Deep Learning Primer: A concise introduction to Backprop and Optimizers
1. High-Level Overview: How Deep Learning Models Learn
At its core, a deep learning model is a function approximation machine. It tries to map inputs to outputs by adjusting its internal parameters (weights and biases) to minimize error.
Key Concepts
- The Epoch: One complete pass through the entire training dataset. A single epoch is rarely enough to learn complex patterns; we usually require many epochs.
- The Batch: Since datasets can be massive (millions of images), we cannot feed them all into memory at once. We divide the data into smaller chunks called batches.
- The Forward Pass: The input data flows through the network layers. At each layer, matrix multiplications and activation functions are applied. The network produces a prediction ($\hat{y}$).
- The Backward Pass (Backpropagation): The model compares its prediction ($\hat{y}$) to the actual target ($y$) using a Loss Function (e.g., Mean Squared Error). It then calculates the gradient of this loss with respect to every weight in the network, moving from the output layer back to the input layer.
- Gradient Descent (GD): This is the optimization algorithm. Once we know the gradients (which tell us the direction of the steepest ascent of the error), we move the weights in the opposite direction to reduce the error.
Weight Update Formulation
The fundamental equation for updating a weight parameter $w$ is:
\[w_{t+1} = w_{t} - \eta \cdot \frac{\partial L}{\partial w} = w_{t} - \eta \cdot \nabla{L(w_t)}\]Where:
- $w_{t}$ is the current weight.
- $\eta$ (eta) is the learning rate (step size).
- $\frac{\partial L}{\partial w}$ is the gradient (derivative of the Loss $L$ with respect to weight $w$ at time-step t).
2. Deep Dive into Back-Propagation
First, a separation the rest of this post depends on: backpropagation is not an optimizer. Backprop is reverse-mode automatic differentiation on the computational graph, a bookkeeping procedure that computes the gradient of the loss with respect to every parameter efficiently by reusing intermediate results (it accumulates vector-Jacobian products layer by layer, and correctly sums contributions for shared parameters). What we then do with those gradients, plain gradient descent, momentum, or Adam, is the optimizer’s job in section 4. Backprop is also not tied to any particular loss or activation; we use MSE and Sigmoid below only to make the arithmetic concrete.
Here is the step-by-step derivation of the backprop equations for a neural network with 2 inputs and only 1 hidden layer.
a. The Network Setup & Notation
Let’s define the architecture clearly to match our requirements.
Architecture:
- Input Layer (Layer 0): Two nodes, $x_1$ and $x_2$.
- Hidden Layer (Layer 1): Two nodes, $h_1$ and $h_2$.
- Output Layer (Layer 2): One node, $o_1$.
- Activation Function: We will use Sigmoid ($\sigma$) for the hidden layer and Linear (Identity) for the output layer (standard for regression).
- Loss Function: Mean Squared Error (MSE).
Notation Rule: $w^{[l]}_{ji}$ denotes the weight in layer $l$ connecting source node $i$ to destination node $j$.
- Example: $w^{[1]}_{21}$ connects Input Node 1 ($x_1$) to Hidden Node 2 ($h_2$).
Diagram

b. Forward Pass Equations
Before deriving gradients, we must define how the signal flows forward.
Hidden Layer Calculation:
- Pre-activation: \(z^{[1]}_1 = w^{[1]}_{11}x_1 + w^{[1]}_{12}x_2 + b^{[1]}_1\)
- Pre-activation: \(z^{[1]}_2 = w^{[1]}_{21}x_1 + w^{[1]}_{22}x_2 + b^{[1]}_2\)
- Activation: \(a^{[1]}_1 = \sigma(z^{[1]}_1)\) and \(a^{[1]}_2 = \sigma(z^{[1]}_2)\)
Output Layer Calculation:
- Pre-activation: \(z^{[2]}_1 = w^{[2]}_{11}a^{[1]}_1 + w^{[2]}_{12}a^{[1]}_2 + b^{[2]}_1\)
- Activation (Linear): \(\hat{y} = a^{[2]}_1 = z^{[2]}_1\)
Loss Calculation (squared error):
\[L = \frac{1}{2}(y - \hat{y})^2\](The $\frac{1}{2}$ cancels the exponent during differentiation.) Strictly, this is the half squared error for a single example, not the mean squared error: MSE averages it over a batch or the dataset, $L = \frac{1}{2N}\sum_{n}(y_n - \hat{y}_n)^2$. For one example the two differ only by that averaging constant, which rescales every gradient equally.
c. Back-Propagation Derivation
We want to update the weights to minimize Loss ($L$). We use the Chain Rule to find $\frac{\partial L}{\partial w}$.
