Deep Learning Primer: Understanding Word Embeddings: From SVD to Word2Vec
How do we represent the meaning of a word to a computer? This is the fundamental question of Natural Language Processing. Simply treating words as unique IDs fails to capture the relationships between them (e.g., that “chair” and “seat” are similar).
This post explores the journey of word representations, starting from classical statistical methods and evolving into the neural-based Word2Vec models (CBOW and Skip-Gram).
The Co-occurrence Matrix
The intuition behind word representation is distributional semantics: a word is defined by the company it keeps. We start by building a Co-occurrence Matrix of dimension $V \times V$ (where $V$ is the vocabulary size).
For every candidate word, we define a “context window” of size $k$. We count how many times context words appear within that window around the candidate word across the entire corpus.
Fixable Problems with Raw Counts
Raw counts have issues. “The”, “a”, and “is” appear everywhere but carry little semantic weight. Several design choices help, none of them a universal cure:
- Stop-word removal / vocabulary thresholds: drop very frequent or very rare words from the vocabulary.
- Reweighting the counts: cap them (e.g. $x_{ij} = \min(\text{count}(w_i, c_j), t)$), or, often better, weight by distance within the window, subsample frequent words, or smooth the context distribution. A fixed cap at $t = 100$ is one ad-hoc option, not a standard correction.
PMI (Pointwise Mutual Information): instead of raw counts, measure how much more often a word and context co-occur than chance would predict.
\[PMI(w, c) = \log \frac{P(w, c)}{P(w)\,P(c)} = \log \frac{\#(w, c)\, N}{\#(w)\, \#(c)}\]Here $\#(\cdot)$ is a count, and $N$ is the total number of co-occurrence events observed under the chosen window construction, not the number of tokens; $\#(w)$ and $\#(c)$ are the corresponding target and context marginals. (The word-context matrix need not even be square: the target and context vocabularies can differ.)
PMI is undefined for a zero-count pair, since $\log 0 = -\infty$. PPMI (Positive PMI) floors the defined negative values at 0; unseen pairs are simply left absent (zero) rather than run through the log, so PPMI reweights the observed pairs, it is not a mathematical fix for $\log 0$. Common refinements are shifted PPMI (subtracting a constant) and context-distribution smoothing (raising context counts to the $3/4$ power, the same trick we meet again in negative sampling).
Part 1: The Classical Approach (Count-Based)
Dimensionality Reduction via SVD
The resulting matrix $X (= X_{PPMI})$ is sparse and high-dimensional ($V \times V$). We need a dense, lower-dimensional representation. We apply Singular Value Decomposition (SVD):
\[X = U \Sigma V^T\]By the Eckart-Young-Mirsky theorem, truncating to the top $k$ singular values gives the best rank-$k$ approximation of $X$ under the Frobenius (and spectral) norm: it minimizes the total reconstruction error. That is an optimality statement about reconstruction, not a promise that every pairwise similarity or semantic relation is preserved.
What “keep the top $k$” actually means:
SVD does not pick out human-meaningful attributes to keep. It rewrites the data along orthogonal directions ordered by how much of the matrix’s variation (reconstruction energy) each one explains, which is what the singular values measure. Keeping the top $k$ retains the $k$ directions that reconstruct $X$ best in aggregate and discards the low-energy rest. Which semantic features happen to survive is an emergent consequence of that objective, not something we specify.
If we apply SVD on $X_{PPMI}$ and get \(\hat{X} = (U_{m,k}\Sigma_{k,k}V^{T}_{k,n})\) after keeping only the top-$k (k \ll n)$ singular values, the sparse co-occurance matrix would become dense. Some co-occurances which previously were not captured, would now start to get captured.
- Recall that each row in the original matrix $X$ served as the representation of a word.
- Then $XX^T$ would result in a matrix whose $(i,j)^{th}$ entry would be the dot-product between the representation of word $i$ and $j$.
Once we perform SVD, what’s a good choice for the word representation?
- Taking the $i^{th}$ row of the reconstructed matrix $\hat{X}$ doesn’t help because it’s still $V$-dimensional.
