Deep Learning Primer: RNN & LSTM
Recurrent networks process a sequence one step at a time, reusing the same weights at every step, which is what “recurrence” means. That weight sharing is what lets them handle variable-length sequences, and it is also what makes their gradients tricky. This post derives Backpropagation Through Time (BPTT), shows why plain RNN gradients vanish or explode, and how LSTM and GRU gating gives the gradient a controllable path through time.
Notation. In the RNN section, $S_t$ is the hidden state and $\sigma$ is a generic squashing activation (tanh or logistic). In the LSTM/GRU sections, $\sigma$ specifically means the logistic sigmoid used for gates, $\tanh$ is written explicitly, $S_t$ is the cell state (written $C_t$ in most LSTM literature), and $h_t$ is the hidden state (the output). All gates ($f_t, i_t, o_t, z_t, r_t$) are vectors the same size as the state, and $\odot$ is element-wise multiplication.
Let’s understand BPTT algorithm in RNN

Derivation of Gradients in RNNs
1. Gradient Flow
\[\frac{\partial L_t(\theta)}{\partial W} = \underbrace{\frac{\partial L_t(\theta)}{\partial S_t}}_{\text{straight-forward}} \cdot \overbrace{\frac{\partial S_t}{\partial W}}^{\text{How to compute this?}}\]The Challenge: How do we compute $\frac{\partial S_t}{\partial W}$?
Recall the state update equation:
\[S_t = \sigma(U x_t + W S_{t-1} + b)\]We cannot simply treat $S_{t-1}$ as a constant because it also depends on $W$.
In such networks, the total derivative $\frac{\partial S_t}{\partial W}$ has 2 parts:
- Explicit: $\frac{\partial^+ S_t}{\partial W}$, treating all other inputs (like $S_{t-1}$) as constants.
- Implicit: Summing over all indirect paths from $S_t$ to $W$.
2. Recursive Expansion
We can expand the derivative as follows:
\[\frac{\partial S_t}{\partial W} = \underbrace{\frac{\partial^+ S_t}{\partial W}}_{\text{exp.}} + \underbrace{\frac{\partial S_t}{\partial S_{t-1}} \frac{\partial S_{t-1}}{\partial W}}_{\text{imp.}}\]Substituting $\frac{\partial S_{t-1}}{\partial W}$ recursively:
\[= \frac{\partial^+ S_t}{\partial W} + \frac{\partial S_t}{\partial S_{t-1}} \left[ \frac{\partial^+ S_{t-1}}{\partial W} + \frac{\partial S_{t-1}}{\partial S_{t-2}} \frac{\partial S_{t-2}}{\partial W} \right]\]Completely expanding results in a sum of terms:
\[= \frac{\partial^+ S_t}{\partial W} + \frac{\partial S_t}{\partial S_{t-1}} \frac{\partial^+ S_{t-1}}{\partial W} + \frac{\partial S_t}{\partial S_{t-1}} \frac{\partial S_{t-1}}{\partial S_{t-2}} \frac{\partial^+ S_{t-2}}{\partial W} + ... + \frac{\partial S_t}{\partial S_{t-1}} \frac{\partial S_{t-1}}{\partial S_{t-2}}...\frac{\partial S_2}{\partial S_1} \frac{\partial^+ S_1}{\partial W}\]Backpropagation Through Time (BPTT)
For simplicity, we are going to “short-circuit” some of the paths notation. Let $\frac{\partial S_t}{\partial S_t} = 1$.
