Deep Learning Primer: Exploring Regularization Techniques in DNN
Regularization in deep learning is a set of strategies used to improve a model’s performance on data it was not trained on, that is, to reduce overfitting.
Overfitting is best understood as a gap: the model does better on the training set than on the deployment distribution it will actually face. Large networks certainly can memorize training examples, but a model need not reach perfect training accuracy to overfit, and memorization is not the only cause: distribution shift, data leakage, selection bias, and even tuning too hard on the validation set all widen the same gap.
Regularization narrows that gap, but “forcing the model to be simpler” is only one of the ways it does so. Weight penalties do constrain complexity; but data augmentation injects invariances, early stopping changes the optimization path, and Batch Normalization changes the parameterization and stochasticity of training. It is a toolbox of interventions on the objective, the data, the architecture, and the stopping rule, not a single lever.
Top 5 Regularization Techniques
1. L1 and L2 Regularization (and Weight Decay)
This is the most traditional mathematical approach: add a penalty term to the loss based on the size of the weights ($w$).
- L2 Regularization (Ridge): Adds a penalty proportional to the square of the weights ($w^2$). It pulls weights toward small values (rarely exactly zero), discouraging any single weight from growing large.
- Formula: $Loss + \lambda \sum w^2$
- L1 Regularization (Lasso): Adds a penalty proportional to the absolute value of the weights ($\lvert w \rvert$). It drives some weights exactly to zero, producing a sparse weight vector.
- Formula: $Loss + \lambda \sum \lvert w \rvert$
Two clarifications this pairing invites. First, an L2 penalty is not always the same as “weight decay.” Adding $\lambda\lVert W\rVert^2$ to the loss is equivalent to multiplicatively shrinking the weights each step only for plain SGD; under adaptive optimizers like Adam the two differ, which is exactly what AdamW fixes (see the optimizers post). Second, L1 on a hidden layer’s weights does not select input features. It zeros individual weights, not input dimensions, and those unstructured zeros are not the same as structured feature/neuron/channel sparsity, nor do scattered zeros automatically speed up a dense matrix multiply.
2. Dropout
Dropout is a technique specific to neural networks. During training, the model randomly “drops” (deactivates) a percentage of neurons in a layer for that specific forward and backward pass.
- How it works: By randomly removing neurons, the network cannot rely on any specific path or set of neurons to make a prediction. It forces the network to learn redundant representations, making it more robust.
- Analogy: It is like managing a team where employees are randomly sent on vacation every day; the team learns to cross-train so that no single person is a point of failure.
3. Early Stopping
This is an iterative technique. Instead of training for a fixed number of epochs, we monitor performance on a separate validation set and stop when it stops improving.
- How it works: training error usually keeps dropping, but validation error eventually bottoms out and turns upward, the onset of overfitting. Early stopping keeps the checkpoint at that bottom.
- Doing it correctly: validation metrics are noisy, so we do not stop at the first uptick. In practice we fix a monitored metric and its direction, a minimum improvement to count as progress, a patience (how many evaluations to wait for improvement before stopping), an evaluation frequency, and we restore the best checkpoint at the end rather than keeping the last one. And because every one of these decisions is made by looking at the validation set, a truly untouched test set is what finally reports generalization; repeatedly tuning against one validation set slowly overfits it too.