- But the reconstructed $\hat{X} = U_k \Sigma_k V_k^{T}$ has surfaced latent structure, and its implied similarities $\hat{X}\hat{X}^T$ are the ones we want to keep. (There is no general elementwise ordering between $(XX^T){ij}$ and $(\hat{X}\hat{X}^T){ij}$: truncation can raise or lower any individual dot product.)
Wishlist
We’d want a representation of each word in far fewer dimensions than $V$, while still reproducing the similarity scores $(\hat{X}\hat{X}^T)_{ij}$.
Notice that the dot product between the rows of the matrix $W_{word} = U\Sigma$ is the same as the dot product between the rows of $\hat{X}$.
\[\hat{X}\hat{X}^T = (U \Sigma V^{T})(U \Sigma V^{T})^{T}\] \[= (U \Sigma V^{T}) \cdot (V \Sigma^{T} U^{T})\] \[= (U \Sigma) \cdot (\Sigma^{T} U^{T})\] \[= (U \Sigma) \cdot (U \Sigma)^{T}\] \[= W_{word} \cdot W_{word}^{T}\] \[\hat{X} \in \mathbb{R}^{m \times n} \quad \text{but} \quad W_{word} \in \mathbb{R}^{m \times k}, \quad k \ll n.\]This serves our purpose: with $W_{word} = U_k\Sigma_k$ we get $W_{word} W_{word}^T = U_k\Sigma_k^2 U_k^T = \hat{X}\hat{X}^T$, exactly the similarities we wanted, in only $k$ dimensions.
A subtlety worth flagging: how $\Sigma_k$ is split between the word and context factors is a choice, and it changes the embedding geometry. Taking $W_{word} = U_k\Sigma_k$ and $W_{context} = V_k$ is one convention; others use $U_k$ with $V_k\Sigma_k$, or the symmetric $U_k\Sigma_k^{1/2}$ and $V_k\Sigma_k^{1/2}$ (which often works well). All reconstruct the same $\hat{X}$ but yield different word vectors.
Part 2: The Neural Approach (Word2Vec): Continuous Bag of Words (CBOW)
While SVD is powerful, it is computationally expensive to update as the vocabulary grows. This motivates “prediction-based” models like CBOW/SkipGram.
Let’s write out the complete CBOW training procedure step-by-step for a single-sentence corpus using a context window of 2.
1. Corpus and training examples
Take the sentence (example):
1
A quick brown fox jumps over the lazy dog
Vocabulary (V) = unique words in the corpus (here 9 words). Window size (w = 2) means we use up to 2 words on each side as context.
For each token at position (t) (except edges), create a training sample:
- Context ($C_t = {x_{t-2}, x_{t-1}, x_{t+1}, x_{t+2}}$) (some positions may have fewer than 4 if near edges)
- Target ($y_t = x_t$)
Examples of training pairs (position → (context, target)):
- t=3 (“brown”): context = [“A”,”quick”,”fox”,”jumps”], target = “brown”
- t=4 (“fox”): context = [“quick”,”brown”,”jumps”,”over”], target = “fox”
- etc.
We turn each word into a one-hot column vector:
\[u \in \mathbb{R}^{V \times 1}\]where exactly one entry is 1.