Part A: Gradient for Output Layer Weight ($w^{[2]}_{11}$)
This is the weight connecting Hidden Node 1 ($h_1$) to the Output Node.
We decompose the derivative using the chain rule:
\[\frac{\partial L}{\partial w^{[2]}_{11}} = \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z^{[2]}_1} \cdot \frac{\partial z^{[2]}_1}{\partial w^{[2]}_{11}}\]1. Derivative of Loss w.r.t Prediction:
\[\frac{\partial L}{\partial \hat{y}} = \frac{\partial}{\partial \hat{y}} (\frac{1}{2}(y - \hat{y})^2) = -(y - \hat{y})\]2. Derivative of Prediction w.r.t Pre-activation (Linear activation): Since $\hat{y} = z^{[2]}_1$, the derivative is 1.
\[\frac{\partial \hat{y}}{\partial z^{[2]}_1} = 1\]3. Derivative of Pre-activation w.r.t Weight:
\[z^{[2]}_1 = w^{[2]}_{11}a^{[1]}_1 + \dots\] \[\frac{\partial z^{[2]}_1}{\partial w^{[2]}_{11}} = a^{[1]}_1 \quad (\text{The input from the previous layer})\]Final Equation for Output Layer: Combine the terms:
\[\frac{\partial L}{\partial w^{[2]}_{11}} = -(y - \hat{y}) \cdot a^{[1]}_1\]Part B: Gradient for Hidden Layer Weight ($w^{[1]}_{21}$)
This is the weight connecting Input Node 1 ($x_1$) to Hidden Node 2 ($h_2$).
This path is longer. The error must propagate from the Loss $\rightarrow$ Output $\rightarrow$ Hidden Node 2 $\rightarrow$ Weight.
\[\frac{\partial L}{\partial w^{[1]}_{21}} = \frac{\partial L}{\partial z^{[2]}_1} \cdot \frac{\partial z^{[2]}_1}{\partial a^{[1]}_2} \cdot \frac{\partial a^{[1]}_2}{\partial z^{[1]}_2} \cdot \frac{\partial z^{[1]}_2}{\partial w^{[1]}_{21}}\]Let’s calculate each term:
1. The Output Error ($\frac{\partial L}{\partial z^{[2]}_1}$): From Part A, we know this is the error term $\delta^{[2]}$.
\[\frac{\partial L}{\partial z^{[2]}_1} = -(y - \hat{y})\]2. Backpropagate through Hidden-to-Output Weight ($\frac{\partial z^{[2]}_1}{\partial a^{[1]}_2}$): How much does Hidden Node 2 affect the Output Sum?
\[z^{[2]}_1 = w^{[2]}_{11}a^{[1]}_1 + w^{[2]}_{12}a^{[1]}_2 + \dots\] \[\frac{\partial z^{[2]}_1}{\partial a^{[1]}_2} = w^{[2]}_{12}\]3. Derivative of Hidden Activation ($\frac{\partial a^{[1]}_2}{\partial z^{[1]}_2}$): We used the Sigmoid function $\sigma$. The derivative of sigmoid is $\sigma(z)(1-\sigma(z))$.