\[\frac{\partial S_t}{\partial W} = \frac{\partial^+ S_t}{\partial W} + \frac{\partial S_t}{\partial S_{t-1}} \frac{\partial^+ S_{t-1}}{\partial W} + \frac{\partial S_t}{\partial S_{t-1}} \frac{\partial S_{t-1}}{\partial S_{t-2}} \frac{\partial^+ S_{t-2}}{\partial W} + ... + \frac{\partial S_t}{\partial S_{t-1}} \frac{\partial S_{t-1}}{\partial S_{t-2}}...\frac{\partial S_2}{\partial S_1} \frac{\partial^+ S_1}{\partial W}\] \[= \sum_{k=1}^{t} \frac{\partial S_t}{\partial S_k} \frac{\partial^+ S_k}{\partial W}\]In General:
For a loss at time $t$, $L_t(\theta)$:
\[\frac{\partial L_t(\theta)}{\partial W} = \frac{\partial L_t(\theta)}{\partial S_t} \times \left[ \sum_{k=1}^{t} \frac{\partial S_t}{\partial S_k} \cdot \frac{\partial^+ S_k}{\partial W} \right] \quad \text{--- (Eq 1)}\]This algorithm is called BPTT (Backpropagation Through Time). Two things are worth making explicit. First, $\frac{\partial^+ S_k}{\partial W}$ is the immediate partial: the derivative of $S_k$ with respect to $W$ treating the incoming state $S_{k-1}$ as a constant, as opposed to the full $\frac{\partial S_k}{\partial W}$ that also flows back through $S_{k-1}$. Second, a real training objective is usually a total loss over the sequence, $L = \sum_{t=1}^{T} \ell_t$ (or a loss at selected steps: one final step for many-to-one tasks, every step for many-to-many). Because $W$ is shared across all time steps, its full gradient sums the per-step contributions above over every $t$: $\frac{\partial L}{\partial W} = \sum_t \frac{\partial \ell_t}{\partial W}$. BPTT is exactly reverse-mode differentiation on this one unrolled graph, not a separate derivative per step.
Exploding / Vanishing Gradient
In Equation 1, let’s focus on the term $\frac{\partial S_t}{\partial S_k}$. By the chain rule across time steps:
\[\frac{\partial S_t}{\partial S_k} = \frac{\partial S_t}{\partial S_{t-1}} \cdot \frac{\partial S_{t-1}}{\partial S_{t-2}} \cdot \dots \cdot \frac{\partial S_{k+1}}{\partial S_k} = \prod_{j=k+1}^{t} \frac{\partial S_{j}}{\partial S_{j-1}}\]Let’s look at the individual terms using the forward pass definitions:
- $a_j = W S_{j-1} + U x_j + b$
- $S_j = \sigma(a_j)$
The derivative using the chain rule is:
\[\frac{\partial S_j}{\partial S_{j-1}} = \frac{\partial S_j}{\partial a_j} \cdot \frac{\partial a_j}{\partial S_{j-1}} = \frac{\partial S_j}{\partial a_j} \cdot W\]Where:
- $a_j = [a_{j1}, a_{j2}, \dots, a_{jd}]$
- $S_j = [\sigma(a_{j1}), \sigma(a_{j2}), \dots, \sigma(a_{jd})]$
The Jacobian Matrix:
The term $\frac{\partial S_j}{\partial a_j}$ is a diagonal matrix containing the derivatives of the activation function:
\[\frac{\partial S_j}{\partial a_j} = \begin{bmatrix} \frac{\partial S_{j1}}{\partial a_{j1}} & & \\ & \frac{\partial S_{j2}}{\partial a_{j2}} & \\ & & \ddots \\ & & & \frac{\partial S_{jd}}{\partial a_{jd}} \end{bmatrix} = \begin{bmatrix} \sigma'(a_{j1}) & & \\ & \sigma'(a_{j2}) & \\ & & \ddots \\ & & & \sigma'(a_{jd}) \end{bmatrix}\] \[\frac{\partial S_j}{\partial S_{j-1}} = \text{diag}(\sigma'(a_j)) \cdot W\]Part A: The “Why” - Derivative of a Vector w.r.t. a Vector
To understand how and why the Jacobian matrix appears here, we need to break down the derivative of a vector function with respect to another vector.
In single-variable calculus, if we have $y = f(x)$, the derivative is a single number (scalar). However, in an RNN:
- Input: $S_{j-1}$ is a hidden state vector of size $(d \times 1)$.
- Output: $S_j$ is the next hidden state vector of size $(d \times 1)$.
When we ask, “How does the output vector change when I nudge the input vector?”, we aren’t asking one question. We are asking $d \times d$ questions:
- How does output unit 1 change when I nudge input unit 1?
- How does output unit 1 change when I nudge input unit 2?
- …and so on.
The collection of all these partial derivatives is the Jacobian Matrix. Since input and output are both dimension $d$, the resulting matrix must be $(d \times d)$.
Part B: The Activation Part ($\frac{\partial S_j}{\partial a_j}$)
This is where the diagonal matrix comes from. Recall:
\[S_j = \sigma(a_j)\]Crucially, activations in a standard layer are element-wise.
- The activation of neuron 1 ($S_{j,1}$) depends only on the pre-activation of neuron 1 ($a_{j,1}$).
- Changing $a_{j,2}$ has zero effect on $S_{j,1}$.
