Probability Distribution: Normal (Gaussian)
The Normal distribution models additive variation around a center: the 68-95-99.7 rule, z-scores, what the CLT does and does not say, and when a bell curve is the wrong model.
Probability distributions, a field guide (10 posts). This is Normal. See the series overview for the full map.
The Question It Answers
How does symmetric, additive variation spread around a center? When many small, independent effects add up, the total tends to pile symmetrically around a mean, with large deviations rare in either direction. That is the Normal (Gaussian) distribution. It is tempting to call it “the bell curve of nature,” but that overreaches: plenty of real measurements are skewed, bounded, multimodal, or mixtures of subpopulations. Normal is a model for additive variation, not a law that data must obey.
| Field | Content |
|---|---|
| Type | Continuous |
| Random variable | $X$ = a real-valued measurement |
| Support | $-\infty < X < \infty$ |
| Parameters | $\mu$ = mean/center (units of $X$); $\sigma$ = standard deviation (units of $X$; variance $\sigma^2$ has squared units) |
| Mean | $\mu$ |
| Variance | $\sigma^2$ |
| Signature | Symmetric bell; the limiting shape of standardized sums |
Shape Before Formula
The two parameters do independent jobs: $\mu$ slides the center left or right, and $\sigma$ sets the width without moving the center.
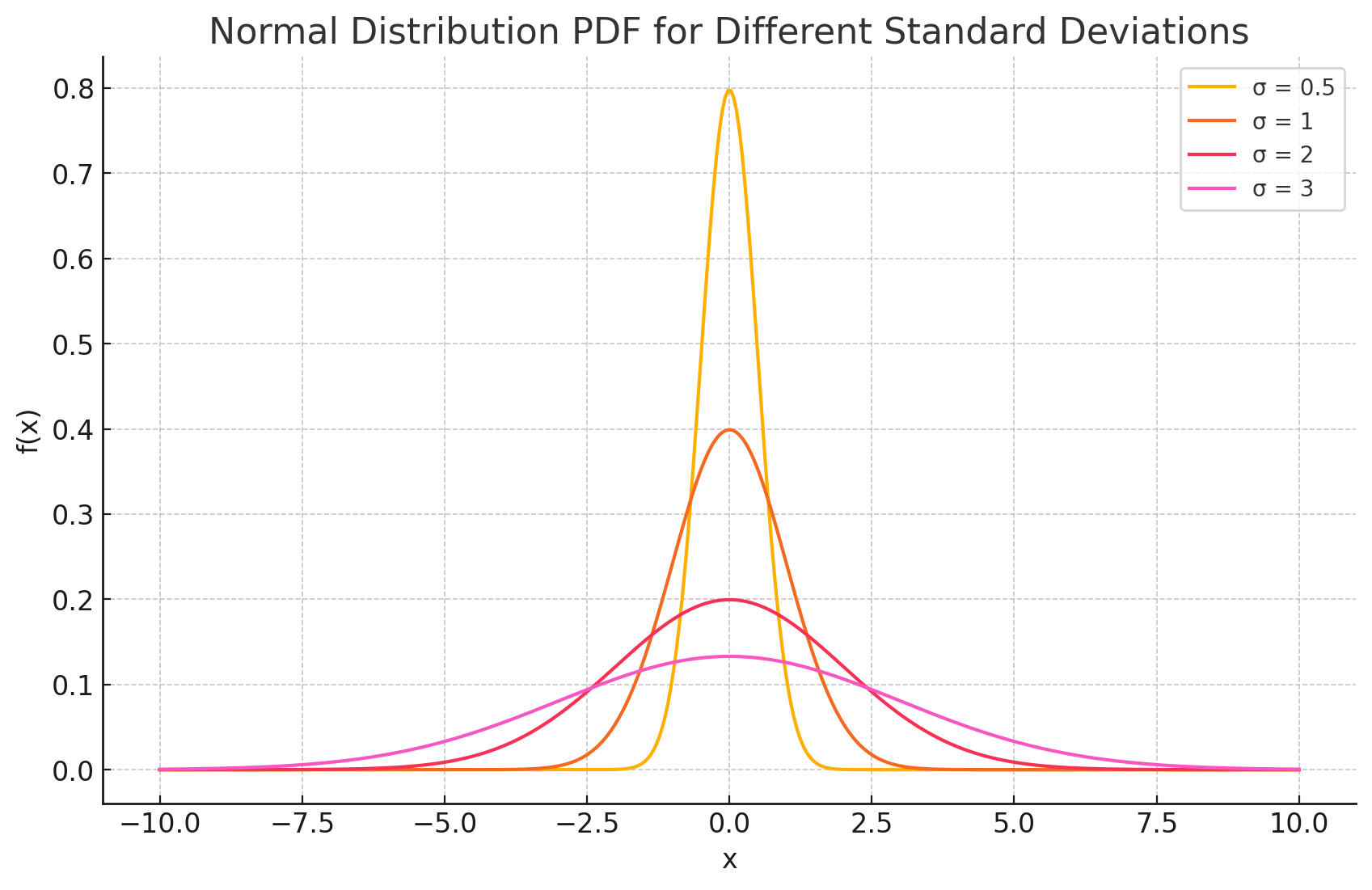
The squared distance $(x-\mu)^2$ makes deviations symmetric, the exponential makes them rare as we move out, and $1/(\sigma\sqrt{2\pi})$ normalizes the area to 1. As with any continuous distribution, $f(x)$ is a density, not a probability: $P(X = x) = 0$, and real probabilities are areas, $P(a \le X \le b) = \int_a^b f(x)\,dx$.