\[\frac{\partial a^{[1]}_2}{\partial z^{[1]}_2} = \sigma'(z^{[1]}_2)\]4. Derivative of Hidden Pre-activation w.r.t Weight ($\frac{\partial z^{[1]}2}{\partial w^{[1]}{21}}$):
\[z^{[1]}_2 = w^{[1]}_{21}x_1 + w^{[1]}_{22}x_2 + \dots\] \[\frac{\partial z^{[1]}_2}{\partial w^{[1]}_{21}} = x_1\]Final Equation for Hidden Layer: Combine all terms:
\[\frac{\partial L}{\partial w^{[1]}_{21}} = [-(y - \hat{y}) \cdot w^{[2]}_{12} \cdot \sigma'(z^{[1]}_2)] \cdot x_1\]Summary of Updates
To update the weights using Gradient Descent with learning rate $\eta$:
- Output Layer: \(w^{[2]}_{11(new)} = w^{[2]}_{11(old)} - \eta \cdot [-(y-\hat{y}) \cdot a^{[1]}_1]\)
- Hidden Layer: \(w^{[1]}_{21(new)} = w^{[1]}_{21(old)} - \eta \cdot [-(y-\hat{y}) \cdot w^{[2]}_{12} \cdot \sigma'(z^{[1]}_2) \cdot x_1]\)
The Same Thing, Vectorized
Chasing two individual weights is fine for intuition but does not scale. In matrix form the whole backward pass is two “error” vectors $\delta$, one per layer, computed from the output backward:
\[\delta^{[2]} = \hat{y} - y, \qquad \delta^{[1]} = (W^{[2]\top}\delta^{[2]}) \odot \sigma'(z^{[1]}),\]where $\odot$ is elementwise multiplication. (With $L = \frac{1}{2}(y-\hat{y})^2$ and a linear output, $\partial L/\partial z^{[2]} = -(y-\hat{y}) = \hat{y}-y$.) Every weight and bias gradient then reads off these $\delta$’s:
\[\frac{\partial L}{\partial W^{[l]}} = \delta^{[l]}\, a^{[l-1]\top}, \qquad \frac{\partial L}{\partial b^{[l]}} = \delta^{[l]},\]with $a^{[0]} = x$. The bias gradient is simply $\delta$ itself, which the per-weight walk above quietly skipped. This $\delta$ recursion is backpropagation: each layer’s error is the next layer’s error pulled back through the weights and gated by the local activation slope.
3. Why Move Opposite to the Gradient?
Why do we perform $w - \nabla L_w$? Why not plus? Or divide? The Taylor Series approximation states that for a function $L(w)$, the value at a nearby point $w + \Delta(w)$ can be approximated using its value at $w$ as follows:
\[L(w + \Delta(w)) \approx L(w) + \Delta(w) \cdot \nabla{L(w)}\]We want the new loss $L(w + \Delta(w))$ to be lower than the current loss $L(w)$, because only then it makes sense to move in the direction of $\Delta(w)$.
\[L(w + \Delta(w)) < L(w)\]This implies that the term $\Delta(w) \cdot \nabla{L(w)}$ must be negative, and ideally we’ll want this to be as negative as possible to achieve the largest gain. Decomposing this dot product using standard definition we get:
\[\Delta(w) \cdot \nabla{L(w)} = \lVert \Delta(w) \rVert \lVert \nabla{L(w)} \rVert \cos(\alpha)\]- $\alpha$ is the angle between these two vectors.
We’ll need $\cos(\alpha) = -1 \Rightarrow \alpha = 180^{\circ}$. So among all directions of a fixed (Euclidean) length, the steepest local descent points opposite to $\nabla L(w)$. Two caveats keep this honest. First, this is a statement about the first-order approximation: it holds for a sufficiently small step, and a large learning rate can overshoot and increase the loss, because the higher-order terms we dropped stop being negligible. Second, “steepest” is defined relative to the Euclidean norm; measure distance differently and the steepest direction changes. That is exactly the door the adaptive optimizers below walk through: they rescale each coordinate so that a step is “small” in a geometry better matched to the loss surface.
4. Deep Dive into Optimizers
Every optimizer here answers the same question, “given the gradients, how do we step?”, differently. The figure previews the payoff on a deliberately hard surface: a long, narrow ravine, steep across and nearly flat along. Plain gradient descent zig-zags across the steep walls and crawls down the valley floor; momentum and the adaptive methods find smoother, faster routes. We build them up one idea at a time.
