Stats Primer: How to Choose the Right Sample Size for Your A/B Tests
Part of the statistical-inference arc. It follows the A/B testing posts (design, parametric, non-parametric) and answers their planning question: how much data, and how much calendar time, do we need to make a decision?
The foundations post covered how to design and validate a randomized experiment. This one answers the question it left open: how much data, and how much time, do we actually need? That means connecting the significance level, statistical power, the baseline rate and its variability, the minimum detectable effect, the allocation, and the duration, and then validating the realized split with a sample-ratio-mismatch check.
1. Pre-requisites: The Statistical Foundation
Before diving into the math, we must understand the “rules of the game” regarding errors and sample sizes.
Type I and Type II Errors (The Boy Who Cried Wolf)
In hypothesis testing, we risk making two types of mistakes. Let’s use the fable of “The Boy Who Cried Wolf” to understand them.
- Type I Error ($\alpha$ - False Positive):
- The Scenario: The boy cries “Wolf!” when there is actually no wolf and villagers come.
- Technical Meaning:
- Null Hypothesis ($H_0$): “There is no wolf!” $\rightarrow$ which is true.
- We (villagers) falsely reject the null Hypothesis ($H_0$). So, it’s a false positive error.
- In A/B Testing: We conclude that Version B is better than Version A, when in reality, there is no difference. This is determined by our Significance Level ($\alpha$), typically set to 0.05, accepting a 5% chance of a false positive.
- Type II Error ($\beta$ - False Negative):
- The Scenario: The boy cries “Wolf!”. The wolf actually appears, but the villagers don’t come.
- Technical Meaning:
- Null Hypothesis ($H_0$): “There is no wolf!” $\rightarrow$ which is false.
- We (villagers) mistakenly fail to reject the null Hypothesis ($H_0$). So, it’s a false negative error.
- In A/B Testing: Version B is actually better, but our test fails to detect it.
Statistical Power
Statistical power is the probability that our experiment will correctly reject the null under a specific alternative effect (Power = $1 - \beta$). Two framing points matter. First, $\alpha$ and power are long-run properties of the testing procedure, not statements about a single result: $\alpha$ is the fraction of null experiments that would be flagged as positive, and power is the fraction of experiments with the assumed true effect that would be detected. Neither is “the probability this particular conclusion is right or wrong.”
- A test with high power is like a strong magnifying glass, sensitive enough to spot genuine improvements.
- 80% is a common convention, not a universal standard, meaning we accept a 20% chance of missing a real winner. The right target is set by the consequence of missing the effect: a costly, hard-to-reverse decision warrants 90% or more.
- Power is defined against a specific effect size. There is no such thing as “the power” of a test in the abstract; it is always the power to detect a stated minimum detectable effect.
The Link to Sample Size
To avoid these errors, we cannot simply stop a test when we see a win. We must calculate a sample size before starting. The sample size is the number of users required to satisfy our chosen $\alpha$ (risk of false positive) and Power (ability to avoid false negative).
Absolute versus Relative MDE
Before any formula, pin down what the minimum detectable effect (MDE) $\delta$ actually measures, because absolute and relative lifts are routinely confused and the confusion can change the required sample by an order of magnitude. For a baseline conversion of 10%:
- an absolute lift of 1 percentage point means 10% to 11%;
- the same change expressed as a relative lift is 1/10 = 10%.
A “1% improvement” is dangerously ambiguous: a 1 percentage-point absolute lift (10% to 11%) needs far less traffic than a 1% relative lift (10% to 10.1%), which is a tenth of the effect and therefore roughly 100 times the sample size. Always state the MDE as absolute or relative, and keep it consistent through the calculation.