2. CBOW DNN architecture (mathematical)
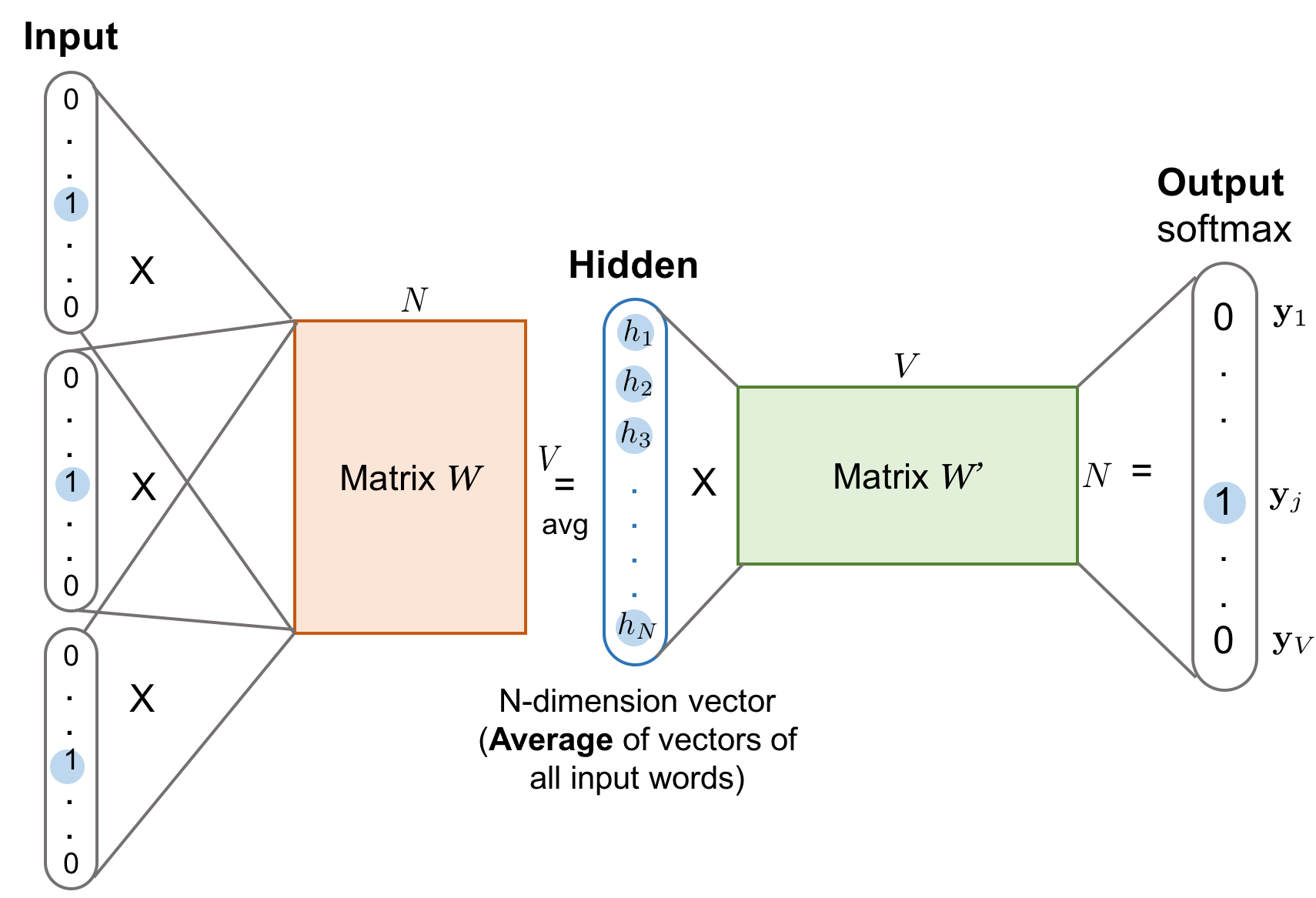
Image credit: https://deeplearning.ir/wp-content/uploads/2019/05/word2vec-cbow.png
Parameters to learn:
- Input embedding matrix $W \in \mathbb{R}^{n \times V}$. Each column = embedding of a word. Embedding dimension = (n).
- Output weight matrix $W’ \in \mathbb{R}^{V \times n}$ (or classifier matrix). This maps an (n)-dim vector back to vocab space..
Notation:
- Vocabulary size ($V$)
- Embedding dim ($n$)
- Number of context words $(m = \lvert C_t \rvert)$ (here up to 4)
3. Forward Pass for One Training Example
Let context have (m) words (usually 4).
Step 1: Get embeddings for each context word
For each context word with one-hot $(u_i)$:
\[e_i = W_{in} u_i \quad (n \times 1)\]This selects the corresponding $i^{th}$ column from $W$.
Step 2: Average embeddings
\[h = \frac{1}{m} \sum_{i=1}^m e_i \quad (n \times 1)\]This is the hidden CBOW representation.