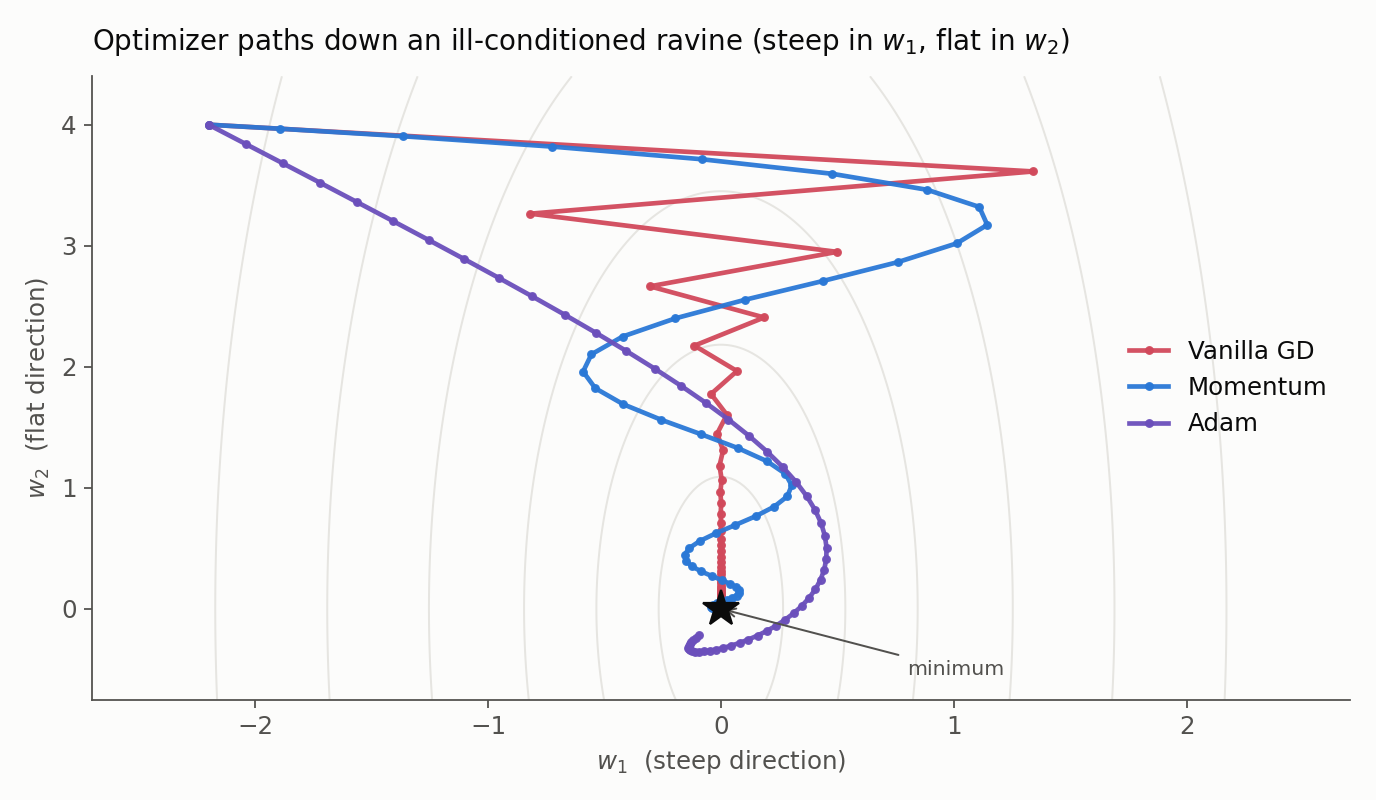
a. Batch vs. Stochastic vs. Mini-Batch GD
Batch Gradient Descent:
- Mechanism: Computes the gradient using the entire dataset to calculate a single update.
- Update Freq: Once per epoch.
- Problem: Extremely slow for large datasets and memory-hungry, since one update needs a full pass. Its updates are also the least noisy, and that lack of gradient noise can leave it lingering near flat regions and saddle points that the noise in stochastic methods would otherwise jostle it out of. (The batching, not saddles per se, is the defining property here.)
Stochastic Gradient Descent (SGD):
- Mechanism: Computes the gradient using a single training example.
- Update Freq: Number of updates = Number of training examples per epoch.
- Solution: Solves the speed and memory issue of Batch GD.
- New Problem: The gradient is very noisy (high variance). The path to the minimum oscillates wildly, making convergence difficult.
Mini-Batch Gradient Descent (The Middle Ground):
- Mechanism: Uses a small batch (e.g., 32, 64, 128 samples).
