Deep Learning Primer: Weight Initialization and Layer Normalization
Optimization and stabilization techniques for DNNs focus on training stability (making sure the model actually learns without diverging) and optimization efficiency (reaching the best solution faster).
Top 5 Optimzation & Stabilization Techniques
1. Weight Initialization Strategies (He & Xavier)
Before the network sees a single data point, the starting values of its weights determine whether training will be smooth or impossible. Poor initialization leads to vanishing or exploding gradients almost immediately.
- The Problem: If weights are initialized too small, signals shrink as they pass through layers (vanishing). If too large, signals grow uncontrollably (exploding).
- The Solution: Use mathematically derived variance scaling to keep signal magnitudes constant across layers.
- Xavier (Glorot) Initialization: Best for Sigmoid or Tanh activation functions. It sets weights based on the number of inputs and outputs of the layer.
- He (Kaiming) Initialization: Best for ReLU (and its variants) activation functions. It accounts for the fact that ReLU zeroes out half the inputs, requiring slightly larger initial weights to maintain signal variance.
2. Normalization Layers (Batch Norm & Layer Norm)
Normalization layers keep the distribution of each layer’s inputs in a stable range as training proceeds. The original motivation was internal covariate shift (the input distribution shifting as earlier layers update); later work questioned that explanation (more on this below), but the empirical stabilizing effect is not in doubt.
- Batch Normalization (BN): Normalizes inputs across the batch dimension.
- Best for: CNNs and standard feed-forward networks.
- Benefit: Allows for much higher learning rates and acts as a mild regularizer.
- Layer Normalization (LN): Normalizes inputs across the feature dimension for a single sample.
- Best for: RNNs and Transformers (where batch dependency is problematic).
- Benefit: Stabilizes training in sequence models where batch statistics can be noisy or undefined.
3. Residual Connections (Skip Connections)
As networks get deeper (e.g., 50+ layers), accuracy often saturates and then degrades, not because of overfitting, but because the optimization becomes too difficult (the degradation problem).
- The Technique: Instead of learning a mapping $H(x)$ directly, the layer learns a residual mapping $F(x) = H(x) - x$. The output becomes $x + F(x)$.
- Why it works: It creates “gradient superhighways.” During backpropagation, the gradient can flow through the skip connection to earlier layers, added to whatever the residual branch contributes. This eases the vanishing-gradient problem and is a large part of what makes extremely deep networks (like the 152-layer ResNet) trainable.
4. Adaptive Optimizers (AdamW)
Standard Stochastic Gradient Descent (SGD) uses a fixed learning rate for all parameters, which can be problematic when some parameters need to change enormous amounts while others need tiny tweaks.
- The Technique: Adaptive optimizers adjust the learning rate for each individual parameter based on the history of gradients.
- Top Choice: AdamW (Adam with Weight Decay).
- Why: It combines Adam (momentum plus per-parameter scaling from squared gradients) with decoupled weight decay. See the optimizers post for why the decoupling matters and where adaptive methods help.
5. Gradient Clipping
Even with good initialization, gradients can occasionally spike (especially in RNNs or very deep networks), causing massive weight updates that “break” the model (the loss suddenly becomes NaN or infinity).
- The Technique: Before updating weights, check the norm (magnitude) of the gradient vector. If it exceeds a threshold (e.g., 1.0), scale the whole vector down so its norm equals that threshold.
- Why it works: It prevents the “exploding gradient” problem physically. It acts as a safety rail, ensuring that no single bad batch of data can destabilize the entire training history.
Comparison Table for Quick Reference
| Technique | Primary Role | Best Use Case |
|---|---|---|
| He/Xavier Init | Foundation | Essential for all deep nets at the start. |
| Batch/Layer Norm | Stabilizer | BN for Images/CNNs; LN for Text/RNNs. |
| Residual connections | Enabler | Essential for very deep networks (>20 layers). |
| AdamW | Accelerator | The default optimizer for most modern tasks. |
| Gradient Clipping | Safety Net | RNNs, LSTMs, and unstable training loops. |
- We covered AdamW in the optimizers post, so we skip it here.