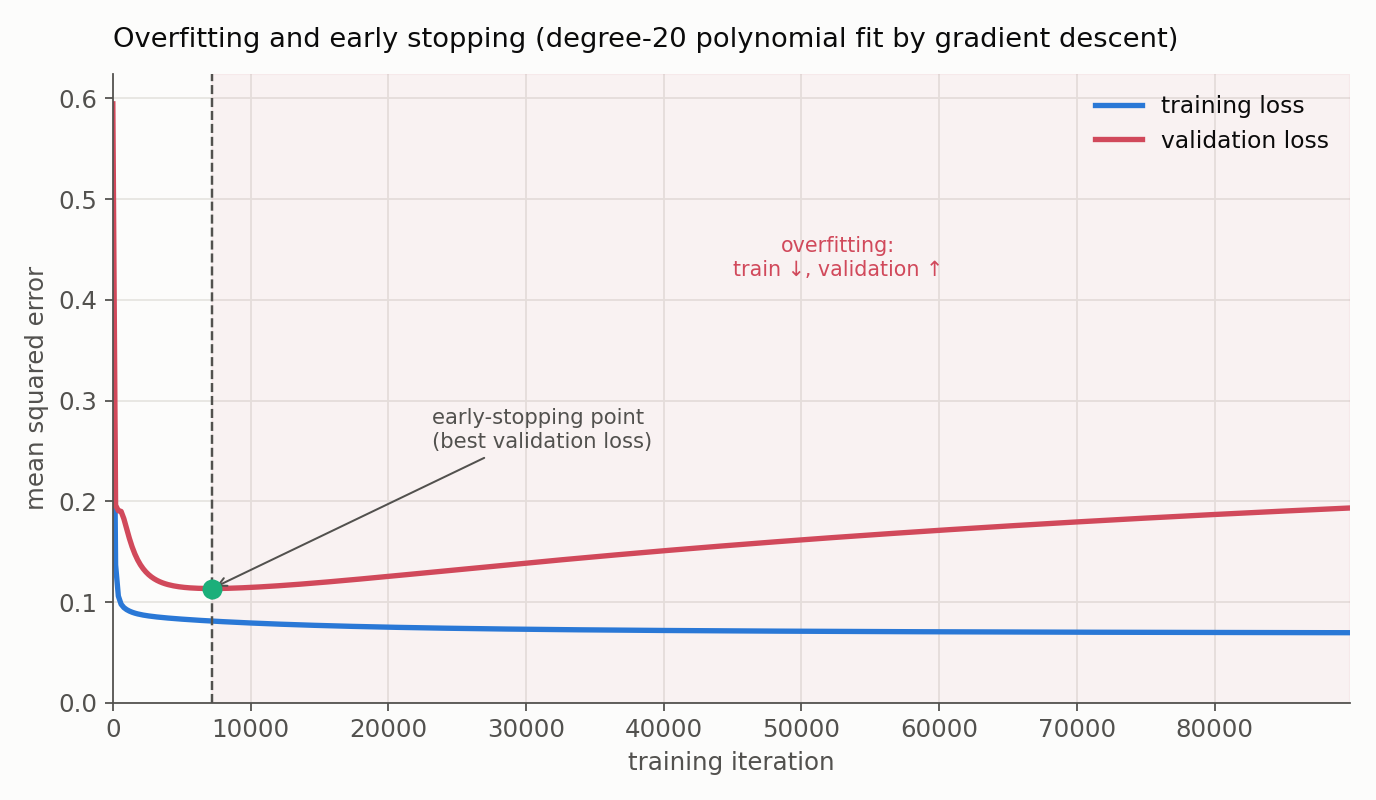
The curve above is a real gradient-descent run: training loss keeps sliding down as the model fits the noise, while validation loss bottoms out and climbs. Early stopping simply returns the checkpoint at that bottom.
4. Data Augmentation
When training data is limited, augmentation expands it by creating label-preserving variations of existing examples. It is not image-only: text (synonym swaps, back-translation), audio (time and pitch shifts, added noise), time series, graphs, and tabular data all have their own augmentations.
- How it works: for an image of a cat we might crop, zoom, adjust brightness, or flip it, and to the model these are new examples of the same label, teaching invariance to those transformations.
- The catch is label validity: each transformation must preserve the target semantics, and that is domain-specific. A vertically flipped “6” is a “9”; rotating a chest X-ray or a road-scene image can invert the very thing being predicted. The right discipline is to justify each transformation from a genuine invariance of the task and validate it on held-out data, not to bolt on every transform available.
5. Batch Normalization
Batch Normalization is primarily a normalization technique for stabilizing and speeding up training, but it has a regularizing side effect.
- How it works: it normalizes a layer’s inputs using the mean and variance of the current mini-batch. Because those statistics are estimated from a small, noisy batch rather than the whole dataset, each example sees slightly different normalization from step to step, injecting noise that discourages over-reliance on any one activation, loosely like Dropout. This side effect is context-dependent (it weakens with large batches, and interacts with data correlation and distributed training), which is why we treat BN as normalization first and a regularizer second.
