Probability Distribution: Laplace
The Laplace distribution: a sharp-centered symmetric model with heavier-than-Normal (still exponential) tails, its median/L1 connections, and where it fits.
Probability distributions, a field guide (10 posts). This is Laplace. See the series overview for the full map.
The Question It Answers
What symmetric model concentrates more sharply at the center yet produces more moderate-to-large deviations than a Gaussian? The Laplace (or double-exponential) distribution answers this: it looks like two Exponential curves placed back-to-back, giving a sharp tent-like peak and tails that are heavier than the Normal’s. Those tails still decay exponentially, so Laplace is not “heavy-tailed” in the power-law sense; it is simply heavier than Gaussian.
| Field | Content |
|---|---|
| Type | Continuous |
| Random variable | $X$ = a real-valued deviation or error |
| Support | $-\infty < X < \infty$ |
| Parameters | $\mu$ = location (mean = median = mode; units of $X$); $b$ = scale ($b > 0$; units of $X$) |
| Mean | $\mu$ |
| Variance | $2b^2$ |
| Signature | Absolute-distance exponential: a sharp peak with heavier-than-Normal tails |
Shape Before Formula
The Normal penalizes deviations by their square; the Laplace penalizes them by their absolute value. That single change, $\lvert x - \mu \rvert$ instead of $(x-\mu)^2$, produces the sharp peak and the slower tail decay.
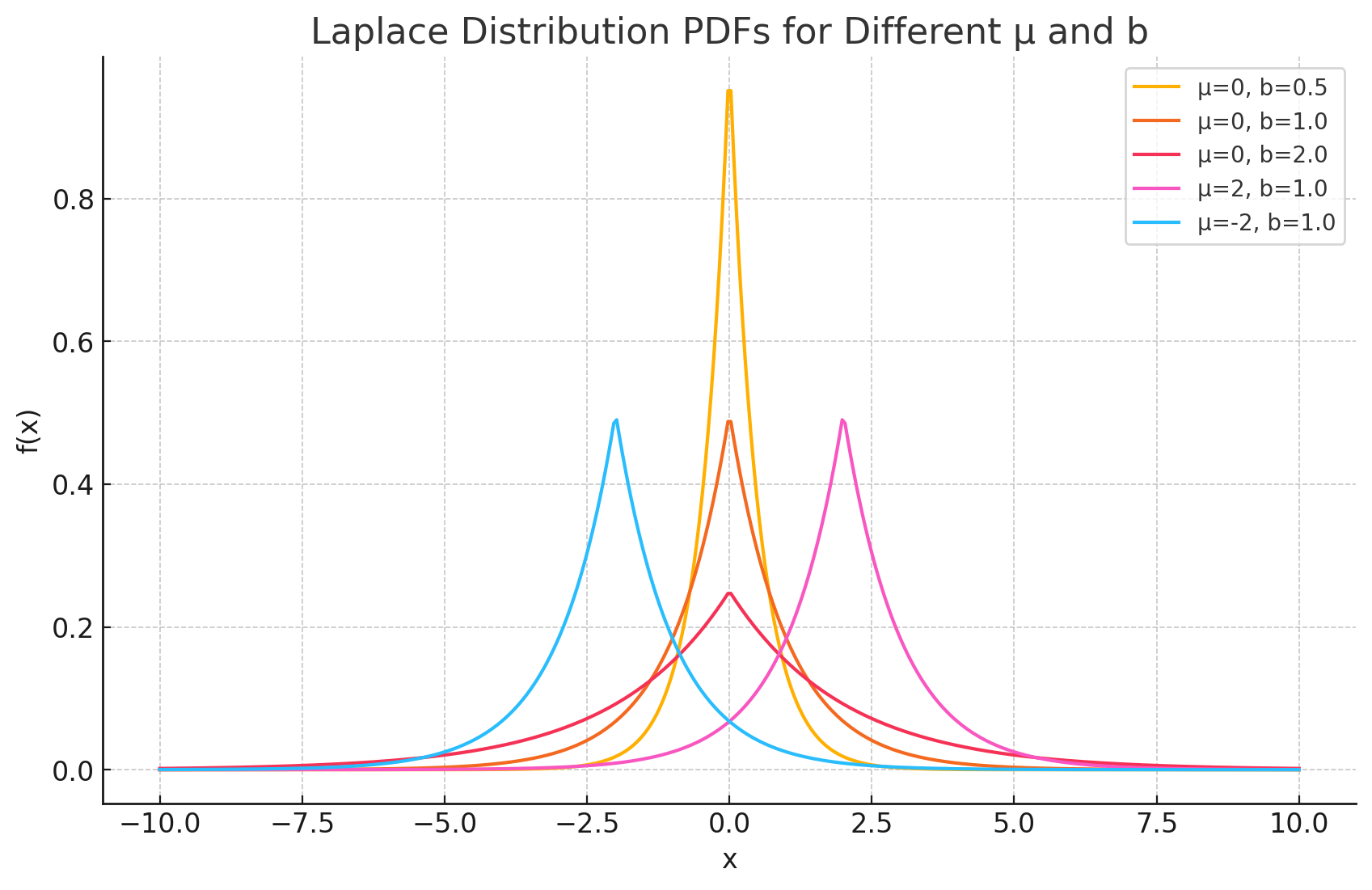
The comparison above holds variance fixed, so the difference in shape is real and not just a rescaling: at equal variance the Laplace is peakier in the middle and fatter in the tails, trading shoulder mass for both.