If we write out the Jacobian matrix for this part:
\[\frac{\partial S_j}{\partial a_j} = \begin{bmatrix} \frac{\partial S_{j,1}}{\partial a_{j,1}} & \frac{\partial S_{j,1}}{\partial a_{j,2}} & \dots \\ \frac{\partial S_{j,2}}{\partial a_{j,1}} & \frac{\partial S_{j,2}}{\partial a_{j,2}} & \dots \\ \vdots & \vdots & \ddots \end{bmatrix}\]Because of the element-wise independence:
- Off-diagonal terms (like $\frac{\partial S_{j,1}}{\partial a_{j,2}}$) are 0.
- Diagonal terms (like $\frac{\partial S_{j,1}}{\partial a_{j,1}}$) are simply the scalar derivative of the activation function, denoted as $\sigma’(a_{j,1})$.
This results in a Diagonal Matrix of size $(d \times d)$:
\[\frac{\partial S_j}{\partial a_j} = \text{diag}(\sigma'(a_j))\]Part C: Putting it together
Now we multiply Part B and Part A (Matrix multiplication):
\[\frac{\partial S_j}{\partial S_{j-1}} = \underbrace{\text{diag}(\sigma'(a_j))}_{\text{Part B (d x d)}} \cdot \underbrace{W}_{\text{Part A (d x d)}}\]Back to the derivation Taking the norm of both sides for our original equation:
\[\frac{\partial S_j}{\partial S_{j-1}} = \text{diag}(\sigma'(a_j)) \cdot W\] \[\Rightarrow \lVert \frac{\partial S_j}{\partial S_{j-1}} \rVert = \lVert \text{diag}(\sigma'(a_j)) \cdot W \rVert\]Using the sub-multiplicative property of matrix norms:
\[\lVert \text{diag}(\sigma'(a_j)) \cdot W \rVert \le \| \text{diag}(\sigma'(a_j)) \| \cdot \| W \|\]Bounding the Activation Derivative: We define an upper bound $\gamma$ for the derivative of the activation function:
- $\sigma’(a_j) \le \frac{1}{4} = \gamma$ [if $\sigma$ is logistic]
- $\sigma’(a_j) \le 1 = \gamma$ [if $\sigma$ is tanh]
Substituting this back into the inequality (and letting $\lVert W \rVert = \lambda$, the operator/spectral norm of $W$, not an eigenvalue):
\[\Rightarrow \left\| \frac{\partial S_j}{\partial S_{j-1}} \right\| \le \gamma \cdot \| W \| = \gamma \cdot \lambda\]The Product over Time Steps: Now, looking at the total gradient across time steps from $k$ to $t$:
\[\Rightarrow \left\| \frac{\partial S_t}{\partial S_k} \right\| = \left\| \prod_{j=k+1}^{t} \frac{\partial S_j}{\partial S_{j-1}} \right\| \le \prod_{j=k+1}^{t} \gamma \lambda = (\gamma \lambda)^{t-k}\]Conclusions (read carefully, it is a one-sided bound):
- If $(\gamma \cdot \lambda) < 1$, this upper bound decays geometrically, which guarantees the gradient contribution from far-back steps shrinks toward zero: a genuine vanishing gradient.
- If $(\gamma \cdot \lambda) > 1$, the bound grows, but that only says explosion is possible, it does not prove it. The bound is an upper limit, not the actual value; the true product depends on time-varying Jacobians, how their singular vectors align, activation saturation, and cancellation between terms. So a large bound flags the risk of exploding gradients, not a certainty.
Managing the Two Failure Modes
These are distinct problems needing distinct tools.
- Truncated BPTT restricts backpropagation to the last $\tau$ steps (detaching the hidden state at the truncation boundary so gradients do not flow past it). This bounds compute and memory, but note what it does not do: it deliberately stops gradients from crossing the horizon, so it cannot learn dependencies longer than $\tau$. It trades long-range credit assignment for tractability.
- Gradient clipping rescales the gradient when its norm exceeds a threshold. This is a fix for exploding gradients only; it does nothing for vanishing ones (scaling a near-zero gradient up just amplifies noise).
- Vanishing gradients need structural help instead: gated cells (LSTM/GRU, below), orthogonal or unitary initialization of the recurrent matrix (keeping $\lVert W \rVert$ near 1), residual/skip connections, and normalization. These are what actually extend the reachable time horizon.
How LSTM/GRU improve over RNN
The Problem with Standard RNNs
- Global History: The state $S_t$ is responsible for capturing information from all previous time steps.
- Constant Transformation: At every time step, the entire existing memory $S_{t-1}$ is transformed (and potentially distorted) by the new input $x_t$ and weights $W$.