Summary Comparison
| Technique | Primary Mechanism | Best Used When… |
|---|---|---|
| L1 / L2 | Mathematical Penalty | We want to constrain weight size (L2) or select features (L1). |
| Dropout | Random Deactivation | We have a large, deep network (esp. Fully Connected layers). |
| Early Stopping | Validation Monitoring | We are unsure how many epochs to train for. |
| Data Augmentation | Dataset Expansion | We have limited training data (common in Computer Vision). |
| Batch Norm | Input Normalization | We want faster convergence + mild regularization. |
- We covered L1/L2 penalties in detail in the linear-regression post; the core idea carries over to DNNs, with the weight-decay caveat noted above.
- Early stopping is largely a training-loop configuration in modern libraries (with the patience and checkpoint discipline above), so we do not dwell on it further.
- Data augmentation is most developed for computer vision but, as noted, applies across modalities; a thorough treatment is domain-specific enough to deserve its own post.
This leaves us with two remaining regularization techniques: Dropout and Batch Normalization. Let’s dig deep into these two.
A Deep Dive into Dropout mechanics in DNNs
Deep Neural Networks (DNNs) are powerful because of their ability to learn complex relationships involving myriad features. However, this power comes with a significant downside: overfitting. With massive numbers of parameters, networks often begin to memorize noise in the training data rather than learning generalizable underlying patterns. This manifests as “co-adaptation,” where neurons in later layers rely excessively on the specific, idiosyncratic outputs of highly specific neurons in previous layers.
Dropout is a radical yet elegantly simple regularization technique introduced to shatter these co-adaptations and force the network to learn robust features.
1. High-Level Explanation of the Technique
At its core, Dropout is a stochastic regularization technique that temporarily modifies the network structure during the training phase.
For every training example (or mini-batch) that passes through the network, Dropout randomly “drops” (temporarily removes) units, along with all their incoming and outgoing connections. Each unit is kept independently with probability $q$, sampled from a Bernoulli distribution. We use $q$ for the keep probability throughout; be aware that libraries differ, PyTorch’s Dropout(p) takes the drop probability $p = 1 - q$, so a “dropout of 0.2” keeps 80% of units.
By randomly removing neurons, the remaining network is forced to learn how to make correct predictions without relying on the presence of any specific neighbor. No single neuron can rely solely on a specific input feature or a specific upstream neuron, because that input might vanish in the next iteration. This forces each neuron to learn features that are generally useful in conjunction with many different random subsets of other neurons, leading to more robust, redundant internal representations and significantly reduced overfitting.
2. Similarity to Bagging (Random Forest)
To understand why Dropout works so effectively, it is helpful to view it through the lens of ensemble learning, specifically Bagging (Bootstrap Aggregating).
Bagging is a technique used in algorithms like Random Forests. It involves training multiple distinct models (e.g., decision trees) on different random subsets of the training data and then averaging their predictions. The theory is that while individual models may have high variance (each overfits its own data subset), averaging them cancels out their individual errors, resulting in a final model with lower variance.
Dropout can be interpreted as an extreme, efficient form of bagging for neural networks.
When we apply dropout to a network with $n$ units, we are effectively defining $2^n$ possible “thinned” sub-networks (every unit can either be present or absent). Because these networks are trained on slightly different subsets of data (due to mini-batching) and have different architectures (due to specific units being dropped), they will make different errors.
Training with dropout can be seen as training a massive ensemble of exponentially many thinned networks, and testing with the full network acts as an approximate averaging of this ensemble’s predictions.
3. Mathematical Framework for Variance Reduction
We can show cleanly why averaging an ensemble of models reduces the overall Mean Squared Error (MSE) of the predictions, and why decorrelating those models matters. Treat this as the intuition behind the dropout-as-ensemble picture, a general lesson about correlated ensembles, not a proof that dropout itself behaves this way (the disanalogies come right after).
Let us assume we are training an ensemble of $k$ distinct neural networks. Let $Y_i$ be the prediction of the $i$-th network. Let the target value be $T$. The error of the $i$-th network is $\epsilon_i = Y_i - T$.
We assume:
- Every network has the same expected error (bias is zero for simplicity): $E[\epsilon_i] = 0$.
- Bias-Variance Decomposition: $MSE = Variance + Bias^2 \Rightarrow MSE = Variance$
- Every network has the same variance: $Var(\epsilon_i) = E[\epsilon_i^2] = V$.
- The correlation between the errors of any two distinct networks $i$ and $j$ is constant, resulting in a constant covariance: $Cov(\epsilon_i, \epsilon_j) = E[\epsilon_i \cdot \epsilon_j] = C$, for $i \neq j$.