- Batch Normalization is taken up in the regularization post, where its regularizing side effect fits better.
- Residual connections deserve their own treatment and are out of scope here; gradient clipping is a one-line mechanism (cap the gradient norm), already covered in the optimizers post.
This leaves us with two remaining optimization techniques: He/Xavier Initialization and Layer Normalization. Let’s dig deep into these two.
A Deep Dive into He/Xavier Initialization
Here is a detailed breakdown of He and Xavier initialization.
1. Motivation: The “Goldilocks” Zone of Signal
In Deep Neural Networks, the way we initialize weights acts as the foundation for the entire training process. If we initialize weights randomly without a strategy (e.g., using a standard Gaussian distribution $N(0, 1)$), we almost immediately run into one of two catastrophes:
- Vanishing Gradients: If weights are too small, the signal shrinks as it passes through each layer. By the time it reaches the end, the activation is effectively zero. During backpropagation, the gradients (which are proportional to these activations) also become zero, and the network stops learning.
- Exploding Gradients: If weights are too large, the signal grows exponentially with every layer. This causes activations to saturate (hitting the flat parts of Sigmoid/Tanh) or go to infinity (ReLU), leading to
NaNloss values.
The Goal: We want the variance of the activations to remain constant across every layer. The signal shouldn’t amplify or diminish; it should stay in the “Goldilocks” zone to ensure stable gradients flow during both the forward and backward passes.
The figure makes the stakes concrete. Pushing a random input through a 50-layer ReLU network, the activation scale either explodes, vanishes, or stays put depending purely on how the weights were initialized:
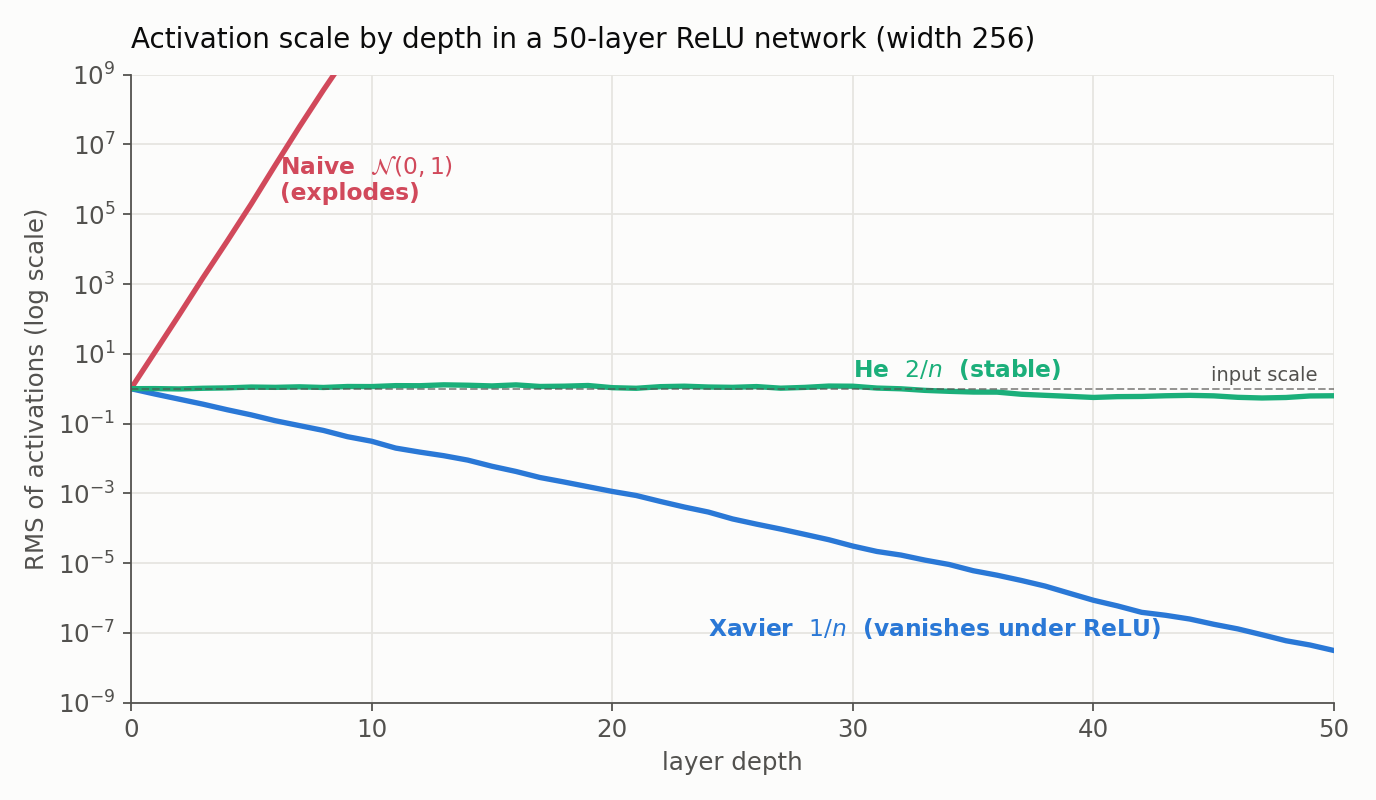
Naive $\mathcal{N}(0,1)$ weights blow the signal up within a handful of layers; Xavier scaling (tuned for tanh) under-shoots for ReLU and the signal decays away; only He scaling holds the activation scale roughly constant with depth. The rest of this section derives why.
2. Mathematical Formulation and Derivations