- Loss of Context: After $t$ steps, the information originally stored at step $t-k$ has been transformed so many times that the original signal is effectively lost. This makes it impossible for the network to learn long-term dependencies.
- Gradient Issues: This forward-pass instability manifests mathematically during Backpropagation as the Vanishing or Exploding Gradient problem, preventing the network from learning how to correct errors from the distant past.
The Whiteboard Analogy (Fixed Memory)
Here is the step-by-step evolution from a standard RNN to an LSTM, using a Whiteboard Theorem Proving analogy to explain the logic.
In this analogy:
- The Whiteboard ($S_{t-1}$): Contains the mathematical proofs and lemmas derived up to the previous step.
- The New Input ($x_t$): A new logical axiom or observation introduced at the current step.
Recall that the original RNN equations were:
\[S_t = \sigma(U.x_t + W.S_{t-1} + b)\] \[y_t = O(V.S_t + c)\]Phase 1: Selective Forget (The Eraser)
The Analogy: We look at the whiteboard full of equations from yesterday ($S_{t-1}$). Before we start proving today’s part of the theorem, we realize that “Lemma 3,” derived yesterday, was a logical dead-end or is irrelevant to the new direction the proof is taking.
- Action: We grab the eraser and wipe out “Lemma 3,” but we keep “Lemma 1” and “Lemma 2” because they are still useful.
- Why: If we don’t erase the bad logic, it will confuse our new derivation.
The Equation Evolution: In a standard RNN, the previous state $S_{t-1}$ is multiplied by a weight matrix $W$, which “morphs” the entire memory. It doesn’t have a specific mechanism to just “keep” or “drop” exact items.
To fix this, we add a Forget Gate ($f_t$). This is a vector of numbers between 0 and 1.
0= Completely erase.1= Keep perfectly.
Modified RNN Equation:
\[S_t = \underbrace{f_t \odot S_{t-1}}_{\text{Selective Forget}} + \dots\](We are not adding new info yet; we are just cleaning up the old state.)
Phase 2: Selective Write (The Marker)
The Analogy: Now that the board is clean, we analyze the new input axiom ($x_t$). We derive a new intermediate conclusion (Candidate $\tilde{S}_t$).
- Action: We don’t immediately write this new conclusion in permanent marker. First, we check if it is strong and valid.
- If the new conclusion is weak (noise), we write very faintly or not at all.
- If it is a breakthrough, we write it boldly next to the old lemmas we kept.
- Why: We only want to write information that adds value to the proof.
The Equation Evolution: In a standard RNN, the new input is forced into the state: $+ \sigma(U x_t)$. We have no choice but to add it.
To fix this, we create a Candidate State ($\tilde{S}_t$) (the draft) and an Input Gate ($i_t$) (the decision to write).
Modified RNN Equation:
\[S_t = \underbrace{(f_t \odot S_{t-1})}_{\text{Cleaned Old Memory}} + \underbrace{(i_t \odot \tilde{S}_t)}_{\text{Selective Write}}\]- \(\tilde{S}_t = \tanh(W h_{t-1} + U x_t)\) (The proposed new content)
- $i_t$ (a vector of values in $[0,1]$, one per cell dimension: how much of each proposed value to write)
Phase 3: Selective Read (The Presentation)
The Analogy: We have now updated the board. It contains the preserved old lemmas plus the new breakthrough.
- Action: A student raises their hand and asks, “What is the current result?”
- Analysis: The board contains everything: intermediate steps, scratchpad notes, and the final result. We don’t read the whole board to the student. We filter the information and only speak out (Read) the parts that answer the specific question.
- Why: The internal memory (Whiteboard) should be rich and detailed, but the output (what we say) should be concise and relevant.
The Equation Evolution: In a standard RNN, the output $y_t$ is usually just a function of the whole state $S_t$.
To fix this, we distinguish between the Internal Cell State ($S_t$) (the actual whiteboard) and the Hidden State ($h_t$) (what we actually output/pass to the next step). We use an Output Gate ($O_t$).
Modified RNN Equation:
\[h_t = \underbrace{O_t \odot \tanh(S_t)}_{\text{Selective Read}}\]- $S_t$: The full, messy whiteboard.
- $h_t$: The clean, filtered report given to the outside world (and passed as “previous context” to the next time step).