Prediction and error calculation:
- Prediction of the ensemble is the average: $Y_{ens} = \frac{1}{k}\sum_{i=1}^k Y_i$.
- The average error of the ensemble is $E_{ens} = \frac{1}{k}\sum_{i=1}^k \epsilon_i$.
We want to find the MSE of the ensemble, which is the variance of $E_{ens}$:
\[MSE_{ens} = E(E_{ens}^2) = E(E_{ens}^2) - E^2(E_{ens} ( = 0)) = Var(\frac{1}{k}\sum_{i=1}^k \epsilon_i) = \frac{1}{k^2} Var(\sum_{i=1}^k \epsilon_i)\]The variance of a sum of correlated random variables is the sum of their variances plus the sum of their covariances:
\[Var(\sum_{i=1}^k \epsilon_i) = \sum_{i=1}^k Var(\epsilon_i) + \sum_{i \neq j} Cov(\epsilon_i, \epsilon_j)\]There are $k$ variance terms ($V$) and $k(k-1)$ pairs of covariance terms ($C$):
\[Var(\sum_{i=1}^k \epsilon_i) = k \cdot V + k(k-1) \cdot C\]Substituting this back into the MSE equation:
\[MSE_{ens} = \frac{1}{k^2} [k V + k(k-1) C]\] \[\mathbf{MSE_{ens} = \frac{V}{k} + \frac{k-1}{k}C}\]From this derived formula, we can see two extreme scenarios:
Highly Correlated Errors ($C \approx V$): If all networks make the exact same errors, their correlation is maximal.
\[MSE_{ens} = \frac{V}{k} + \frac{k-1}{k}V = \frac{V + kV - V}{k} = \frac{kV}{k} = V\]Conclusion: If the models are perfectly correlated, averaging them provides zero benefit. The ensemble variance is the same as a single model’s variance.
Uncorrelated Errors ($C = 0$): If the networks are truly independent and their errors are uncorrelated.
\[MSE_{ens} = \frac{V}{k} + \frac{k-1}{k}(0) = \frac{V}{k}\]Conclusion: If errors are uncorrelated, the ensemble variance decreases linearly with the number of models ($k$). This is the ideal scenario for bagging.
The Dropout Connection (an analogy, with limits): the lesson above is that an ensemble helps most when its members are decorrelated, and dropout’s random masking does discourage neurons from co-adapting. But the dropout-as-bagging picture is intuition, not a rigorous derivation, and it is worth being precise about where it breaks (Srivastava et al., 2014):
- The thinned sub-networks share weights; they are not independent models trained on separate bootstrap datasets.
- Each mask is sampled once per step and is not trained to convergence.
- Test-time inference uses the full, deterministic network, which for a nonlinear model is only an approximation of averaging the ensemble, not an exact average.
So the equal-variance, equal-covariance formula above does not prove that dropout reduces the model’s MSE, nor that it drives the between-subnetwork covariance to zero. It explains, in spirit, why breaking co-adaptation helps.
4. Overcoming Computational Infeasibility
While the bagging analogy is sound theoretically, implementing it directly is impossible for DNNs.
If a network has $n$ total neurons, there are $2^n$ possible distinct sub-networks. For any reasonably sized network, $2^n$ is astronomical. We cannot train separate models for all combinations, nor can we average $2^n$ predictions at inference time.
Dropout solves this computational intractability through two clever mechanisms:
- Stochastic Sampling: Instead of explicitly enumerating all $2^n$ networks, we sample one randomly for every training step (mini-batch). Over countless training iterations, we effectively explore the space of possible architectures.
- Weight Sharing: Crucially, all these $2^n$ virtual networks share the exact same set of parameters (weights and biases). If a neuron is active in “sub-network A” and “sub-network B,” it uses the same weight matrix in both.
This means training with dropout is roughly equivalent to training a massive ensemble where the members share parameters.
5. The Training Process: Inverted Dropout Mechanics
Early implementations of dropout required adjustments at testing time to ensure the magnitudes of neuron outputs remained consistent. Modern deep learning frameworks (like TensorFlow/Keras and PyTorch) almost exclusively use a slightly different implementation called Inverted Dropout.
Inverted dropout performs scaling during the training phase so that the testing phase requires no changes.
Let’s define $p$ as the “keep probability” (the probability that a neuron remains active, e.g., $p=0.8$).