- Why: It leverages matrix algebra (vectorization) for speed but provides a more stable estimate of the gradient than pure SGD.
- Accumulation: Gradients are averaged over the batch, and the weights are updated once per batch.
b. Momentum-Based GD
- Motivation: In vanilla SGD, if the surface is like a ravine (steep in one direction, flat in another), the optimizer oscillates across the steep slopes and makes slow progress along the valley floor.
Formulation: We introduce a “velocity” term ($v$). We add a fraction ($\gamma$) of the previous update vector to the current one.
\[v_t = \gamma v_{t-1} + \eta \nabla L(w_t)\] \[w_{t+1} = w_t - v_t\]- How the velocity changes over time
- $v_0 = 0$
- $v_1 = \gamma.0 + \eta \nabla L(w_1) = \eta \nabla L(w_1)$
- $v_2 = \gamma.(\eta \nabla L(w_1)) + \eta \nabla L(w_2) = \gamma.\eta \nabla L(w_1) + \eta \nabla L(w_2)$
- $v_3 = \gamma^2.\eta \nabla L(w_1) + \gamma.\eta \nabla L(w_2) + \eta \nabla L(w_3)$
- …
- $v_t = \gamma^{t-1}.\eta \nabla L(w_1) + \gamma^{t-2}.\eta \nabla L(w_2) + … + \eta \nabla L(w_t)$
- Improvement: It builds up speed in directions with consistent gradients and dampens oscillations in noisy directions. It converges faster than vanilla GD.
- Challenge: It acts like a heavy ball rolling down a hill; it gains so much momentum it can overshoot the minimum.
- It oscillates in and out of the minima valley as the momentum carries it out of the valley.
- It takes a lot of u-turns before converging.
c. Nesterov Accelerated Gradient (NAG)
- Motivation: Momentum blindly accelerates. Nesterov tries to be smarter by “looking ahead.”
- Formulation:
- Recall the formulation: \(v_t = \gamma v_{t-1} + \eta \nabla L(w_t)\)
- We know we’re going to move by at-least $\gamma v_{t-1}$ and then a bit more by $\eta \nabla L(w_t)$.
- Instead of calculating the gradient at the current position $w_t$ at time-step $t$, why not calculate the gradient at $w_{look-ahead}$ where $w_{look-ahead} = w_t - \gamma v_{t-1}$?
- Improvement: If the momentum is about to carry us up the other side of the valley (overshooting), the “look-ahead” gradient will point back, correcting the velocity sooner.
- Challenge: Still requires manual tuning of the learning rate.
d. Adagrad (Adaptive Gradient)
- Motivation: A single learning rate may not be the best fit for all surfaces. Different parameters need different learning rates. Infrequent parameters (sparse data) require larger updates, while frequent ones need smaller updates. So, it would be great to have a learning rate which can adapt to the gradient.
- Usual Tips for Annealing LR
- Halve the LR every $n$ epochs.
- Reduce the LR when validation loss stops improving, using a patience window and a minimum-improvement threshold (the “reduce on plateau” idea), not a knee-jerk halving after any single worse epoch, which noise alone can trigger.
- Exponential decay: $\eta_t = \eta_0 e^{-kt}$ (equivalently $\eta_t = \eta_0 \gamma^t$ with $0 < \gamma < 1$), where $\eta_0$ and $k$ (or $\gamma$) are hyper-parameters and $t$ is the time-step.
- $1/t$ decay: $\eta_t = \frac{\eta_0}{1 + kt}$, where $\eta_0$ and $k$ are hyper-parameters and $t$ is the time-step.
- Intuition: For a sparse feature, the gradient update would be very small. This is a problem if the feature is important (e.g. is_director = Nolan). This would mean $\nabla w = 0$ for most dataset. So, it’ll be good to have a different LR for each parameter which takes care of frequency of features. So, our intuition is to decay the LR for parameters in proportion to their update history.