Let’s derive the condition required to keep the variance stable. Consider a single linear neuron (or a layer in matrix form):
\[y = w_1x_1 + w_2x_2 + \dots + w_n x_n + b\]For initialization, we assume:
- Biases $b = 0$.
- Weights $w$ and Inputs $x$ are independent random variables.
- Weights and Inputs have a mean of zero ($E[w]=0, E[x]=0$).
We want to find the variance of the output $y$:
\[Var(y) = Var\left(\sum_{i=1}^{n_{in}} w_i x_i\right)\]Since $w_i$ and $x_i$ are independent, the variance of the sum is the sum of the variances:
\[Var(y) = \sum_{i=1}^{n_{in}} Var(w_i x_i)\]Using the property $Var(AB) = E[A^2]E[B^2] - (E[A]E[B])^2$, and knowing means are zero:
\[Var(y) = \sum_{i=1}^{n_{in}} Var(w_i) Var(x_i)\]Assuming all weights and inputs share the same variance properties:
\[Var(y) = n_{in} \cdot Var(w) \cdot Var(x)\]The Stability Constraint: To prevent the signal from exploding or vanishing, we want the variance of the output to equal the variance of the input: $Var(y) = Var(x)$.
Substituting this into our equation:
\[Var(x) = n_{in} \cdot Var(w) \cdot Var(x)\]Dividing both sides by $Var(x)$:
\[1 = n_{in} \cdot Var(w)\] \[\mathbf{Var(w) = \frac{1}{n_{in}}}\]This is the fundamental requirement: The variance of the weights must be inversely proportional to the number of input connections (fan-in).
3. Geared Towards Different Activations
The derivation above assumes a linear activation. However, non-linear functions change the variance of the data passing through them. This is where Xavier and He initializations diverge.
A. Xavier (Glorot) Initialization
Target: Sigmoid or Tanh (Logistic functions).
- The Issue: We derived $Var(w) = 1/n_{in}$ for the forward pass. However, for the backward pass (gradients flowing in reverse), similar logic dictates $Var(w) = 1/n_{out}$. Unless $n_{in} = n_{out}$, we cannot satisfy both perfectly.
- The Solution: Xavier initialization compromises between the two by scaling with the sum of fan-in and fan-out (a forward/backward average, not a harmonic mean of the counts).
- Assumption: It assumes the activation function is linear in the active region (roughly true for the center of Tanh/Sigmoid).