The training process for a single layer using inverted dropout is as follows:
Step 1: Forward Pass - Generate Activations. The layer computes its raw activations $A$ based on inputs and weights, typically followed by a non-linearity (like ReLU). Let’s assume a small layer outputting a vector of 5 activations: $A = [10.0, 25.0, 5.0, 40.0, 15.0]$
Step 2: Generate Mask. A binary mask vector $M$ of the same shape as $A$ is generated. Each element of $M$ is sampled independently from a Bernoulli distribution where $P(1) = p$. Let’s assume $p=0.6$ (we keep 60% of neurons). A random mask might look like: $M = [1, 1, 0, 1, 0]$
Step 3: Apply Mask. Element-wise multiplication is performed between the activations and the mask. This drops the selected neurons (sets them to zero). $A_{masked} = A \odot M = [10.0, 25.0, 0.0, 40.0, 0.0]$
Step 4: Inverted Scaling (The Crucial Step). Because we dropped a fraction of the neurons $(1-p)$, the expected sum of the activations in the next layer will be lower by a factor of $p$. To maintain the expected magnitude of the activations, we scale the remaining activations up by dividing by $p$. Scaling factor $= 1 / 0.6 \approx 1.667$
\[A_{final} = A_{masked} / p = [10.0, 25.0, 0.0, 40.0, 0.0] / 0.6\] \[A_{final} \approx [16.67, 41.67, 0.0, 66.67, 0.0]\]Note: In practice, this scaling is often applied directly to the mask in step 2.
What the $1/q$ scaling actually preserves. Writing the keep-mask as $m_i \sim \text{Bernoulli}(q)$ and the scaled activation as $\tilde{a}_i = \frac{m_i}{q}\,a_i$, dividing by $q$ preserves the activation in expectation:
\[\mathbb{E}[\tilde{a}_i \mid a_i] = \frac{a_i}{q}\,\mathbb{E}[m_i] = \frac{a_i}{q}\cdot q = a_i.\]That is the exact guarantee, and it is a statement about the mean of a single unit, not about any particular sample’s activation sum or the whole network’s output distribution. The cost is added variance, which is what does the regularizing:
\[\operatorname{Var}(\tilde{a}_i \mid a_i) = a_i^2\,\frac{1-q}{q}.\]A lower keep probability (more dropping) injects more variance per unit.
Step 5: Backward Pass. During backpropagation, gradients only flow backward through the neurons that were active in the forward pass (mask value 1). The gradients are also scaled by $1/p$ to match the forward pass scaling.
6. Inference Time Adjustment
A major advantage of the Inverted Dropout mechanism described above is simplicity at inference (deployment) time.
At test time, we want to use the full power of the trained network, so we do not drop any neurons.
Because we already scaled up the activations during training (Step 4 above) to account for the missing neurons, the expected magnitudes of the weights are already correct for the full network scenario.
Therefore, no weight adjustment or scaling is required at inference time. We simply stop applying the random masking procedure and use the full network as is.
A Deep Dive into Batch Normalization
Here is a structured breakdown of Batch Normalization.
1. Motivation: The Original “Internal Covariate Shift” Story
The original motivation (Ioffe & Szegedy, 2015) was internal covariate shift: as earlier layers update during training, the distribution of inputs to later layers keeps shifting, so those layers must chase a moving target, forcing lower learning rates and careful initialization.
This framing is worth flagging as historical. Later work (Santurkar et al., 2018) found that reducing covariate shift did not actually explain BN’s benefit, and argued the real effect is a smoother optimization landscape. The empirical wins are not in dispute; the causal story is.
Batch Normalization (BN) normalizes the inputs of each layer using mini-batch statistics, which in practice buys:
- Higher learning rates: training is typically faster and more stable.
- A regularizing side effect: the noise from estimating statistics on mini-batches acts as a mild regularizer, though (as noted earlier) this is context-dependent and weakens with large batches.
- Reduced sensitivity to initialization: the network tolerates a wider range of initial weights.
2. Mathematical Formulation and Process
Batch Normalization is applied to a mini-batch of inputs. It is often placed after the linear transformation (convolution or dense layer) and before the activation, as in the original paper, but this is not universal: pre-activation ResNets and various later architectures reorder or relocate the normalization.
Consider a mini-batch $\mathcal{B}$ of size $m$ with values $x_{1 \dots m}$.
