Probability Distribution: Negative Binomial
The Negative Binomial has two faces: a waiting time for the r-th success, and an overdispersed count arising from a Gamma mixture of Poisson rates.
Probability distributions, a field guide (10 posts). This is Negative Binomial. See the series overview for the full map.
The Question It Answers
The Negative Binomial wears two hats, and keeping them apart is the whole battle:
- A waiting time: how many trials (or failures) until the $r$-th success? This generalizes the Geometric, which stops at the first success ($r = 1$).
- An overdispersed count: how do we model counts whose variance exceeds their mean? Where the Poisson forces variance to equal the mean, the Negative Binomial adds a knob for extra spread.
They are the same distribution seen from two directions, but they are parameterized and used differently.
| Field | Content |
|---|---|
| Type | Discrete |
| Random variable | $X$ = trials until the $r$-th success (or $Y$ = failures before it) |
| Support | $X \in \{r, r+1, \dots\}$, equivalently $Y \in \{0, 1, 2, \dots\}$ |
| Parameters | $r$ = target number of successes (a count); $p$ = per-trial success probability |
| Mean | $r/p$ (trials) or $r(1-p)/p$ (failures) |
| Variance | $r(1-p)/p^2$, always larger than the failure-count mean |
| Signature | Waiting time for the $r$-th success; equivalently, a Gamma mixture of Poisson rates |
Two Conventions, Stated Cleanly
The total-trials version counts every attempt, $X \in \{r, r+1, \dots\}$:
\[P(X=k) = \binom{k-1}{r-1} p^r (1-p)^{k-r}.\]The last trial must be the $r$-th success, so $\binom{k-1}{r-1}$ arranges the other $r-1$ successes among the first $k-1$ trials. The failures-before-success version counts only failures, $Y = X - r \in \{0, 1, \dots\}$, which is what scipy.stats.nbinom uses:
Their means differ by the constant $r$, but they share a variance:
\[E[X]=\frac{r}{p},\quad E[Y]=\frac{r(1-p)}{p},\quad \text{Var}(X)=\text{Var}(Y)=\frac{r(1-p)}{p^2}.\]A Worked Example: Waiting for the 3rd Booking
Setup. A salesperson needs $r = 3$ booked meetings, and each call books with probability $p = 0.4$. Let $X$ be the call on which the 3rd booking arrives.
Probability it takes exactly 5 calls (so 2 failures land among the first 4):
\[P(X = 5) = \binom{4}{2}(0.4)^3(0.6)^2 = 6 \cdot 0.064 \cdot 0.36 \approx 0.138.\]On average it takes $E[X] = r/p = 7.5$ calls. As with the Geometric, the honest caveat is that a single $p$ across prospects is a modeling convenience, not a fact.
The Overdispersed-Count View
The second face is where the distribution earns its keep in practice. A Poisson count has variance equal to its mean; real count data (insects per quadrat, purchases per user, defects per batch) is often far more variable. Writing the mean as $\mu$ and a dispersion parameter $\alpha = 1/r$, the Negative Binomial gives
\[\text{Var}(Y) = \mu + \alpha \mu^2,\]which exceeds $\mu$ whenever $\alpha > 0$, and collapses back to the Poisson as $\alpha \to 0$ (that is, $r \to \infty$).
The right intuition for why is latent heterogeneity, not vague “non-independence.” Suppose each entity has its own Poisson rate, and those rates themselves vary across entities following a Gamma distribution. Mixing a Poisson over a Gamma-distributed rate produces exactly a Negative Binomial marginal count. The extra variance is the spread of the hidden rates.