Step 3: Compute logits (scores for all words)
\[z = W' h \quad (V \times 1)\]Step 4: Softmax prediction
\[\hat{y}_j = \frac{e^{z_j}}{\sum_{k=1}^{V} e^{z_k}}\]4. Loss/Gradients/Backprop
The “math” of the gradient descent (Chain Rule) is identical to standard deep learning, but the mechanics of how the updates are applied in CBOW are distinct in two critical ways.
Here are the key differences between a standard Feed-Forward Network (MLP) and CBOW:
1. Sparse vs. Dense Updates (The “Lookup” Difference)
With a dense input (say, predicting housing prices from 10 real-valued features), every input weight in the first layer generally contributes to the output and receives a gradient each step. (Even then the gradients are not always fully dense: inactive ReLU units, masking, or zero inputs can zero some of them.) The sharp contrast here is really embedding lookup versus a dense full-vocabulary projection.
In CBOW the input is a one-hot lookup, so with input matrix $W \in \mathbb{R}^{n \times V}$ (each column an embedding), a context word simply selects its column:
- Dense projection: $\nabla W$ would be a dense matrix, every entry changing slightly.
- CBOW: $\nabla W$ is extremely sparse. With vocabulary $V = 100{,}000$ and context size 4, only the 4 columns selected by the context words receive a gradient; the other 99,996 columns get exactly 0.
- Implication: the backward pass on $W$ is not a full matrix multiplication but a column lookup and vector addition on those few embeddings.
- The target word’s own column is not read on the input side, so it gets no input-side gradient; only the context columns do. (The output matrix $W’$ is a separate story, covered below.)
2. Identical Gradients (The “Averaging” Difference)
In a standard MLP, the first layer multiplies input features by different weights, so those weights get different gradients.
In CBOW, we average the context word vectors before the hidden layer:
\[h = \frac{v_1 + v_2 + \dots + v_m}{m}\]Because the hidden state is an unweighted average, the upstream error arriving at $h$ is passed back to each context embedding scaled by the same $1/m$. So within one training step, each distinct context word’s input embedding receives the same input-side gradient:
- Result: $\nabla v_{quick} = \nabla v_{brown} = \nabla v_{jumps} = \nabla v_{over}$ (and if a word appears twice in the context, its gradient accumulates).
- Scope: this is permutation invariance over context positions, not the model deciding the words are “equally responsible.” Note also that the output embeddings ($W’$) do receive different per-word gradients, and it is over many contexts that the input vectors differentiate.
3. Positional Agnosticism
In a standard sequence model (like an RNN or a Transformer) or even a standard MLP, the position matters.
- Input 1 is “Subject”, Input 2 is “Verb”.
- Weights are learned specific to those positions.
In CBOW, because of the summation/averaging gradient:
- Context
["The", "cat"]produces the exact same gradient update as["cat", "The"]. - The gradient descent process in CBOW is invariant to the order of context words. It creates a “Bag of Words” representation where spatial information is explicitly discarded during the update.
Summary Table
| Feature | Standard MLP Backprop | CBOW Backprop |
|---|---|---|
| Input Weights | Dense Matrix Multiplication | Row Lookup / Indexing |
| Update Scope | All weights updated every step | Only $C$ rows updated (Sparse) |
| Gradient Value | Unique for every input feature | Identical for all active context words |
| Word Order | Usually preserved (via different weights) | Lost (Order doesn’t affect gradient) |
Words that appear in similar contexts end up with similar embeddings, because they receive similar gradient signals over the corpus. This is a statistical tendency of the objective, not a guarantee: it is why “chair” and “seat” land near each other, but it also pulls antonyms together (like “hot” and “cold,” which share contexts), so nearness in this space means distributional similarity, not synonymy.
Technical Note on Efficiency: Because of “Difference #1” (Sparsity), standard deep learning frameworks (like PyTorch/TensorFlow) often use a specialized layer (e.g., nn.Embedding) instead of a standard nn.Linear layer. nn.Embedding is optimized to handle these sparse gradient updates without calculating the zeros for the rest of the vocabulary.