Formula:
\[Var(W) = \frac{2}{n_{in} + n_{out}}\]Drawing from a Uniform distribution: $W \sim U\left[-\sqrt{\frac{6}{n_{in}+n_{out}}}, \sqrt{\frac{6}{n_{in}+n_{out}}}\right]$. This is the scheme from Glorot & Bengio (2010).
B. He (Kaiming) Initialization
Target: ReLU (Rectified Linear Unit) and variants (Leaky ReLU, PReLU).
- The Issue: ReLU is $f(x) = \max(0, x)$, which sets all negative inputs to zero. For a zero-mean symmetric pre-activation $z$, exactly half of its probability mass is zeroed.
The key quantity is the second moment, not the centered variance. He initialization is derived by propagating $\mathbb{E}[a^2]$, the second moment of the activations, because that is what sets the scale of the next pre-activation. For zero-mean symmetric $z$, ReLU halves the second moment exactly:
\[\mathbb{E}[\operatorname{ReLU}(z)^2] = \tfrac{1}{2}\,\mathbb{E}[z^2].\](The centered variance is not exactly halved: because ReLU’s output has a positive mean, $\operatorname{Var}(\operatorname{ReLU}(z)) = \left(\tfrac{1}{2} - \tfrac{1}{2\pi}\right)\operatorname{Var}(z)$. The clean factor of $\tfrac{1}{2}$ is a statement about the second moment, and quietly swapping “variance” for “second moment” is a common slip.)
- The Correction: propagating $\mathbb{E}[a^2]$ from layer to layer, the ReLU’s factor of $\tfrac{1}{2}$ must be cancelled by doubling the weight variance relative to the linear case.
Formula:
\[\operatorname{Var}(W) = \frac{2}{n_{in}}, \qquad W_{ij} \sim \mathcal{N}\left(0, \frac{2}{n_{in}}\right),\]where the second argument of $\mathcal{N}$ is the variance (equivalently, $\operatorname{std}(W) = \sqrt{2/n_{in}}$). For Leaky ReLU or PReLU with negative slope $\alpha$, the derivation carries a gain and the variance becomes $\operatorname{Var}(W) = 2/((1+\alpha^2)\,n_{in})$, so ordinary He is the $\alpha = 0$ case. This is the scheme from He et al. (2015), which also introduced PReLU.
4. Conclusion and Benefits
Good initialization is not merely a technicality; on deep networks it is often the difference between training that gets moving and training that stalls from the first step. But it is a statement about the starting point, and it rests on approximations: independent weights and activations, a symmetric activation, similar moments across units, and an architecture-specific definition of fan-in/out. It sets a good initial scale; it does not by itself guarantee convergence, keep gradients well-behaved for the rest of training, or fix a number of epochs.
Summary of Benefits:
- Symmetry Breaking: random (not constant) initialization ensures neurons in the same layer do not start identical, so they can learn different features. This just needs randomness; He/Xavier scaling is not the only way to get it.
- Stable Signal Propagation at Step Zero: matching the weight variance to the activation (He for ReLU, Xavier for Tanh) keeps forward and backward signal magnitudes in a usable range at initialization.
- A Better Starting Point for the Optimizer: with signals neither vanishing nor exploding initially, the optimizer can take effective early steps. Later stability still depends on the optimizer, the learning rate, and normalization.
Why use Uniform Distribution in Xavier and not Gaussian
This is a common point of confusion. The short answer is: we can use either.
Actually, both He and Xavier initialization have two variants: Normal and Uniform.
- Xavier Normal: Sample from $N(0, \sigma^2)$
- Xavier Uniform: Sample from $U[-limit, +limit]$
The reason we often see the Uniform distribution associated with Xavier (and the Normal with He) is largely historical: the original paper by Glorot & Bengio (2010) used the Uniform distribution for their experiments, while the He et al. (2015) paper focused more on the Normal distribution.
Here is the derivation of those bounds and the reason why we might prefer Uniform.