The 68-95-99.7 Rule and z-Scores
For any Normal, about 68% of the mass lies within $1\sigma$ of the mean, 95% within $2\sigma$, and 99.7% within $3\sigma$. This works because every Normal reduces to the same standard Normal by the z-score
\[z = \frac{x - \mu}{\sigma},\]which measures “how many standard deviations from the mean,” stripping out the units. Probabilities then come from the standard Normal CDF $\Phi(z)$, regardless of the original scale.
A Worked Example: A Standardized Assessment
Setup. A (synthetic) assessment is designed to have scores $X \sim N(\mu = 100,\ \sigma = 15)$. What fraction of test-takers score above 130?
The z-score is $z = (130 - 100)/15 = 2$, so
\[P(X > 130) = P(Z > 2) = 1 - \Phi(2) \approx 0.023.\]About 2.3% score above 130. (The scores here are a designed, bounded scale, which is exactly why a real test is only approximately Normal in the middle and not in the tails.)
What the CLT Does and Does Not Say
The Normal’s ubiquity traces to the Central Limit Theorem: under suitable conditions, the standardized sum or average of many independent variables converges to a Normal, whatever the shape of the individual variables. Crucially, the CLT is a statement about sums and averages, not about the raw variables. It does not imply that every underlying quantity is Normal, and it says nothing about the far tails, which converge slowest and matter most for risk.
When It Fits, and When It Fails
| Assumes | Symmetric, additive variation around a single center |
| Common violation | Bounded outcomes, strong skew, multiple subpopulations (multimodality), and heavier tails than Gaussian |
| Closest relatives | Log-Normal when effects multiply instead of add; Laplace for a sharper peak and heavier tails at equal variance |
A pointed cautionary case: modeling financial returns as Normal to compute Value at Risk materially understates tail risk, because real returns have fatter tails than a Gaussian, so a “5% worst day” ($z \approx -1.65$) is worse and more frequent than the model claims.
A Minimal Code Check
1
2
3
4
5
6
from scipy.stats import norm
mu, sigma = 100, 15
norm.sf(130, mu, sigma) # P(X > 130), z=2 -> 0.023
norm.cdf(1) - norm.cdf(-1) # within 1 sigma -> 0.6827 (the 68 in 68-95-99.7)
norm.ppf(0.95, mu, sigma) # 95th percentile score -> ~124.7
Appendix: Deriving the Mean and Variance
Both moments reduce to standard-normal integrals under the substitution $z = (x - \mu)/\sigma$, where $x = \sigma z + \mu$ and $dx = \sigma\,dz$.
The Mean
\[E[X] = \int_{-\infty}^{\infty} x\,\frac{1}{\sigma\sqrt{2\pi}}\,e^{-\frac{(x-\mu)^2}{2\sigma^2}}\,dx = \int_{-\infty}^{\infty} (\sigma z + \mu)\,\frac{1}{\sqrt{2\pi}}\,e^{-z^2/2}\,dz.\]Split the integral. The $\sigma z$ piece integrates an odd function against a symmetric density, so it is zero; the $\mu$ piece is $\mu$ times the total area under the standard normal, which is one:
\[E[X] = 0 + \mu\cdot 1 = \mu.\]The Variance
By definition $\text{Var}(X) = E[(X - \mu)^2]$. The same substitution turns $(x - \mu)^2$ into $\sigma^2 z^2$:
\[\text{Var}(X) = \frac{\sigma^2}{\sqrt{2\pi}}\int_{-\infty}^{\infty} z^2 e^{-z^2/2}\,dz.\]Integrating by parts with $u = z$ and $dv = z e^{-z^2/2}\,dz$, so $v = -e^{-z^2/2}$, the boundary term vanishes and the remainder is $\int_{-\infty}^{\infty} e^{-z^2/2}\,dz = \sqrt{2\pi}$, hence
\[\text{Var}(X) = \frac{\sigma^2}{\sqrt{2\pi}}\cdot\sqrt{2\pi} = \sigma^2.\]So the parameters $\mu$ and $\sigma^2$ are the mean and variance, by construction, which is part of why the Normal is so convenient.
Where this sits in the series. Previous concept: Exponential. Next concept: Log-Normal (multiplicative variation). Closest cousin: Laplace (equal-variance comparison). Series overview.