Summary: The Complete LSTM Block
By combining these three logical steps, we transform the single RNN update line into the LSTM system:
- Forget: $f_t \odot S_{t-1}$ (Clean the past)
- Write: $+ i_t \odot \tilde{S}_t$ (Add the future)
- Read: $h_t = O_t \odot \tanh(S_t)$ (Report the result)

Understanding the Equations
Here are the complete equations for the LSTM unit, following the Forget $\rightarrow$ Write $\rightarrow$ Read sequence established in our Whiteboard analogy.
We have used the standard notation where $S_t$ is the Cell State (the Whiteboard) and $h_t$ is the Hidden State (the Report/Output).
1. Selective Forget (The Eraser)
First, we calculate the Forget Gate vector ($f_t$). This looks at the previous output ($h_{t-1}$) and current input ($x_t$) to decide which parts of the old whiteboard ($S_{t-1}$) are no longer relevant.
The Decision ($f_t$): A vector of values between 0 (completely erase) and 1 (keep everything).
\[f_t = \sigma(W_f \cdot h_{t-1} + U_f \cdot x_t + b_f)\]The Operation: We multiply the old state by this vector element-wise.
\[S_{t(\text{cleaned})} = f_t \odot S_{t-1}\]
2. Selective Write (The Marker)
Next, we determine what new information to add. This has two parts: creating the “draft” of new info (Candidate) and deciding how strongly to write it (Input Gate).
The “Draft” (Candidate $\tilde{S}_t$): The raw new information derived from the current input.
\[\tilde{S}_t = \tanh(W_c \cdot h_{t-1} + U_c \cdot x_t + b_c)\](Note: Standard LSTMs use $\tanh$ here to allow for negative values).
The “Pressure” (Input Gate $i_t$): Decides which parts of the draft are worth writing.
\[i_t = \sigma(W_i \cdot h_{t-1} + U_i \cdot x_t + b_i)\]The Operation (Update Cell State): We add the filtered new info to our cleaned old state.
\[S_t = \underbrace{(f_t \odot S_{t-1})}_{\text{Forget Old}} + \underbrace{(i_t \odot \tilde{S}_t)}_{\text{Write New}}\]
3. Selective Read (The Presentation)
Finally, we have the updated whiteboard ($S_t$). Now we must decide what to reveal to the outside world as the output ($h_t$).
The Filter (Output Gate $O_t$): Decides which parts of the internal state are relevant to the immediate task.
\[O_t = \sigma(W_o \cdot h_{t-1} + U_o \cdot x_t + b_o)\]The Operation (Calculate Hidden State): We squash the cell-state values into $[-1, 1]$ with $\tanh$ (this bounds them, it does not normalize to zero mean and unit variance) and then filter them through the output gate.
\[h_t = O_t \odot \tanh(S_t)\]
Summary of Variables
- $x_t$: Input vector at time $t$.
- $h_{t-1}$: Previous hidden state (output).
- $S_{t-1}$: Previous cell state (memory).
- $\sigma$: Sigmoid function (pushes values to range $[0, 1]$).
- $\tanh$: Hyperbolic tangent (pushes values to range $[-1, 1]$).
- $W, U, b$: Learnable weights and biases specific to each gate ($f, i, c, o$).
Summary of LSTM Equations
Gates:
- Forget Gate: $f_t = \sigma(W_f h_{t-1} + U_f x_t + b_f)$
- Input Gate: $i_t = \sigma(W_i h_{t-1} + U_i x_t + b_i)$
- Candidate Gate: \(\tilde{S}_t = \tanh(W_c h_{t-1} + U_c x_t + b_c)\)
- Output: $O_t = \sigma(W_o h_{t-1} + U_o x_t + b_o)$
States:
- Cell State: $S_t = f_t \odot S_{t-1} + i_t \odot \tilde{S}_t$
- Long-Term Memory
- Designed for stable gradient flow
- The ‘whiteboard’ in our analogy
- Hidden State: $h_t = O_t \odot \tanh(S_t)$
- Short-term ‘readable’ memory
- Used for outputs and fed into the next time step
- The ‘lecture summary’ in our analogy
(Note: $S_t$ is popularly denoted by $C_t$ [cell state] in LSTM literature)
GRU (Gated Recurrent Unit)
To derive the Gated Recurrent Unit (GRU) equations, we apply three major simplifications to the LSTM architecture. The goal of the GRU is to achieve similar performance (capturing long-term dependencies) with fewer parameters and operations.
We will transform the LSTM (Forget $\to$ Write $\to$ Read) model into the GRU (Reset $\to$ Update) model.