1. Deriving the Uniform Bounds
We already derived the “Target Variance” needed to maintain signal stability. For Xavier initialization (which averages fan-in and fan-out), the target variance is:
\[Var(W) = \frac{2}{n_{in} + n_{out}}\]If we choose to use a Uniform Distribution bounded between $[-r, r]$, we need to find the value of $r$ that gives us exactly that variance.
Step 1: Variance of a Uniform Distribution For a random variable $X$ uniformly distributed between $[a, b]$, the variance is:
\[Var(X) = \frac{(b - a)^2}{12}\]In our case, the bounds are $[-r, r]$, so $a = -r$ and $b = r$.
\[Var(W) = \frac{(r - (-r))^2}{12} = \frac{(2r)^2}{12} = \frac{4r^2}{12} = \frac{r^2}{3}\]Step 2: Equating the Variances Now we simply set the variance of our distribution equal to the target variance we need for the network.
\[\frac{r^2}{3} = \frac{2}{n_{in} + n_{out}}\]Step 3: Solve for $r$ (the limit) Multiply both sides by 3:
\[r^2 = \frac{6}{n_{in} + n_{out}}\]Take the square root:
\[\mathbf{r = \sqrt{\frac{6}{n_{in} + n_{out}}}}\]This is precisely where the $\sqrt{6}$ comes from. It is simply the “scaling factor” needed to force a uniform distribution to have the same variance as the optimal normal distribution.
2. Uniform versus Normal: matched variance, different tails
As long as the variance matches the target, both distributions work, and the choice is largely an implementation and empirical one rather than a safety rule.
- Normal ($\mathcal{N}$): unbounded in principle, but with the correct small variance (here $\sigma^2 = 2/(n_{in}+n_{out})$, so for a 512-wide layer $\sigma \approx 0.044$) an extreme draw like $+5$ is astronomically unlikely; the earlier worry about “picking a weight of $+5$ or $-10$” simply does not apply at this scale. When rare large draws are a genuine concern, a truncated normal (redrawing samples beyond, say, two standard deviations) is the usual remedy, and Keras’s
he_normal/glorot_normalare in fact truncated by default. - Uniform ($U$): strictly bounded by $\pm r$, which some practitioners prefer, but this is a mild difference in the tails, not a general reason it trains better.
Summary: Pick either. The Normal variants (glorot_normal, he_normal) use variance $\sigma^2 = 2/(n_{in}+n_{out})$ (Xavier) or $2/n_{in}$ (He); the Uniform variants reach the same variance through the bound $r$. The historical pairing (Uniform with Xavier, Normal with He) simply follows each original paper’s experiments.
A Deep Dive into Layer Normalization
Here is a detailed explanation of Layer Normalization (LayerNorm).
1. Motivation and Use Cases
The Original Motivation: Internal Covariate Shift
Batch Normalization was originally motivated by internal covariate shift: the idea that a layer’s input distribution keeps changing as earlier layers update, which forces lower learning rates and careful initialization (Ioffe & Szegedy, 2015). This is worth flagging as the historical framing, not a settled explanation. Later work (Santurkar et al., 2018) found that reducing covariate shift did not account for the benefit, and argued that normalization instead makes the optimization landscape smoother. Either way, normalization empirically stabilizes training; the open question is why.
Why Layer Normalization?
While Batch Normalization (BatchNorm) normalizes across the batch dimension, it has significant limitations:
- Small Batch Sizes: BatchNorm relies on batch statistics. If the batch size is small (e.g., 1 or 2), the estimated mean and variance are noisy, leading to poor training.
- Recurrent Neural Networks (RNNs): In RNNs, the sequence length varies, making it difficult to apply shared statistics across different time steps.
The Solution
Layer Normalization solves this by computing statistics across the feature dimension for a single sample, independent of the rest of the batch. We use Layer Normalization to normalize the features (the numerical values) produced by the hidden units (the neurons) within a specific hidden layer. This makes it:
- Batch Independent: It works perfectly even with a batch size of 1.
- Time-step Independent: It works seamlessly with RNNs and Transformers.
Where is it used?