Part 3: The Neural Approach (Word2Vec): The Skip-Gram Model
1. What is Skip-Gram?
Skip-Gram is one of the core Word2Vec architectures. Its goal is the opposite of CBOW:
Skip-Gram predicts the surrounding context words given the center (target) word.
If the sentence is:
1
A quick brown fox jumps over the lazy dog
and the center word is “brown” with window radius 2 (two words on each side), then Skip-Gram tries to predict each of its context words:
1
{ "A", "quick", "fox", "jumps" }
Here “window 2” means radius 2, up to two words on each side, so four context words for a center in the interior and fewer near the edges. CBOW: context → target; Skip-Gram: target → context.
2. Skip-Gram Model Architecture
Embedding matrices (column-wise convention)
Input embeddings:
\[W \in \mathbb{R}^{n \times V}\](columns = embeddings)
Output embeddings:
\[W' \in \mathbb{R}^{V \times n}\]
Training pairs in Skip-Gram
For a target word (x_t) and window (w):
\[(x_t, x_{t-2}), (x_t, x_{t-1}), (x_t, x_{t+1}), (x_t, x_{t+2})\]So one target produces multiple training examples.
3. Forward pass
- Represent center word as one-hot vector $(u_c)$
Embed:
\[h = W[:,c] \in \mathbb{R}^{n}\]For each context word ($k$):
\[z_k = W'[k,:] \cdot h\]Use softmax:
\[P(\text{context}=k \mid \text{center}=c) = \frac{e^{z_k}}{\sum_{j=1}^{V} e^{z_j}}\]
Two Embedding Tables
Both CBOW and Skip-Gram learn two embedding tables: the input embeddings $W$ (the “word” vectors) and the output embeddings $W’$ (the “context” vectors). In practice the input table $W$ is what gets exported and used as “the word embeddings,” though some setups average or concatenate the two. The distinction also drives training cost: under full softmax every column of the output table $W’$ is updated on every step (it appears in the normalizer), whereas negative sampling (next) updates only the positive and sampled output vectors. This mirrors the two factors $W_{word}$ and $W_{context}$ from the SVD view in Part 1.
Key Differences Between Skip-Gram and CBOW
| Aspect | CBOW | Skip-Gram |
|---|---|---|
| Direction | context → target | target → context |
| Training pairs | 1 per target | multiple per target |
| Input | average of context embeddings | embedding of center word |
| Updates to embeddings | context embeddings only | center embedding + sampled outputs |
| Works well with | large corpus, frequent words | small datasets, infrequent words |
| Training speed | faster (only 1 softmax per target) | slower (multiple predictions per target) |
| Embedding stability | smoother, averaged representations | richer, more detailed representations |
| Rare words | performs worse | performs better |
| Use case | fast training, general semantics | high-quality embeddings, small corpora |
When to Choose Which?
Use CBOW when:
- We have a very large dataset
- We want fast training
- We care about stable/average meanings (e.g., “bank” often becomes the average of contexts)
Use Skip-Gram when:
- We want high-quality embeddings
- We want to capture more subtle relations
- We have a smaller dataset
- We want better performance for rare words
Skip-Gram tends to produce richer, more nuanced embeddings.
The Computational Bottleneck
The bottleneck is the denominator of the softmax: to score one training example we must compute a dot product against every word in the vocabulary (100,000+) to normalize the probability. Repeated every step, this makes large-corpus training impractical.
There are a few ways around it. Hierarchical softmax replaces the flat normalizer with a binary tree over the vocabulary ($O(\log V)$ per step). Negative sampling (NEG), the approach we focus on, takes a different route, and it is a cousin of noise-contrastive estimation (NCE) (NEG is a simplified variant that drops NCE’s normalization terms). Below we use Skip-Gram’s center-context pairs $(w, c)$; the same idea adapts to CBOW by replacing $w$’s vector with the averaged context vector.
1. The Core Idea: A New Objective, Not Just a Faster Softmax
Negative sampling does not approximate the softmax probability; it replaces the objective. Instead of a $V$-way classification (“which of 100,000 words is it?”), it poses many small binary logistic questions (“is this (word, context) pair real, or noise?”), with no normalization over the vocabulary at all. We just want the model to output:
- High score for the true pair (a word and a real context word).