Simplification 1: Merge the States (The Whiteboard is the Report)
LSTM Approach: We maintained two separate variables:
- Cell State ($S_t$): The internal Whiteboard (protected memory).
- Hidden State ($h_t$): The exposed Report (filtered output).
GRU Simplification: We assume that we don’t need to hide anything. The internal memory and the output can be the same.
- Action: Merge $S_t$ and $h_t$ into a single hidden state $h_t$.
Simplification 2: Couple Forget and Write (The “Update” Slider)
LSTM Approach: We had two separate decisions:
- Forget Gate ($f_t$): “How much old stuff should I erase?”
- Input Gate ($i_t$): “How much new stuff should I write?”
GRU Simplification: In practice, these are often mutually exclusive. If we are writing 100% new information (e.g., a new scene in a movie), we likely want to forget 100% of the old context. We combine them into a single Update Gate ($z_t$). This acts like a slider, and its direction follows the update equation $h_t = (1 - z_t)\odot h_{t-1} + z_t \odot \tilde{h}_t$ used below:
- If $z_t = 0$: keep the old memory, $h_t = h_{t-1}$ (pure retain).
- If $z_t = 1$: overwrite with the new candidate, $h_t = \tilde{h}_t$ (pure write).
(Some references define $z_t$ the other way around, so the safe habit is to read the direction off the update equation rather than trust the name.)
Derivation: Instead of:
\[S_t = f_t \odot S_{t-1} + i_t \odot \tilde{S}_t\]We use:
\[h_t = \underbrace{(1 - z_t) \odot h_{t-1}}_{\text{Retain Old}} + \underbrace{z_t \odot \tilde{h}_t}_{\text{Write New}}\]The Update Gate equation is standard:
\[z_t = \sigma(W_z \cdot h_{t-1} + U_z \cdot x_t)\]Simplification 3: Drop Output Gate, Add Reset Gate
LSTM Approach: We calculated the candidate $\tilde{S}_t$ using the full history, but we filtered the final output using an Output Gate ($O_t$).
GRU Simplification: Since we merged the states (Simplification 1), we have no Output Gate. We output $h_t$ directly.
However, to compensate for losing the detailed control of the LSTM, we introduce a Reset Gate ($r_t$) inside the candidate generation.
- Purpose: It allows the network to “short-term forget” the previous state when computing the new candidate, even if it hasn’t overwritten the actual state yet.
- Analogy: It’s like squinting at the whiteboard. We briefly ignore parts of the history to form a new thought, without actually erasing the board yet.
Derivation: LSTM Candidate:
\[\tilde{S}_t = \tanh(W S_{t-1} + U x_t)\]GRU Candidate (with Reset):
\[\tilde{h}_t = \tanh(W (\mathbf{r_t} \odot h_{t-1}) + U x_t)\]The Reset Gate equation:
\[r_t = \sigma(W_r \cdot h_{t-1} + U_r \cdot x_t)\]
- Image credit: By Jeblad - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=66225938
Final Summary: The GRU Equations
By applying these simplifications, we reduce the system from 3 Gates + 2 States (LSTM) to 2 Gates + 1 State (GRU).
1. The Gates
Reset Gate ($r_t$): (Decides how much past to ignore for the candidate)
\[r_t = \sigma(W_r h_{t-1} + U_r x_t + b_r)\]Update Gate ($z_t$): (Decides the balance between old memory and new candidate, in the convention above)
\[z_t = \sigma(W_z h_{t-1} + U_z x_t + b_z)\]
2. The Candidate (Proposed New State)
Action: Apply the Reset gate to the previous state, then combine with input.
\[\tilde{h}_t = \tanh(W (r_t \odot h_{t-1}) + U x_t + b)\](The gate biases $b_r, b_z, b$ were omitted earlier for brevity but are part of the standard cell. Implementations also vary in where the reset gate is applied: to $h_{t-1}$ before the recurrent matrix as shown, or after it, which changes the arithmetic slightly.)
3. The Final Update (Slider)
Action: Interpolate between the old state and the new candidate.
\[h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\]
How LSTMs Avoid the Problem of Vanishing Gradient
To understand how LSTMs and GRUs solve the vanishing gradient problem, we have to look at the mathematical operation connecting the state at time $t-1$ to the state at time $t$.
The short answer is: They convert multiplicative updates (which decay) into additive updates (which persist).