- NLP & Transformers: It is the standard normalization technique in BERT, GPT, and almost all Transformer architectures.
- Recurrent Networks: Used in LSTMs and GRUs for sequence modeling.
2. Mathematical Formulation and Derivation
Let $x$ be the input vector to the normalization layer for a single sample. Let $H$ be the number of hidden units (features) in that layer. $x = [x_1, x_2, …, x_H]$
The process involves four distinct steps:
Step A: Calculate Mean ($\mu$)
We calculate the mean across all hidden units for the single sample.
\[\mu = \frac{1}{H} \sum_{j=1}^{H} x_j\]Step B: Calculate Variance ($\sigma^2$)
We calculate the variance across the same hidden units.
\[\sigma^2 = \frac{1}{H} \sum_{j=1}^{H} (x_j - \mu)^2\]Step C: Normalize ($\hat{x}$)
We normalize the vector using the calculated statistics. We add a small constant $\epsilon$ (epsilon) inside the square root for numerical stability. It matters in real calculations well beyond exact division-by-zero: when a sample’s features are nearly constant, $\sigma^2$ is tiny, and without $\epsilon$ the normalized values would blow up on what is essentially noise. In low-precision (float16) training $\epsilon$ also guards against underflow of $\sigma^2$, and its placement (inside versus outside the root) differs across frameworks and slightly changes the result.
\[\hat{x}_j = \frac{x_j - \mu}{\sqrt{\sigma^2 + \epsilon}}\]Step D: Scale and Shift ($y$)
To let the layer recover any scale and mean it needs (so normalization does not cost expressive power), we introduce two learnable parameters, applied elementwise:
- $\gamma$ (Gamma): per-feature scale
- $\beta$ (Beta): per-feature shift
Note that $\gamma$ and $\beta$ are vectors of length $H$ (one entry per normalized feature), learned by backpropagation, not shared scalars. They are what let the output move away from zero-mean, unit-variance when that helps.
Which Axes Get Normalized
“Across the feature dimension” needs to be precise once tensors have more than one axis:
- Dense layer, activations shaped $[B, H]$: normalize over $H$, independently for each of the $B$ samples. $\gamma, \beta$ have shape $[H]$.
- Transformer, shaped $[B, T, H]$ (batch, tokens, features): normalize over the final $H$ for each $(b, t)$ token position independently. $\gamma, \beta$ have shape $[H]$.
- Convolutional use is less common; when applied, the normalized axes must be named explicitly (over channels, or channels plus spatial), since “the feature dimension” is ambiguous once spatial axes are present.
3. Training vs. Inference Phase
A key distinction between LayerNorm and BatchNorm is how statistics and parameters are handled during different phases.
How Parameters ($\gamma, \beta$) are Learnt
- Initialization: Typically, $\gamma$ is initialized to vectors of $1$s, and $\beta$ is initialized to vectors of $0$s.
- Training: During backpropagation, the gradients with respect to $\gamma$ and $\beta$ are computed based on the loss function. These parameters are updated by the optimizer (e.g., Adam, SGD) just like weights and biases.
Usage in Training Phase
- For every input sample, $\mu$ and $\sigma$ are calculated dynamically based on the current values of the hidden units.
- The normalization is applied immediately.
Usage in Inference Phase (Crucial Difference)
Unlike Batch Normalization, which uses “running averages” (global statistics) calculated during training for inference:
- Layer Normalization does NOT use running averages.
- Because LayerNorm depends only on the current sample, $\mu$ and $\sigma$ are computed on the fly for every single prediction input during inference.
- This simplifies the deployment pipeline, as there is no need to carry over statistical buffers from the training state.
Because the statistics are computed per sample, LayerNorm computes the same function at training and inference time, with no train/test discrepancy to manage. This equivalence is one of the properties the Layer Normalization paper (Ba, Kiros & Hinton, 2016) highlights as an advantage over BatchNorm.
4. Practical Example with Numbers
Let’s assume we have a single input sample with 3 features (Hidden size $H=3$). We will assume $\epsilon \approx 0$ for simplicity.