Formulation:
\[v_t = v_{t-1} + (\nabla L(w_t))^2\] \[w_{t+1} = w_t - \frac{\eta}{\sqrt{v_t + \epsilon}} \cdot \nabla L_{w_t}\]- How the velocity changes over time
- $v_0 = 0$
- $v_1 = (\nabla L(w_1))^2$
- $v_2 = (\nabla L(w_1))^2 + (\nabla L(w_2))^2$
- …
- $v_t = (\nabla L(w_1))^2 + (\nabla L(w_2))^2 + … + (\nabla L(w_t))^2$
- Improvement: Eliminates the need to manually tune the learning rate for every parameter.
- Sparse Features
- Appears rarely $\Rightarrow$ Gradient is often zero $\Rightarrow$ Accumulator $v_t$ grows slowly.
- Denominator stays small $\Rightarrow$ Effective LR stays large, preventing them from dying out.
- Dense Features
- Appears in many batches $\Rightarrow$ Gradient is mostly non-zero $\Rightarrow$ Accumulator $v_t$ grows very quickly (sum of non-zero squares).
- Denominator becomes large $\Rightarrow$ Effective LR shrinks, forcing it to take smaller, more conservative steps.
- Sparse Features
- Challenge: $v_t$ accumulates positive terms forever, so it grows without bound and the effective learning rate $\eta/\sqrt{v_t}$ shrinks monotonically toward zero. In a long run this can make updates so small that learning effectively stalls before reaching a good solution. (The denominator does not literally become infinite in finite training; the practical problem is the steady, irreversible shrinkage.)
e. RMSProp (Root Mean Square Propagation)
- Motivation: Fix Adagrad’s “decaying learning rate” problem by decaying the denominator.
Formulation: Instead of a cumulative sum, it uses an Exponential Moving Average of squared gradients. It “forgets” old history.
\[v_t = \beta v_{t-1} + (1-\beta)(\nabla L(w_t))^2\]- Usually $\beta \ge 0.9$
- How the velocity changes over time
- $v_0 = 0$
- $v_1 = (1 - \beta)(\nabla L(w_1))^2$
- $v_2 = \beta(1 - \beta)(\nabla L(w_1))^2 + (1 - \beta)(\nabla L(w_2))^2$
- …
- $v_t = \beta^{t-1}(1 - \beta)(\nabla L(w_1))^2 + \beta^{t-2}(1 - \beta)(\nabla L(w_2))^2 + … + (1 - \beta)(\nabla L(w_t))^2$
- In general: $v_t = (1 - \beta)\sum_{k=1}^{t}\beta^{t - k}(\nabla L(w_k))^2$
- Improvement: Learning rate adapts but doesn’t vanish.
- Because $0 < \beta < 1$, $\beta^{t - k} \rightarrow 0$ as $t \rightarrow \infty$. So, very old gradients almost vanish.
- If gradients have roughly constant magnitude, RMSProp stabilizes.
- Assume $(\nabla L(w_t))^2 \approx G$
- Our velocity equation becomes: \(v_t = \beta v_{t-1} + (1-\beta)G\)
- If training goes on for a long time, $t \rightarrow \infty$.
- $v_\infty = \beta v_\infty + (1 - \beta)G \Rightarrow v_\infty = G$
- Challenge: It adapts per-parameter scales from the running average of squared gradients but keeps no momentum-like average of the raw gradients (unless we add one separately), so it misses momentum’s acceleration and oscillation-damping in ravines.
- A note on naming: this $v_t$ is an exponential average of squared gradients, not the statistical variance, because the squared mean is never subtracted. It tracks typical gradient magnitude, not spread around a mean.
- A note on the zero start: initializing $v_t$ at 0 biases it low early on. On its own, a smaller denominator makes the first normalized steps larger, not smaller, though the net effect depends on $\epsilon$, the current gradient, and whether momentum is added. Adam (next) tackles this bias head-on with an explicit correction.
f. Adam (Adaptive Moment Estimation)
- Motivation: Combine the best of both worlds: Momentum (First moment) and RMSProp (Second moment).