2. Sample Size Calculation for various A/B Tests
1-Sample Z-Test
Formulation: The critical value is defined from the perspective of the null hypothesis ($H_0$) and the alternative hypothesis ($H_a$).
\[\text{Critical Value} = \mu_0 + Z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}}\] \[\text{Critical Value} = \mu_a - Z_{\beta} \cdot \frac{\sigma}{\sqrt{n}}\]Min Sample Size Derivation: To find $n$, we set the two critical value expressions equal to each other:
\[\mu_0 + Z_{\alpha/2} \frac{\sigma}{\sqrt{n}} = (\mu_0 + \delta) - Z_{\beta} \frac{\sigma}{\sqrt{n}}\]Rearranging to isolate $n$:
\[\frac{\sigma}{\sqrt{n}}(Z_{\alpha/2} + Z_{\beta}) = \delta\] \[\sqrt{n} = \frac{\sigma(Z_{\alpha/2} + Z_{\beta})}{\delta}\] \[n = \frac{(Z_{\alpha/2} + Z_{\beta})^2 \sigma^2}{\delta^2}\]- (Where $\delta$ is the Minimum Detectable Effect.)
Notation note. Throughout these derivations, $Z_{\alpha/2}$ and $Z_{\beta}$ denote the positive upper-tail critical values $z_{1-\alpha/2}$ and $z_{1-\beta}$ (for example $z_{0.975} \approx 1.96$ and $z_{0.80} \approx 0.84$). Writing $Z_{\beta}$ loosely can suggest the negative lower-tail quantile, so read it here as $z_{1-\beta}$.
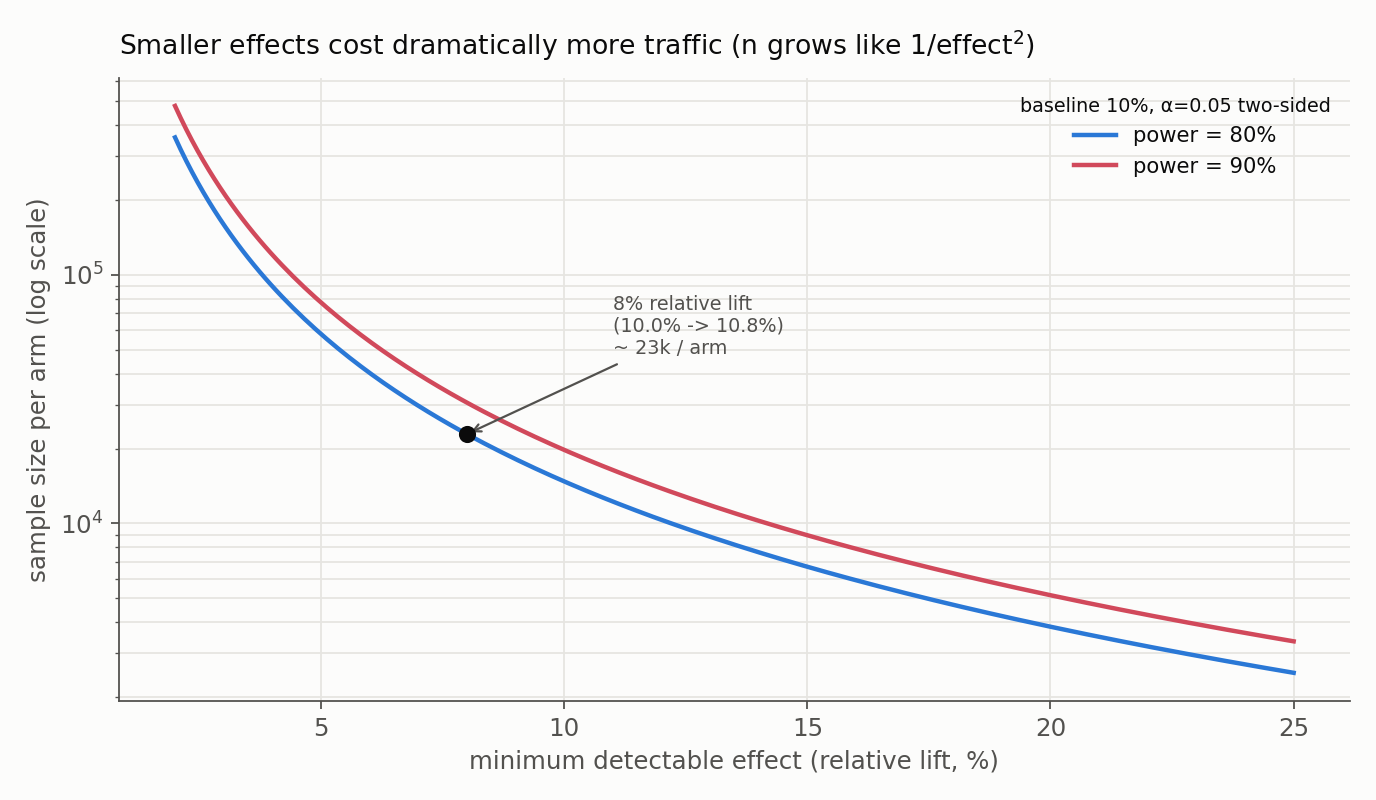
This formula also carries the single most important planning intuition: the required sample scales with $1/\delta^2$, so halving the effect we want to detect roughly quadruples the traffic. The figure below makes that blow-up concrete for a binary metric.