Input Vector: $x = [2, 4, 12]$ Learnable Params: $\gamma = [1, 1, 1]$, $\beta = [3, 3, 3]$ (Initialized to 3 for this example).
Step 1: Compute Mean
\[\mu = \frac{2 + 4 + 12}{3} = \frac{18}{3} = 6\]Step 2: Compute Variance
\[\sigma^2 = \frac{(2-6)^2 + (4-6)^2 + (12-6)^2}{3}\] \[\sigma^2 = \frac{(-4)^2 + (-2)^2 + (6)^2}{3}\] \[\sigma^2 = \frac{16 + 4 + 36}{3} = \frac{56}{3} \approx 18.67\]Standard Deviation $\sigma = \sqrt{18.67} \approx 4.32$
Step 3: Normalize ($\hat{x}$)
- Feature 1: $(2 - 6) / 4.32 = -0.92$
- Feature 2: $(4 - 6) / 4.32 = -0.46$
- Feature 3: $(12 - 6) / 4.32 = 1.39$
Normalized Vector $\hat{x} \approx [-0.92, -0.46, 1.39]$
Step 4: Scale and Shift ($y$)
We apply $y = \gamma \hat{x} + \beta$. Since $\gamma=1$ and $\beta=3$:
- Feature 1: $(1 \cdot -0.92) + 3 = 2.08$
- Feature 2: $(1 \cdot -0.46) + 3 = 2.54$
- Feature 3: $(1 \cdot 1.39) + 3 = 4.39$
Final Output: $[2.08, 2.54, 4.39]$
It is tempting to read this as “the range got squeezed toward $\beta$,” but that is not what LayerNorm guarantees. What it guarantees is a specific first and second moment: the normalized vector $\hat{x}$ has mean $\approx 0$ and variance $\approx 1$ (check: the mean of $[-0.92, -0.46, 1.39]$ is $\approx 0$, and its mean square is $\approx 1$). The affine step then rescales and shifts by the learned $\gamma, \beta$: with $\gamma = 1, \beta = 3$ the output happens to land near 3, but a learned $\gamma$ of, say, 10 would spread the values right back out. LayerNorm fixes the mean and variance over the normalized axes; it does not clamp activations into any bounded interval.
5. Beyond Plain LayerNorm
Two variations dominate modern Transformer practice.
RMSNorm
RMSNorm (Zhang & Sennrich, 2019) drops the mean-centering step entirely. It divides by the root-mean-square of the features instead of the standard deviation, and omits $\beta$:
\[\text{RMS}(x) = \sqrt{\frac{1}{H}\sum_{j=1}^{H} x_j^2}, \qquad y_j = \gamma_j \cdot \frac{x_j}{\text{RMS}(x) + \epsilon}.\]Because it skips computing the mean and the recentering, it is cheaper (the paper reports 7-64% speedups) while matching LayerNorm’s quality on many tasks. The bet it makes is that re-scaling, not re-centering, is the part of LayerNorm doing the useful work. RMSNorm is now the default in several large language models (LLaMA, for one).
Pre-LN versus Post-LN
Where the norm sits inside a Transformer block matters for stability:
- Post-LN (the original Transformer): normalization is applied after the residual addition, $\text{LN}(x + \text{Sublayer}(x))$. It can reach strong final quality but often needs learning-rate warmup to train deep stacks without diverging.
- Pre-LN (now more common): normalization is applied inside the residual branch, $x + \text{Sublayer}(\text{LN}(x))$. Keeping a clean, un-normalized residual path makes very deep models train more stably and with less warmup sensitivity.
A Caveat: Normalization Can Erase Useful Scale
Normalization is not free. By fixing each sample’s mean and variance, it discards the overall magnitude of the feature vector, and if that magnitude carried information (say, confidence expressed as activation energy), it is gone. The learnable $\gamma, \beta$ recover some freedom, but the per-sample scale that was normalized away cannot be reconstructed. This is why normalization is placed thoughtfully at chosen points, not sprinkled after every operation.