- Formulation:
- Calculate Momentum (Mean): $m_t = \beta_1 m_{t-1} + (1-\beta_1)\nabla L(w_t)$
- Calculate Variance (RMSProp): $v_t = \beta_2 v_{t-1} + (1-\beta_2)(\nabla L(w_t))^2$
Bias Correction: Since $m$ and $v$ start at 0, they are biased toward 0 initially. We correct this:
\[\hat{m}_t = \frac{m_t}{1-\beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1-\beta_2^t}\]Update:
\[w_{t+1} = w_{t} - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \cdot \hat{m}_t\]
- Rationale behind Bias Correction
- Note that we’re taking a running average of the gradients ($m_t$) in the weight update procedure instead of the true gradient $\nabla L(w_t)$ [ignoring the bias correction part]. Reason being, we don’t want to rely too much on the current gradient and utilize the overall behaviour of the past gradients over many time steps.
- So, we’re more interested in $E(\nabla L(w_t))$ and not on a single point-estimate $\nabla L(w_t)$ computed at time $t$.
- However, instead of computing $E(\nabla L(w_t))$, we are computing $m_t$ as the EMA.
- Ideally we’d want $E(m_t) = E(\nabla L(w_t))$
Bias Correction Formula Derivation
\(m_t = (1 - \beta)\sum_{i=1}^t\beta^{t - i}g_i\) where $g_i = \nabla L(w_i)$
\[\Rightarrow E(m_t) = (1 - \beta)\sum_{i=1}^t E[\beta^{t - i} g_i]\] \[\Rightarrow E(m_t) = (1 - \beta)\sum_{i=1}^t \beta^{t - i} E(g_i)\]
\(\Rightarrow E(m_t) = E[(1 - \beta)\sum_{i=1}^t\beta^{t - i}g_i]\)Assumption: All $g_i$s are from the same distribution, i.e. $E(g_i) = E(g), \forall i$
\[\Rightarrow E(m_t) = (1 - \beta) \cdot E(g) \cdot \sum_{i=1}^t \beta^{t - i}\] \[\Rightarrow E(m_t) = (1 - \beta) \cdot E(g) \cdot \frac{1 - \beta^t}{1 - \beta}\] \[\Rightarrow E(m_t) = E(g) \cdot (1 - \beta^t)\]That’s why we divide $m_t$ by $(1 - \beta^t)$ to get $\hat{m}_t$. The same argument applies to $v_t$ and $\hat{v}_t$ (with $\beta_2$).
A quick numerical check. It is tempting to say the uncorrected moments make the first steps “too small.” They do not, because both the numerator and denominator are biased. Take a constant gradient $g = 0.1$ with the defaults $\beta_1 = 0.9$, $\beta_2 = 0.999$. At step 1 the uncorrected moments are $m_1 = 0.01$ and $v_1 = 10^{-5}$, so the raw direction $m_1/\sqrt{v_1} = 3.16$ is over-sized. The corrections divide by $1-\beta_1 = 0.1$ and $1-\beta_2 = 0.001$, giving $\hat{m}_1 = 0.1$ and $\hat{v}_1 = 0.01$, so the corrected step $\hat{m}_1/\sqrt{\hat{v}_1} = 1$ matches the gradient’s own scale. Here the uncorrected step is roughly $3\times$ too large, not too small; bias correction is what makes the effective step behave sensibly from step one.
- Improvement: Generally the default optimizer for most deep learning tasks. It is fast, stable, and handles sparse gradients well.
- Momentum (first moment) reduces noise and speeds up along consistent directions.
- Adaptive scaling (second moment) normalizes coordinates with different gradient magnitudes (helps with ill-conditioning and sparse/dense feature imbalance).
- Bias-correction removes the zero-initialization bias in both moments, so early steps use unbiased magnitude estimates (see the numerical check above).
- Empirically, Adam converges faster and more stably across many problems with the default betas $\beta_1 = 0.9$, $\beta_2 = 0.999$, $\epsilon = 10^{-8}$ from the original Adam paper (Kingma & Ba, 2015). Frameworks differ in exactly where they place $\epsilon$, and variants adjust these choices.
- Challenge:
- Generalization gap: Adam can converge faster but sometimes yields worse generalization compared to SGD with momentum; not a silver bullet.
- Non-convergence pathologies: Under some circumstances Adam’s adaptive steps can cause non-convergent behavior. Variants (AMSGrad, AdamW, AdaBound, RAdam, etc.) address some of these issues.