2-Sample Z-Test
Min Sample Size Derivation: We use the standard error of the difference between two means ($SE = \sqrt{\frac{2\sigma^2}{n}}$).
\[Z_{\alpha/2} \cdot \sqrt{\frac{2\sigma^2}{n}} = \delta - Z_{\beta} \cdot \sqrt{\frac{2\sigma^2}{n}}\]Solving for $n$:
\[n = \frac{2(Z_{\alpha/2} + Z_{\beta})^2 \sigma^2}{\delta^2}\]Rationale for $SE = \sqrt{\frac{2\sigma^2}{n}}$
1. The General Rule (Variance Sum Law)
\[Var(\bar{x}_1 - \bar{x}_2) = Var(\bar{x}_1) + Var(\bar{x}_2)\]
When we subtract two independent random variables (like two sample means, $\bar{x}_1$ and $\bar{x}_2$), their variances add up. Even though we are calculating the difference in means ($\bar{x}_1 - \bar{x}_2$), the uncertainty (variance) from both groups accumulates.2. Variance of a Single Sample Mean
\[Var(\bar{x}) = \frac{\sigma^2}{n}\]
The variance of a single sample mean is the population variance divided by the sample size:So, substituting this into the general rule:
\[Var(\bar{x}_1 - \bar{x}_2) = \frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2}\]3. The Simplifying Assumptions
The specific formula $\frac{2\sigma^2}{n}$ is derived by applying two constraints commonly used in experimental design:Equal Variances: We assume the population variance for both groups is the same ($\sigma_1^2 = \sigma_2^2 = \sigma^2$).
Equal Sample Sizes: We assume we use the same sample size for both groups ($n_1 = n_2 = n$).4. The Final Derivation
\[Var(\bar{x}_1 - \bar{x}_2) = \frac{\sigma^2}{n} + \frac{\sigma^2}{n} = \frac{2\sigma^2}{n}\]
Substitute these assumptions back into the equation:
1-Proportion Z-Test
Formulation: The critical value is defined from the perspective of the null hypothesis ($H_0$) and the alternative hypothesis ($H_a$). We’re using a one-tailed test here.
\[p_{crit} = p_0 + Z_{\alpha} \sqrt{\frac{p_0(1-p_0)}{n}}\] \[p_{crit} = p_a - Z_{\beta} \sqrt{\frac{p_a(1-p_a)}{n}}\]Min Sample Size Derivation: Since both equations describe the same critical value point, we set them equal to each other
\[p_0 + Z_{\alpha} \sqrt{\frac{p_0(1-p_0)}{n}} = p_a - Z_{\beta} \sqrt{\frac{p_a(1-p_a)}{n}}\]Rearrange the terms to isolate $n$
\[Z_{\alpha} \sqrt{\frac{p_0(1-p_0)}{n}} + Z_{\beta} \sqrt{\frac{p_a(1-p_a)}{n}} = p_a - p_0\] \[n = \left( \frac{Z_{\alpha}\sqrt{p_0(1-p_0)} + Z_{\beta}\sqrt{p_a(1-p_a)}}{p_a - p_0} \right)^2\]
2-Proportion Z-Test
Formulation: The critical value is defined from the perspective of the null hypothesis ($H_0$) and the alternative hypothesis ($H_a$). We’re using a two-tailed test here.