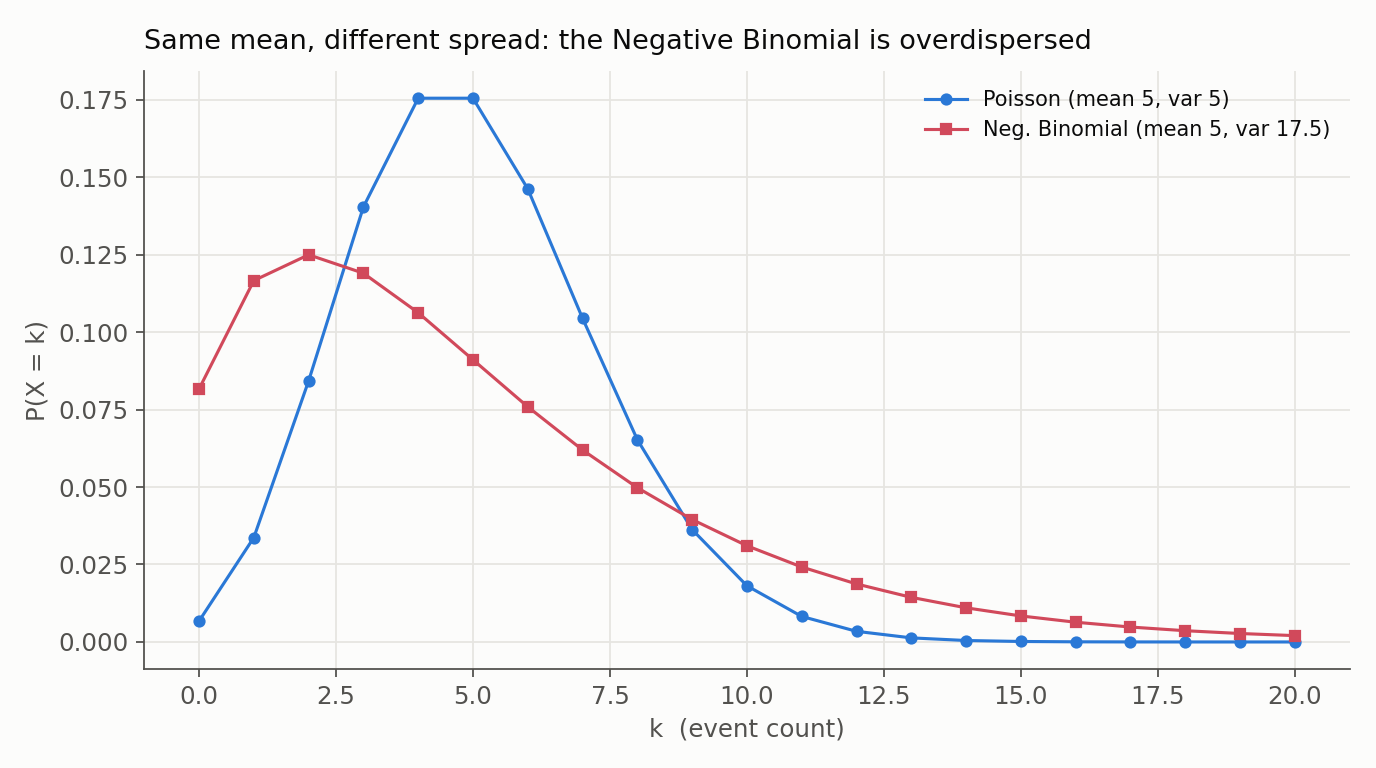
One caveat: the Negative Binomial is not a universal cure for excess zeros. If a dataset has more zeros than even an overdispersed count predicts (a separate “never happens” subpopulation), that is zero inflation, and it needs a zero-inflated or hurdle model, not just a bigger dispersion.
When It Fits, and When It Fails
| Assumes | (Waiting-time) independent trials, constant $p$; (count) Poisson events with Gamma-distributed rates |
| Common violation | Excess zeros beyond overdispersion; structural clustering in time; a dispersion that itself varies with covariates |
| Closest relatives | Geometric ($r = 1$); Poisson (the $\alpha \to 0$ limit); zero-inflated models for excess zeros |
A Minimal Code Check
1
2
3
4
5
6
7
8
9
10
11
from scipy.stats import nbinom
# scipy counts FAILURES before the r-th success: nbinom(r, p)
r, p = 3, 0.4
nbinom.pmf(2, r, p) # 2 failures = 5 total trials -> 0.138
nbinom.sf(9, r, p) # more than 9 failures (upper tail)
# Overdispersed-count parameterization: mean mu, size r; var = mu + mu^2/r
mu, size = 5.0, 2.0
p_count = size / (size + mu) # convert (mu, size) -> scipy's p
nbinom.stats(size, p_count, moments="mv") # (5.0, 17.5): var > mean
Parameterization checklist: SciPy’s nbinom(n, p) uses $n = r$ successes and counts failures; the count-model form uses a mean $\mu$ and a size/dispersion $r$ (smaller $r$ means more overdispersion) with $p = r/(r+\mu)$. R and statsmodels often report dispersion as $\alpha = 1/r$. Confirm which before trusting a fitted parameter.
Appendix: Deriving the Mean and Variance
In the waiting-time view, reaching the $r$-th success means completing $r$ independent Geometric waits, one per success: $X = X_1 + \dots + X_r$, where each $X_i$ counts the trials for one more success and is Geometric($p$). Both moments then reduce to the Geometric’s, whose derivations are in the Geometric appendix.
The Mean
Each wait has $E[X_i] = 1/p$. Expectation is linear, so
\[E[X] = \sum_{i=1}^{r} E[X_i] = r\cdot\frac{1}{p} = \frac{r}{p}.\]The Variance
The $r$ waits are independent, so their variances add. Each has $\text{Var}(X_i) = (1-p)/p^2$, giving
\[\text{Var}(X) = \sum_{i=1}^{r}\text{Var}(X_i) = r\cdot\frac{1-p}{p^2} = \frac{r(1-p)}{p^2}.\]At $r = 1$ these collapse to the Geometric’s moments, as they must.
As for the name: the “negative” has nothing to do with negative counts. The PMF terms are exactly the coefficients of the negative-binomial series expansion of $(1-q)^{-r}$, which is where the distribution takes its name.
Where this sits in the series. Previous concept: Geometric (the first success). Next concept: Poisson (event counts in continuous time). Closest cousin: Poisson again, as the no-overdispersion limit. Series overview.