- Weight decay handling: for plain SGD, adding an L2 penalty to the loss and multiplicatively shrinking the weights each step are equivalent after matching coefficients. Under Adam’s per-coordinate rescaling they are not equivalent: an L2 term gets divided by $\sqrt{\hat{v}_t}$ along with the rest of the gradient, so high-gradient coordinates are effectively decayed less. AdamW (Loshchilov & Hutter, 2019) decouples the decay, applying it directly to the weights outside the adaptive step. It is a change of formulation, not a bug fix.
5. What Came After Adam?
Since Adam (2014), many optimizers have targeted its known weaknesses: a sometimes-worse generalization than SGD, instability in specific regimes, and memory cost. None is a universal upgrade. Each is an empirical starting point whose benefit depends on the architecture, task, batch size, and tuning budget, so the table sketches the core idea and the honest trade-off rather than crowning winners, with links to the primary papers.
| Optimizer | What it does | Reported strength | Caveat |
|---|---|---|---|
| AdamW | Decouples weight decay from the adaptive step, applying it straight to the weights | Often better generalization; a common default for training Transformers | Weight-decay strength is a real hyperparameter to tune |
| RAdam | Rectifies the adaptive learning rate’s high variance in the first few steps (an automatic warmup) | Can stabilize early training and reduce warmup sensitivity | Not a universal warmup replacement; later behaviour reverts to Adam’s |
| AMSGrad | Uses the running maximum of past squared gradients so the effective step never grows | Restores a convergence guarantee Adam lacks, under the paper’s (convex) assumptions | Often no better, sometimes worse, in practice; the max can over-shrink steps |
| Nadam (Dozat, 2016) | Folds Nesterov look-ahead momentum into Adam | Can converge a little faster on some problems | Slightly more computation; no fix for the generalization gap |
| Lookahead | A wrapper over any optimizer: “fast” weights explore, “slow” weights follow every $k$ steps | Reduces inner-optimizer variance and can improve stability | Adds two hyperparameters ($k$, slow-step size) and a weight copy |
| LAMB | Normalizes the update layer-wise so the LR can scale to very large batches | Enables large-batch training (e.g. BERT at batch 32k) | Aimed at the large-batch regime; overkill and less tested for small batches |
| Lion | Drops the second moment entirely; updates by the sign of the momentum | Lower optimizer-state memory (no second moment) and fewer ops per step | Needs a much smaller LR (roughly 3-10x) and is sensitive to batch noise |
A word on Lion’s memory claim: the saving is in optimizer state (it stores one moment vector instead of Adam’s two), which is separate from the memory used by parameters, gradients, and activations. Whether that shrinks peak training memory depends on the whole budget, not the optimizer alone.
6. The Recipe Around the Optimizer
The optimizer’s name is only part of a training recipe, and often not the most important part: a tuned SGD-with-momentum can match or beat a carelessly configured Adam. The pieces that usually matter as much as the choice of optimizer:
- Base learning rate. The single highest-leverage hyperparameter. Search it on a log scale (for example a short LR-range test) rather than trusting a default.
- Warmup and decay schedule. Ramp the LR up over the first few hundred to few thousand steps, then decay it (cosine or linear). Warmup tames the high-variance early updates; decay sharpens the final convergence.
- Batch size and gradient accumulation. Larger batches give less noisy gradients and usually want a larger LR, up to a point. When memory is the limit, accumulate gradients over several micro-batches to simulate a larger batch.
- Gradient clipping. Cap the global gradient norm (a threshold such as $1.0$) to survive the occasional exploding-gradient spike, especially in RNNs and Transformers.
- Weight-decay exclusions. Apply weight decay to weight matrices, but typically not to biases and normalization parameters (LayerNorm/BatchNorm scales and shifts); decaying those usually hurts.
- Mixed-precision loss scaling. In float16 training, tiny gradients underflow to zero. Multiply the loss by a large factor before backprop and divide it out before the update (dynamic loss scaling) to keep them representable.
- What to monitor. Track the gradient norm and the ratio of update size to weight size per layer (a healthy ratio is often around $10^{-3}$). Both reveal a bad learning rate faster than the loss curve alone.
- How to compare fairly. Judge optimizers at equal compute budget, each with its own LR tuned, and on validation performance. The first optimizer to drive the training loss down is not automatically the best; it may just be overfitting faster.