\[d_{crit} = 0 + Z_{\alpha/2} \cdot SE\] \[d_{crit} = (p_1 - p_2) - Z_{\beta} \cdot SE\]Min Sample Size Derivation: We equate the critical values defined by $\alpha$ and $\beta$.
\[Z_{\alpha/2} \sqrt{\frac{p_1(1-p_1)}{n} + \frac{p_2(1-p_2)}{n}} = (p_1 - p_2) - Z_{\beta} \sqrt{\frac{p_1(1-p_1)}{n} + \frac{p_2(1-p_2)}{n}}\]Solving for $n$ gives a common simplified formula:
\[n = \frac{(Z_{\alpha/2} + Z_{\beta})^2 [p_1(1-p_1) + p_2(1-p_2)]}{(p_1 - p_2)^2}\]This version uses the same (unpooled) variance for both the $\alpha$ and $\beta$ terms. The more precise standard form separates them, because under the null the two arms share a common rate (so the null variance is pooled, $2\bar p(1-\bar p)$ with $\bar p = (p_1+p_2)/2$), while under the alternative they do not (so the alternative variance is unpooled). This mirrors the pooled-test-SE versus unpooled-interval-SE distinction from the z and t post:
\[n_{\text{per arm}} \approx \frac{\left[ Z_{\alpha/2}\sqrt{2\bar p(1-\bar p)} + Z_{\beta}\sqrt{p_1(1-p_1)+p_2(1-p_2)} \right]^2}{(p_2 - p_1)^2}.\]For a 10% baseline and an 8% relative lift (10.0% to 10.8%) at $\alpha = 0.05$ two-sided and 80% power, this gives about 23,000 users per arm. Statistical software may use score, arcsine, continuity-corrected, or exact/numerical methods and return somewhat different numbers, so treat any hand formula as a planning estimate.
Everything Else
For z-tests we have the simple algebra formulas above. The t-test shares the same shape of formula, but these are normal-approximation planning estimates: because a t-test estimates the variance from the data, its exact power comes from a noncentral t distribution and is best obtained from a numerical solver (the normal formula slightly understates the required $n$, especially at small samples). For ANOVA, Chi-Square, and Simulation tests, there is no simple closed form at all, because the math involves noncentral probability distributions.
Here is how we determine the sample size ($n$) for these more complex scenarios.
ANOVA and Chi-Square (Parametric Tests)
Since there is no simple formula like $n = \frac{(z_{\alpha}+z_{\beta})^2 \sigma^2}{\delta^2}$, we use Power Analysis. We need to define four inputs to solve for the fifth (Sample Size).
The 4 Inputs We Must Define
- Significance Level ($\alpha$): Usually 0.05.
- Power ($1-\beta$): Usually 0.80 (80% chance of finding the effect if it exists).
- Degrees of Freedom (Groups): How many groups are we comparing? (A/B/C/D…)
- Effect Size: This is the hardest part. We must estimate “how wrong” the Null Hypothesis is.
| Test | Effect Size Metric | How to estimate it? |
|---|---|---|
| ANOVA (Continuous) | Cohen’s $f$ | $f = \sqrt{\frac{\eta^2}{1-\eta^2}}$ Rule of thumb: Small=0.1, Medium=0.25, Large=0.4 |
| Chi-Square (Counts) | Cohen’s $w$ (or Cramér’s V) | $w = \sqrt{\sum \frac{(P_{observed} - P_{expected})^2}{P_{expected}}}$ Rule of thumb: Small=0.1, Medium=0.3, Large=0.5 |
How to actually calculate it
Do not try to derive this manually. Use software.