1. The Villain: Vanilla RNN (Multiplicative Decay)
In a standard RNN, to get from $S_{t-1}$ to $S_t$, we forcefully pass the information through a matrix multiplication and a squashing function ($\tanh$).
\[S_t = \tanh(W S_{t-1} + U x_t)\]When we backpropagate, the gradient flows backwards using the chain rule. As we derived in our notes, the gradient at step $k$ relative to step $t$ involves a product of Jacobians:
\[\frac{\partial S_t}{\partial S_k} \le (\tanh' \cdot \lVert W \rVert )^{t-k}\]- The Problem: If $\lVert W \rVert < 1$ or if the $\tanh’$ (derivative) is small (which it almost always is, maxing at 1.0), this product creates an exponential decay.
- Analogy: It’s like photocopying a photocopy 100 times. Each step slightly degrades the image (multiplies quality by 0.9) until the original information is unrecognizable.
2. The LSTM Solution: The Additive Superhighway
The LSTM architecture introduces the Cell State ($S_t$), which is our “Whiteboard.” The key innovation is how this whiteboard is updated. Look at the equation again:
\[S_t = \underbrace{f_t \odot S_{t-1}}_{\text{Retain Old}} + \underbrace{i_t \odot \tilde{S}_t}_{\text{Add New}}\]Notice the operation between $S_t$ and $S_{t-1}$? It is a plus sign (+), not a matrix multiplication.
The Derivative Check
If we compute the derivative of the current cell state with respect to the previous one along the direct cell-state path, holding the gates fixed:
\[\frac{\partial^+ S_t}{\partial S_{t-1}} = f_t\]- The controllable path: along this path the gradient is scaled directly by the forget gate $f_t$, not repeatedly mangled by $\text{diag}(\sigma’)\cdot W$ as in a vanilla RNN.
- The “remember” setting: if the network learns a piece of information matters long-term, it can push $f_t \approx 1$, and the product $\prod f_t$ across steps stays near 1, so the gradient reaches far back.
- But this is the partial, not the total, derivative. The full $\frac{\partial S_t}{\partial S_{t-1}}$ also flows through the gates, which themselves depend on $h_{t-1}$ and hence on $S_{t-1}$. And a forget gate even slightly below 1 still multiplies across time, so $\prod f_t$ can decay; saturated gates are also hard to train. So LSTMs improve access to a near-identity copy path; they do not force the gradient to stay exactly 1 for hundreds of steps.
Historically this near-identity path was called the Constant Error Carousel (CEC), from the original LSTM (which predates the modern forget gate). The picture of error “trapped and spinning without degrading” is the idealized $f_t = 1$ case, useful intuition rather than a literal guarantee.
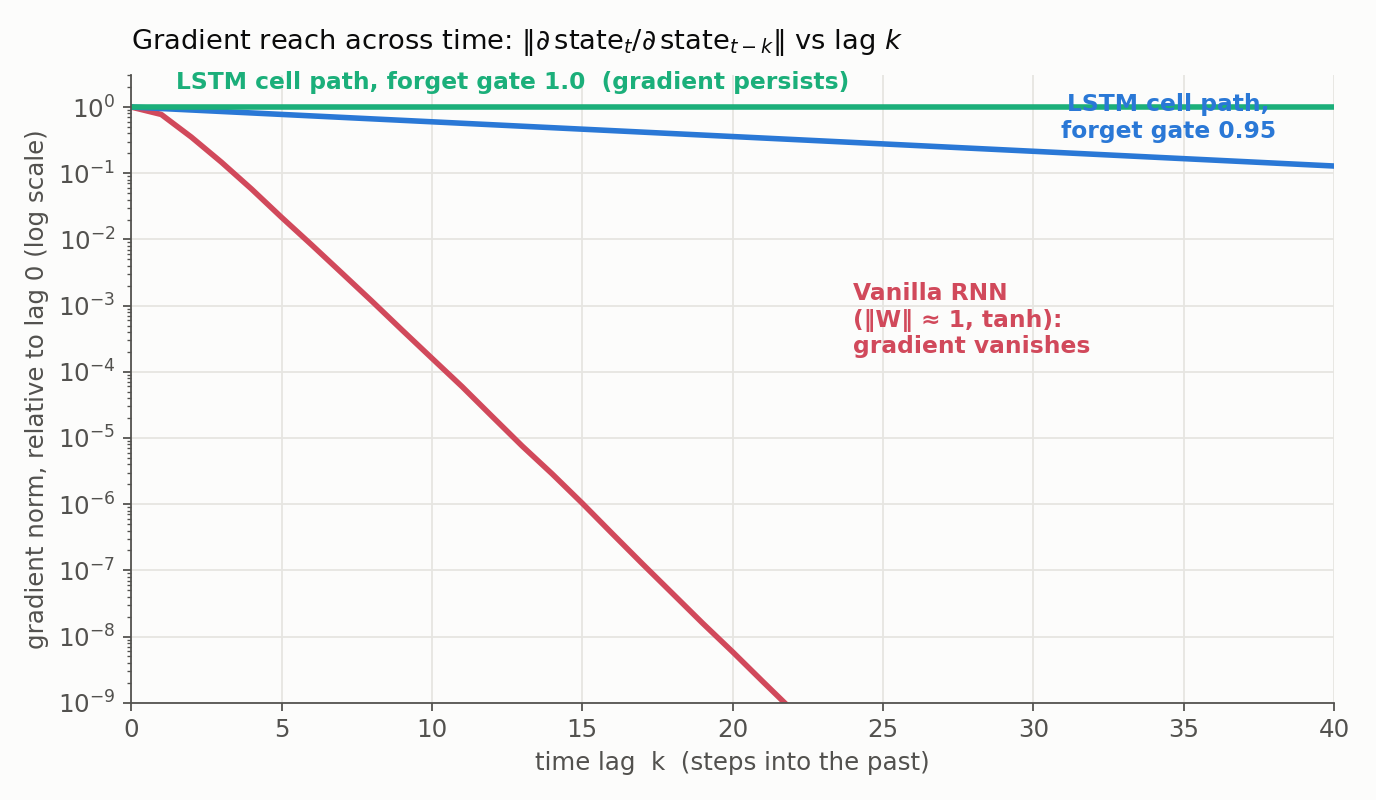
The figure makes the contrast concrete: the vanilla RNN’s gradient falls off a cliff within a couple of dozen steps, while the LSTM cell path decays only as fast as the forget gate allows, holding steady when $f_t = 1$.
3. The GRU Solution: The Learned Slider