- Low score for a few noise pairs (the word and randomly drawn words).
2. The New Training Data
Take a Skip-Gram pair from “A quick brown fox…“, with center word “fox” and a real context word “brown”:
The Positive Sample (label 1): the observed pair $(w = \text{fox},\ c = \text{brown})$, which we want scored high.
The Negative Samples (label 0): draw $K$ words (usually $K = 5$ to $20$) that are not the true context, say “apple”, “car”, “tennis”, and pair each with “fox”. These pairs never occurred; they are the “noise,” which we want scored low.
3. The New Loss Function
Writing $v_w$ for the input (word) vector and $v’_c$ for the output (context) vector, the per-pair loss is a sum of binary log-losses:
\[J = - \log \sigma(v'_c \cdot v_w) - \sum_{i=1}^{K} \log \sigma(-\, v'_{n_i} \cdot v_w)\]- First term: push the true pair’s score up ($\sigma \to 1$).
- Second term: push each noise pair’s score down ($\sigma(-x) \to 1$, i.e. $\sigma(x) \to 0$). Every term is an ordinary logistic loss; there is no softmax denominator anywhere.
4. How the Gradient Descent Changes
This is where the magic happens.
In Standard Softmax: We had to update the output vector $u_w$ for all 100,000 words because every word appeared in the denominator.
In Negative Sampling: We only update the weights for:
- The 1 positive word (“fox”).
- The $K$ negative words (“apple”, “car”, “tennis”).
The Update Sparsity: If vocabulary $V = 100,000$ and $K=5$:
- Softmax: 100,000 updates per step.
- Negative Sampling: 6 updates per step.
This creates a massive speedup (orders of magnitude), making it possible to train on Google-scale datasets.
5. Smart Sampling (The “Unigram” Trick)
How do we pick the negative words? Not uniformly, and not by raw frequency either. Sampling uniformly wastes most negatives on rare words; sampling by raw frequency would draw “the” and “and” almost every time and rarely teach the model to tell “fox” from “wolf”.
Word2Vec (Mikolov et al., 2013) samples negatives from the unigram distribution raised to the $3/4$ power:
\[P(w) = \frac{\text{count}(w)^{0.75}}{\sum_{w' \in V} \text{count}(w')^{0.75}}\]This sits between raw frequency and uniform: it dampens the very frequent words and lifts the rare ones, as the figure shows.
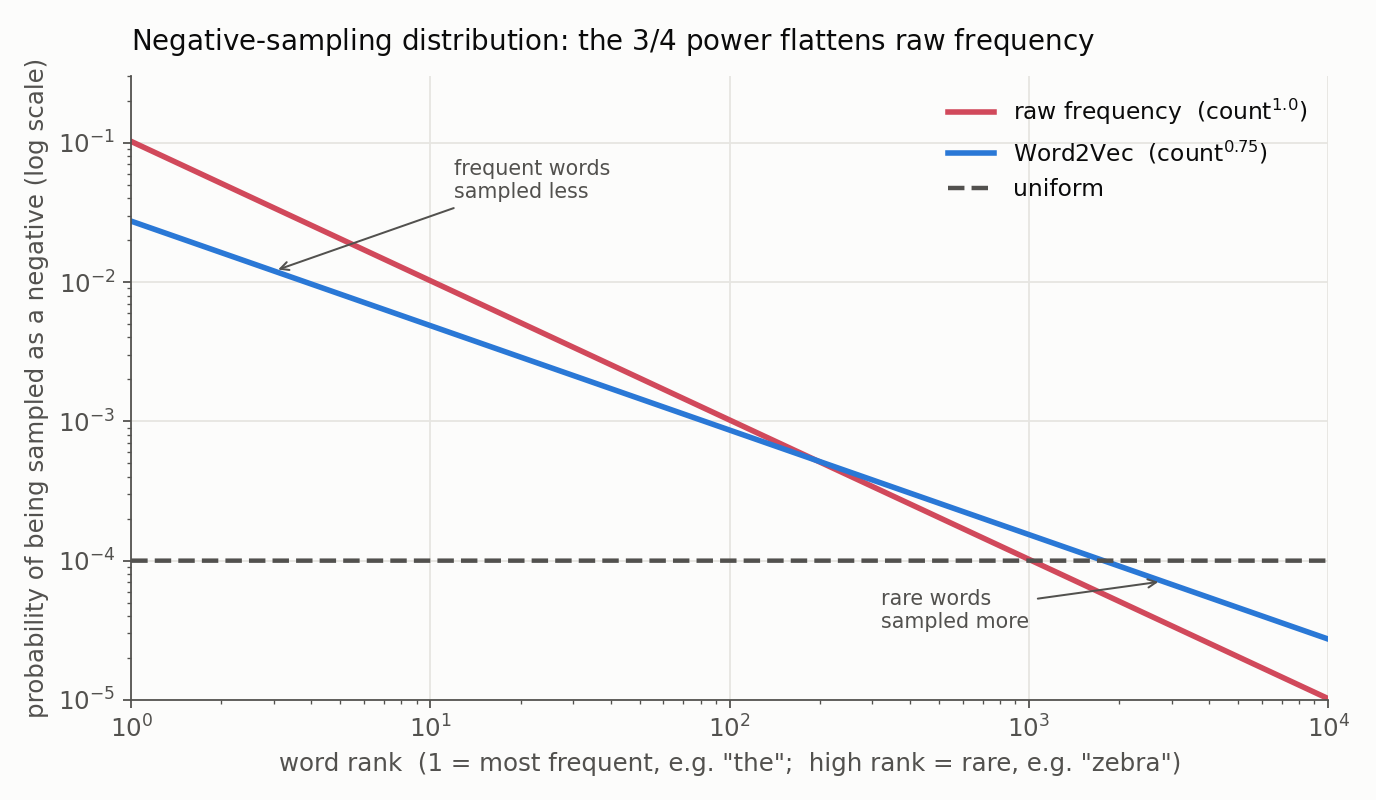