- G*Power: The gold standard free tool for this. We literally select “F-test (ANOVA)” or “Chi-square”, input the effect size (0.25), alpha (0.05), and power (0.80), and it gives us $n$.
- Python/R:
- Python:
statsmodels.stats.power.FTestAnovaPower().solve_power(effect_size=0.25, alpha=0.05, power=0.8) - R:
pwr.anova.test(k=3, f=0.25, sig.level=0.05, power=0.8)
- Python:
Permutation & Bootstrap Tests (Simulation Methods)
This is trickier. Because these tests don’t assume a specific distribution (like the Normal or F-distribution), there is no formula to calculate sample size.
Instead, we must run a Simulation-Based Power Analysis. We essentially “fake” an experiment on our computer thousands of times to see what sample size works.
The Algorithm (How to do it step-by-step)
Step 1: Create a “Synthetic Truth”
Decide what effect we hope to find.- Example: “I suspect Group A has a mean of 10 and Group B has a mean of 12, with a standard deviation of 3.”
Step 2: Pick a starting $n$
Let’s guess we need $n=30$ per group.- Step 3: Run the “Outer Loop” (The Power Simulation)
- Generate random data for Group A ($n=30, \mu=10, \sigma=3$) and Group B ($n=30, \mu=12, \sigma=3$).
- Run our Permutation Test (or Bootstrap) on this fake data to get a p-value.
- Record: Did the p-value drop below 0.05? (1 = Yes, 0 = No).
- Repeat this 1,000 times.
- Step 4: Calculate Power If we rejected the Null 600 times out of 1,000, our Power is 60%.
- Goal: We want 80%.
- Step 5: Adjust and Repeat Since 60% < 80%, increase $n$ to 40 and repeat Step 3. Keep increasing $n$ until our rejection rate hits 80%.
A rough shortcut (use with caution) If we cannot run a simulation, a rough starting point is to compute the parametric sample size and pad it modestly. But there is no universal inflation factor like “+15%”: the relative efficiency of a non-parametric test depends on the outcome distribution and the test itself. Against roughly normal data the Mann-Whitney test needs only about 5% more than a t-test; against heavy-tailed data a rank-based test can be more efficient (needing fewer observations), not less. Treat any fixed percentage as a placeholder and confirm with a simulation using the intended metric, randomization, estimator, and decision rule.
Summary Table
| Test Type | How to find Sample Size ($n$) |
|---|---|
| Z-test / T-test | Simple Algebra Formula |
| ANOVA / Chi-Square | Use G*Power or statsmodels (Effect Size inputs required) |
| Permutation / Bootstrap | Simulation Loop (Generate fake data $\to$ Check Power $\to$ Adjust $n$) |
3. From Sample Size to Duration
A sample size is a headcount, not a calendar. To turn it into a launch plan:
\[\text{duration} \approx \frac{\text{required eligible units}}{\text{eligible units per day}}.\]The raw division is only a first pass. Adjust it for:
- Allocation ratio. A 90/10 split reaches the treatment sample far more slowly than 50/50; the arm with less traffic drives the duration.
- Eligibility and exposure. Only users who actually trigger the change count; if 40% of traffic is eligible, the effective daily rate is 40% of the total.
- Attrition and missing outcomes. Budget for dropout and for outcomes that never arrive.
- Weekday and seasonal cycles. Run at least one to two full weeks so weekends and weekly patterns are represented; do not extrapolate from a single midweek day.
- Delayed conversions. If the outcome (a purchase, a renewal) can occur days after exposure, the analysis window must wait for those conversions to mature, even after the headcount is reached.
- Ramp-up. Traffic is often dialed up gradually (1% to 5% to 50%), and the low-exposure early days contribute little.
The practical rule: do not simply stop on the day the count is hit if the pre-specified design requires complete outcome windows or full weekly cycles.
4. Design Effects: When the Simple Formula Is Not Enough
The formulas above assume independent units, equal allocation, and a single comparison. Real experiments often break those assumptions, and each one changes the required sample:
- Unequal allocation raises the total sample needed for a given power (a balanced 50/50 split is the most efficient for a fixed total).