The Normalization Step
First, we calculate the mean and variance of the current mini-batch:
\[\mu_{\mathcal{B}} = \frac{1}{m} \sum_{i=1}^m x_i\] \[\sigma_{\mathcal{B}}^2 = \frac{1}{m} \sum_{i=1}^m (x_i - \mu_{\mathcal{B}})^2\]Next, we normalize the input so it has zero mean and unit variance. We add a tiny constant $\epsilon$ for numerical stability (to avoid dividing by zero):
\[\hat{x}_i = \frac{x_i - \mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^2 + \epsilon}}\]The Scale and Shift Step (Crucial)
If we stopped at normalization, we would constrain the layer’s inputs to always be a standard normal distribution. This might limit the network’s representational power (for example, constraining inputs to the linear regime of a Sigmoid function effectively nullifying the non-linearity).
To restore this power, BN introduces two learnable parameters per feature: Scale ($\gamma$) and Shift ($\beta$).
\[y_i = \gamma \hat{x}_i + \beta\]The network learns $\gamma$ and $\beta$ through backpropagation. These restore per-feature affine expressivity: the layer can rescale and re-shift each normalized feature to whatever scale and mean help the next layer. This is not a literal “undo” of the normalization in general, though, since $\gamma, \beta$ are fixed learned constants while the subtracted $\mu, \sigma$ vary with each batch; the affine step recovers representational freedom, not the exact per-batch statistics that were removed.
Training vs. Inference
There is a critical difference in how BN behaves during these two phases:
- Training: The mean $\mu$ and variance $\sigma^2$ are calculated strictly based on the current mini-batch.
- Inference (Testing): we cannot rely on batch statistics (we might predict on a single example), so we use running averages of the means and variances accumulated during training. These running statistics are estimates maintained over training, standing in for the population statistics, not the exact population values.
3. Parameter Learning: A 2D Dataset Example
To visualize what the parameters $\gamma$ (scale) and $\beta$ (shift) actually do, let’s imagine a simple 2D dataset.
The Setup: Imagine a layer outputs 2D features for a batch of data. Let’s say the raw data is a cloud of points centered at $(10, 10)$ with a spread (variance) of $5$.
Step 1: Normalization (The Constraint) Batch Norm centers each feature at $0$ and scales it to unit variance, independently per feature.
- Effect: each axis is standardized, but BN does not decorrelate the features or whiten the covariance. If the original cloud was tilted or correlated, it stays tilted, just re-centered and per-axis rescaled, so it does not become a round sphere in general.
- Problem: if the next layer is a ReLU, roughly the negative half of each feature gets zeroed. The normalization on its own may have hurt the model’s ability to learn.
Step 2: Learning $\beta$ (The Shift) The network realizes (via the gradient descent signal) that it is losing too much information. It updates the Shift parameter $\beta$.
- Let’s say it learns $\beta = [2, 2]$.
- Effect: The entire cloud of data is moved from $(0,0)$ to $(2,2)$. Now, most of the data is positive, and the ReLU activation allows it to pass through.
Step 3: Learning $\gamma$ (The Scale) The network might also realize the data is too “cramped” near the center. It updates the Scale parameter $\gamma$.
- Let’s say it learns $\gamma = [3, 0.5]$.
- Effect: The cloud is stretched wide along the x-axis and squashed along the y-axis.
Conclusion: While the normalization step ensures the data is stable and centered, the parameters $\gamma$ and $\beta$ allow the network to move and reshape that distribution to the exact “sweet spot” where the next layer can process it most effectively.
A Note on Modern Regularizers
The five above are the classics, but the toolbox has grown, and most modern additions are architecture- or domain-specific rather than universal:
- Stochastic depth / DropPath: randomly skip entire residual blocks during training, a dropout-like idea at the level of layers, common in very deep residual networks and vision transformers.
- Label smoothing: replace hard one-hot targets with slightly softened ones (e.g. 0.9 and 0.1 instead of 1 and 0), which discourages over-confident logits and often improves calibration.
- mixup / CutMix: train on convex combinations (or spliced patches) of pairs of examples and their labels, a data-side regularizer that is standard in image classification but must be checked for label validity in other domains.
None of these is a default to reach for blindly; each is worth adding only when the architecture and task justify it, and each can underfit or corrupt labels when over-applied, exactly the failure mode the augmentation caveat warned about.