2/2) -> 5.67
lognorm.sf(10, sigma, scale=np.exp(mu)) # P(X > 10 days) -> 0.083
Appendix: Deriving the Mean and Variance
If $X$ is Log-Normal then $X = e^Y$ with $Y \sim N(\mu, \sigma^2)$, so every moment $E[X^t] = E[e^{tY}]$ is the Normal moment generating function $M_Y(t) = e^{\mu t + \sigma^2 t^2/2}$ evaluated at an integer $t$. This substitution sidesteps the awkward $\ln x$ in the density: the $1/x$ factor in the Log-Normal PDF is exactly the Jacobian that maps the integral back to a Normal one.
The Mean
The mean is $M_Y(t)$ at $t = 1$:
\[E[X] = E[e^Y] = e^{\mu + \sigma^2/2}.\]This sits above the median $e^{\mu}$ by a factor $e^{\sigma^2/2}$: the right tail pulls the mean up.
The Variance
The second moment is $M_Y(t)$ at $t = 2$:
\[E[X^2] = E[e^{2Y}] = e^{2\mu + 2\sigma^2}.\]Then
\[\text{Var}(X) = E[X^2] - (E[X])^2 = e^{2\mu + 2\sigma^2} - e^{2\mu + \sigma^2} = \left(e^{\sigma^2} - 1\right)e^{2\mu + \sigma^2},\]factoring out the common $e^{2\mu + \sigma^2}$.
Where this sits in the series. Previous concept: Normal (additive variation). Next concept: Laplace (sharp-centered symmetric variation). Closest cousins: Normal (its logarithm) and Gamma/Weibull (other positive models). Series overview.