Clustered randomization. If we randomize by cluster (store, account, class) rather than by individual, correlated outcomes within a cluster inflate the variance by the design effect
\[\text{design effect} \approx 1 + (m-1)\rho,\]where $m$ is the average cluster size and $\rho$ the intra-cluster correlation. The effective sample size is the nominal size divided by this factor, and unequal cluster sizes need more careful treatment still.
- High-variance or ratio metrics (revenue per user, ratios of counts) need either a larger sample or variance reduction such as CUPED, which uses pre-experiment covariates to shrink the variance, and thus the required sample.
- Multiple primary comparisons (several variants or several primary metrics) require a multiplicity-adjusted $\alpha$, which raises the per-comparison sample.
5. Fixed-Horizon versus Sequential Designs
A sample size is not a stopping rule. Computing $n$ tells us how much data a valid analysis needs; it does not license watching the p-value and stopping the moment it dips below 0.05. As covered in the foundations post, that “peeking” inflates the false-positive rate far above the nominal $\alpha$. Choose one of:
- a fixed-horizon design: fix $n$ (and the calendar window) in advance and analyze once, at the planned end; or
- a valid sequential design built for continuous monitoring, such as group-sequential boundaries, alpha-spending, always-valid p-values, or confidence sequences.
What is not valid is running a fixed-horizon test and treating it as if it were sequential.
6. What is Sample Ratio Mismatch (SRM)?
When we design an A/B test, we define a target traffic split: most commonly a 50/50 allocation between the Control and Treatment groups. Sample Ratio Mismatch (SRM) occurs when the actual, observed traffic split during the experiment deviates from this planned ratio by a statistically significant margin.
For example, if we plan a 50/50 split and run the test until we hit 100,000 total visitors, we expect roughly 50,000 in Control and 50,000 in Treatment. If our final counts are 50,500 in Control and 49,500 in Treatment, it might look like a minor 1% variance. However, at scale, we must prove whether this deviation is just random noise or a symptom of a broken experiment.
How to Detect SRM: The Chi-Square Test in Action
To prove that the mismatch isn’t just random noise, we don’t use a standard Z-test or t-test, we use a Chi-Square Goodness of Fit test. This test compares our observed counts ($O$) against our expected counts ($E$).
The test statistic is calculated as:
\[\chi^2 = \sum \frac{(O - E)^2}{E}\]Let’s plug in our example numbers of 100,000 total visitors:
- Expected ($E$): 50,000 Control, 50,000 Treatment
- Observed ($O$): 50,500 Control, 49,500 Treatment
Step 1: Calculate the Chi-Square value
- Control: $\frac{(50,500 - 50,000)^2}{50,000} = \frac{500^2}{50,000} = \frac{250,000}{50,000} = 5$
- Treatment: $\frac{(49,500 - 50,000)^2}{50,000} = \frac{(-500)^2}{50,000} = \frac{250,000}{50,000} = 5$
- Total $\chi^2$ $= 5 + 5 = \mathbf{10}$
Step 2: Compare against the Critical Value Because we have 2 categories (Control and Treatment), our Degrees of Freedom ($df$) is $2 - 1 = \mathbf{1}$.
Now we look at the Chi-Square distribution table for $df=1$:
- If we use a standard significance level of $\alpha = 0.05$ (95% confidence), the critical value is 3.84. Since $10 > 3.84$, we would flag this as a significant mismatch.
- A much stricter threshold is common for SRM, often $\alpha = 0.001$ (99.9% confidence) or lower. Why? Because raising an SRM flag forces us to investigate, and possibly discard, an entire experiment, so we want to be nearly certain it is broken first. The critical value for $\alpha = 0.001$ is 10.83. Note that this threshold is a platform policy, not a statistical law: Microsoft’s experimentation guidance, for instance, uses $\alpha = 0.0005$. Pick a threshold deliberately and apply it consistently.