CDF, Central Intervals, and Spread
The CDF is piecewise (splitting at $\mu$), which makes symmetric intervals clean:
\[F(x) = \begin{cases} \tfrac{1}{2} e^{(x-\mu)/b} & x < \mu \\[4pt] 1 - \tfrac{1}{2} e^{-(x-\mu)/b} & x \ge \mu \end{cases}, \qquad P(\lvert X - \mu \rvert \le t) = 1 - e^{-t/b}.\]For example, with $\mu = 0$ and $b = 2$ (a sensor whose errors are usually small but occasionally larger), $P(-3 \le X \le 3) = 1 - e^{-3/2} \approx 0.777$. A robust spread measure is the median absolute deviation, which for the Laplace is exactly $\text{MAD} = b\ln 2$.
Two ML Connections, Kept Separate
The Laplace shows up twice in machine learning, and the two roles are routinely conflated:
- Absolute-residual loss (minimizing $\sum_i \lvert y_i - \hat y_i \rvert$) corresponds to a Laplace likelihood on the residuals and estimates the conditional median. This is least-absolute-deviations regression, the median case of quantile regression, and it is more robust to outliers than squared-error regression.
- An L1 penalty on the coefficients (as in Lasso) corresponds to a Laplace prior on the coefficients in a Bayesian view. Lasso keeps the ordinary squared-residual loss and merely adds $\lambda\sum_j \lvert \beta_j \rvert$; the sharp peak of the Laplace prior at zero is what drives coefficients exactly to zero for feature selection.
One is a claim about the error distribution (median regression); the other is a claim about the coefficients (Lasso). They are different mechanisms that happen to share the Laplace’s absolute-value signature.
Where It Comes From, and When It Fits
The difference of two independent Exponential variables with the same rate is a zero-centered Laplace; adding a location gives the general $\text{Laplace}(\mu, b)$. That is why it appears wherever a quantity is a difference of two waiting-time-like effects.
| Assumes | Symmetric errors that are usually small but occasionally moderately large |
| Common violation | True extreme-value problems (annual maxima, flood peaks), which need dedicated extreme-value distributions (Gumbel/GEV), not merely a curve with more central-tail mass |
| Closest relatives | Normal (squared vs absolute distance); Exponential (its one-sided half) |
A good use case is symmetric error with occasional larger deviations, such as sensor noise or certain signal amplitudes; a poor one is modeling maxima, where a heavier-than-Normal body says nothing about the right model for the extreme tail.
A Minimal Code Check
1
2
3
4
5
6
7
import numpy as np
from scipy.stats import laplace
mu, b = 0.0, 2.0 # scipy: loc = mu, scale = b
laplace.cdf(3, mu, b) - laplace.cdf(-3, mu, b) # P(|X|<=3) -> 0.777
laplace.var(mu, b) # 2 b^2 -> 8.0
b * np.log(2) # median absolute deviation -> 1.386
Appendix: Deriving the Mean and Variance
Shift to $Y = X - \mu$, whose density $f_Y(y) = \frac{1}{2b}e^{-\lvert y\rvert/b}$ is symmetric about 0. Both moments are cleanest in terms of $Y$.
The Mean
The integrand $y\,f_Y(y)$ is odd (an odd function times an even density) and integrable, so it integrates to zero over the symmetric range:
\[E[Y] = \int_{-\infty}^{\infty} y\,\frac{1}{2b}e^{-\lvert y\rvert/b}\,dy = 0.\]Therefore $E[X] = E[Y] + \mu = \mu$. (Note this is not the same as claiming $x f(x)$ is symmetric about $\mu$, which is false; the symmetry that matters is that of the shifted density $f_Y$ about 0.)
The Variance
Since $E[X] = \mu$, the variance is $E[(X - \mu)^2] = E[Y^2]$. The integrand $y^2 f_Y(y)$ is even, so we integrate over $[0, \infty)$ and double:
\[\text{Var}(X) = 2\int_{0}^{\infty} y^2\,\frac{1}{2b}e^{-y/b}\,dy = \frac{1}{b}\int_{0}^{\infty} y^2 e^{-y/b}\,dy.\]The remaining integral is a Gamma integral, $\int_{0}^{\infty} y^{n} e^{-y/b}\,dy = n!\,b^{n+1}$, which at $n = 2$ gives $2b^3$. Hence
\[\text{Var}(X) = \frac{1}{b}\cdot 2b^3 = 2b^2.\]Where this sits in the series. Previous concept: Log-Normal. Next concept: Gamma (waiting time for the $k$-th event). Closest cousins: Normal (equal-variance comparison) and Exponential (its one-sided half). Series overview.