The exponent $0.75$ is an empirical heuristic from the original paper, not a derived optimum: it works well in practice, but nothing guarantees it is the ideal mix of negatives.
Summary
Negative sampling swaps the corpus likelihood for a cheaper discrimination objective. It is not the same objective, but for learning good embeddings, telling the real context word apart from a handful of noise words turns out to be enough.
A Bridge Back to Counts: SGNS as Implicit Matrix Factorization
There is a striking result tying the two halves of this post together. Levy and Goldberg (2014) showed that Skip-Gram with Negative Sampling (SGNS), for a given number of negatives $K$, is implicitly factorizing a word-context matrix whose entries are the shifted PMI, $\text{PMI}(w, c) - \log K$. In other words, the “neural, prediction-based” model and the “classical, count-based” PMI-plus-SVD approach from Part 1 are two views of the same underlying object, not an old-versus-new divide.
Evaluation and Limitations
Once trained, embeddings are usually judged by:
- Nearest neighbors under cosine similarity (the neighbors of “france” should be other countries).
- Analogy tests like $\text{king} - \text{man} + \text{woman} \approx \text{queen}$, which are striking but fragile: they are sensitive to preprocessing and normalization, and plenty of analogies simply do not hold.
- Extrinsic tasks: does using the embeddings actually improve a downstream classifier or retrieval system?
And these static embeddings have real limits, worth stating plainly:
- One vector per word conflates senses. “bank” (river) and “bank” (finance) collapse into a single averaged point.
- Out-of-vocabulary words have no vector at all; subword models like fastText address this by embedding character n-grams.
- They encode corpus biases, including social stereotypes present in the training text.
- Similarity means co-occurrence, not truth or synonymy, and as noted, antonyms can sit close together.
- Word order and composition are absent: “dog bites man” versus “man bites dog” is nowhere in a bag of embeddings.
These limits are exactly what contextual representations (ELMo, BERT, and the Transformer family) were built to address, giving each occurrence of a word its own vector in context, at a much higher compute cost.