The GRU uses the same logic but implements it via the Update Gate ($z_t$).
\[h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\]If we look at how the gradient flows from $h_t$ back to $h_{t-1}$:
\[\frac{\partial h_t}{\partial h_{t-1}} \approx (1 - z_t)\]- If $z_t \approx 0$ (meaning “don’t update, keep the old memory”): The derivative is $\approx 1$.
- The gradient passes through the unit untouched, preserving the dependency from the distant past.
Summary Comparison
The popular “multiplication versus addition” framing is a useful slogan but not literally accurate: vanilla RNN updates contain additions too, and LSTM/GRU updates still contain plenty of multiplications (the gates). The real difference is the availability of a gated additive path with a learned near-identity transition.
| Vanilla RNN | LSTM / GRU | |
|---|---|---|
| Cell/state update | $S_t = \tanh(W S_{t-1} + U x_t)$ | $S_t = f_t \odot S_{t-1} + i_t \odot \tilde{S}_t$ |
| Direct-path Jacobian | $\text{diag}(\sigma’)\cdot W$ (data-dependent, usually $<1$) | $f_t$ (a gate the network controls) |
| Gradient across time | Product of matrices: tends to vanish, can explode | Product of gates: persists when gates $\approx 1$, decays when small |
| Analogy | Photocopying a photocopy | A marker we can leave in place or erase at will |
Conclusion: LSTMs and GRUs do not eliminate the vanishing gradient; they give the network a controllable path for it. When context matters, the gates can be pushed toward a near-identity transition so the gradient survives; when it does not, the same gates let it decay. Gating makes the effective time horizon learnable rather than fixed, which is the real win, not an unconditional guarantee that gradients persist.
When to Reach for a Recurrent Model Today
Gating fixed the trainability of recurrence, but two practical facts shape where RNNs are used now:
- Recurrence is inherently sequential. Each step needs the previous hidden state, so an RNN cannot parallelize across time the way a Transformer can, which makes long-sequence training slower on modern hardware.
- Attention changed the default for long context. Transformers replaced RNNs for most long-context language and sequence tasks, largely because self-attention gives every position direct access to every other, sidestepping the step-by-step gradient path entirely, at the cost of compute and memory that grow with sequence length.
That said, LSTMs and GRUs remain a strong choice for streaming or online settings (they carry a compact state and emit outputs step by step, without re-reading the whole history), for small or embedded models where a Transformer is too heavy, and for genuinely stateful control problems. One caution for online use: bidirectional RNNs read the sequence both forwards and backwards, so they are not causal and cannot be used unchanged for real-time prediction, where only the past is available.