The Verdict: Because our calculated $\chi^2$ of 10 is just barely less than the strict critical value of 10.83 (a p-value of roughly 0.0016), we would technically fail to reject the null at the 0.001 level. We can cautiously proceed, but this is a warning sign worth investigating. If the gap widened even slightly (say 50,600 vs 49,400, giving $\chi^2 = 14.4$ and a p-value near 0.00015), it would clear the threshold and trigger an SRM alert, and we would treat the test as suspect until the cause is found.
The Implications: Why SRM is a Nightmare
If a test triggers a true SRM, every other statistical calculation in our experiment is instantly invalidated. We cannot trust our Z-tests, our p-values, or our effect sizes.
Here is why SRM breaks the experiment:
- Violation of Randomization: A/B testing relies on the core assumption of a Randomized Controlled Trial (RCT): that the only difference between the two groups is the treatment itself. SRM indicates a systemic bias in how users are being sorted or tracked, meaning the groups are no longer mutually exclusive and unbiased.
- Simpson’s Paradox & Survivorship Bias: If our Treatment variant causes older, slower devices to crash before the tracking pixel fires, our Treatment group will artificially look like it has a higher conversion rate because the lowest-performing users were literally excluded from the data pool. The SRM is the only warning sign that this happened.
- It is the cause, not the unequal counts, that biases the result. A common misconception is that skewed group sizes make the standard errors “wrong.” They do not: the standard two-proportion and two-mean formulas handle unequal $n_1 \neq n_2$ perfectly well. The real problem is that SRM signals the imbalance was produced by a mechanism related to the treatment or the outcome (a crash, a filter, a logging gap), which is exactly the confounding randomization was supposed to eliminate. SRM is therefore a symptom to investigate, not a diagnosis, and certainly not a cue to silently rebalance or delete observations.
Common Engineering Culprits Behind SRM
In digital adtech and web experimentation, SRM is rarely a math error, it is almost always a telemetry or engineering bug. Common causes we see include:
- Redirect Latency: If the Treatment requires a heavy client-side redirect, users on slow connections might bounce before the redirect completes and the analytics event fires. Control gets logged, Treatment does not.
- Tracking Bugs in the Variant: The new code in the Treatment might inadvertently break the analytics tracking pixel for a specific browser or edge case.
- Bad Hash Functions: The randomizer assigning users to groups (usually via hashing a user ID or cookie) might not be uniformly distributed, causing collisions that favor one bucket.
- Bot Traffic Skew: Bots often do not manage cookies properly. If a bot gets assigned to Treatment, drops its cookie, and returns, it might get re-assigned, skewing our unique user counts.
An SRM Debugging Checklist
When an SRM fires, walk the pipeline from intent to analysis and find the first stage where the ratio breaks:
- Verify the planned ratio was configured correctly (a mis-entered 60/40 will “fail” a 50/50 check for a mundane reason).
- Check the assignment logs: does the randomizer emit the intended split? Hash a large sample of IDs and count the buckets.
- Compare exposure logs: of those assigned, did the intended fraction actually get exposed? A drop here points to redirects, crashes, or triggering logic.
- Segment by platform, browser, geography, and time: an SRM concentrated in one segment (old Android, a region, a launch hour) usually pinpoints the bug.
- Check for overlaps: another running experiment, a bot or employee filter applied to only one arm, or a broken assignment/exposure join.
- Fix and rerun if validity is compromised; do not “correct” the data of a completed test.
Where This Leads
Power calculations tell us how to run a randomized experiment well. They do not make observational treatment assignment random. When we cannot randomize (historical data, ethical or technical constraints), we need extra assumptions to recover a causal effect. The next post develops those methods: difference-in-differences, propensity-score matching, and instrumental variables.
Resources
- Kohavi, R., Tang, D. & Xu, Y. (2020). Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Cambridge University Press.
- Microsoft Experimentation Platform. Diagnosing Sample Ratio Mismatch in A/B Testing.
- statsmodels: power and sample-size calculations.