Missing Data Imputation: From Mechanisms to a Leakage-Safe Workflow
MCAR/MAR/MNAR as assumptions not labels, what MICE and Rubin's rules really do, and a leakage-safe imputation workflow for prediction and inference.
Missingness Is a Property of the Process, Not the Data
Understanding why a value is missing dictates what we can and cannot do about it. The three classic mechanisms, MCAR, MAR, and MNAR, are assumptions about the process that produced the missingness, not labels we can read directly off a dataset.
To state them precisely, let $R$ be a missingness indicator: $R = 1$ when a value is observed and $R = 0$ when it is missing. Split the data into an observed part $Y_{\text{obs}}$ and a missing part $Y_{\text{mis}}$. Each mechanism differs in what the probability of $R$ is allowed to depend on.
MCAR (Missing Completely At Random)
- Definition: $P(R)$ depends on neither $Y_{\text{obs}}$ nor $Y_{\text{mis}}$. Missingness is unrelated to anything in the data.
- Analogy: a lab assistant drops a random test tube. The loss is pure chance.
- Consequence: the observed rows are a random subsample, so complete-case estimates of quantities like a mean stay unbiased (though less precise). This is the only mechanism under which the data “just vanished at random,” and it is rarely exactly true in practice.
MAR (Missing At Random)
- Definition: conditional on the observed variables, $P(R)$ does not additionally depend on the missing value. The missingness is explainable by data we already have.
- Analogy: suppose women report weight less often than men. If
Genderis observed and included in the model, then within each gender the weight missingness is random, so the pattern is MAR with respect to that model. - The catch: MAR is a statement about a specific set of conditioning variables. “Women report weight less often” is only MAR if the observed variables the imputation model uses actually capture that pattern. Leave
Genderout and the same data behaves as MNAR.
MNAR (Missing Not At Random)
- Definition: even after conditioning on all observed information, $P(R)$ still depends on the missing value itself (or on something unobserved).
- Analogy: high earners decline to report income because it is high; severe-depression respondents skip the survey because they are severely depressed. The missing values are systematically unlike the observed ones.
- Consequence: the observed distribution is a biased view of the truth (the observed mean is too low), and conditioning on other columns does not fix that.
The uncomfortable truth: MAR and MNAR generally cannot be distinguished from the observed data alone, because the data we can see looks the same under both. Telling them apart needs domain knowledge, the collection design, external data, or sensitivity analysis. Diagnostics can reject an implausible MCAR story, but they cannot prove MAR or rule out MNAR.
Handling, Without the False Certainty
The tidy mapping “MCAR needs mean imputation, MAR needs MICE, MNAR needs an Unknown category” is too neat. A more honest reading:
- Under MCAR, deletion does not bias estimates, but it still discards data and precision. Single mean or median imputation is not “perfectly fine”: it shrinks variance, biases correlations and regression slopes toward zero, piles probability mass on one value, and makes ordinary standard errors overconfident because guessed values are treated as known. It can serve as a predictive baseline when validated out of sample, but it is poor for inference and for preserving relationships.
- Under MAR, resist a universal rule. Deletion can be unbiased or badly biased depending on whether the missing variable is a feature or the outcome, whether the goal is prediction or inference, how much is missing, and whether the variables explaining the missingness are in the model. Multivariate methods like MICE are a principled option when their conditional models fit the data and the important predictors are included, not an automatic gold standard.
- Under MNAR, standard imputation (mean or MICE) is fundamentally biased, because the observed data misrepresents the missing data. An
"Unknown"category can preserve a useful predictive signal, but it does not make the mechanism ignorable or recover the missing distribution. The real options are to model the missingness with domain experts (selection models, pattern-mixture models), bring in auxiliary or external variables, and run delta-adjustment or tipping-point sensitivity analyses that ask how far the missing values would have to differ before the conclusion changes.
One distinction the three mechanisms miss entirely: structural missingness. A customer with no mortgage has no mortgage rate; that cell is “not applicable,” not “unreported.” It usually deserves its own explicit state and should not be imputed as if a hidden value existed.
| Mechanism | What it means | What it does not mean |
|---|---|---|
| MCAR | Missingness unrelated to any data | That mean imputation is harmless; it still distorts variance and correlations |
| MAR | Explainable by observed variables in the model | That it holds regardless of which variables are included |
| MNAR | Depends on the missing value even given observed data | That an “Unknown” category or MICE repairs it |
MICE: Imputation as a Round-Robin of Conditional Models
MICE (Multiple Imputation by Chained Equations, also called fully conditional specification) is an iterative method that, unlike single mean imputation, represents the uncertainty of the missing values by producing several plausible completed datasets.
The core idea: treat each variable with missing data as the target of a regression on all the other variables, and cycle through those regressions until the fills stabilize.
The MICE Algorithm (Step-by-Step)
Let’s use a dataset with three features: Age, Income, and Credit_Score.
- Data:
AgeandIncomehave missing values.Credit_Scoreis complete.
Step 1: Initialization (Fill the Holes)
MICE starts by filling all missing values with a simple placeholder, like the mean of that column.
- Initial State: We now have a “complete” dataset, but the filled values are just rough guesses.
Step 2: The “Chained Equations” (The Iteration)
We now cycle through the columns with missing data one by one.
Iteration 1:
- Target:
Age:- We set the imputed
Agevalues back to missing (NaN). - We build a regression model (e.g., Linear Regression) where:
- y (Target): The known
Agevalues. - X (Features):
Income(currently filled with mean) andCredit_Score.
- y (Target): The known
- We train the model on the rows where
Ageis known. - We use the model to predict the missing
Agevalues. - Update: We replace the placeholder means in
Agewith these new, smarter predictions.
- We set the imputed
- Target:
Income:- We set the imputed
Incomevalues back to missing. - We build a regression model where:
- y (Target): The known
Incomevalues. - X (Features):
Age(now filled with the smart predictions from step 1) andCredit_Score.
- y (Target): The known
- We train and predict.
- Update: We replace the placeholder means in
Incomewith these new predictions.
- We set the imputed
Step 3: Repeat for Several Cycles
We repeat the Step 2 cycle several times.
- In cycle 2, the model for
Agetrains on the smarterIncomefills from cycle 1 rather than the crude mean, and vice versa. - A handful of cycles is usually enough for the chain to settle. “Convergence” here does not mean each cell freezes at a fixed number: with the stochastic version below, successive draws are meant to vary. What we watch is that the chain has mixed and shed its dependence on the crude starting values (a burn-in), not that every imputed value stops moving.
Not Every Variable Gets a Linear Model
The walkthrough used linear regression, but the chained equations are only as good as each conditional model. Proper MICE matches the model to the variable type: linear regression or predictive mean matching for continuous values, logistic regression for binary ones, multinomial or ordinal models for categorical ones, and bounded or count models where those fit. Forcing every column through linear regression, or treating an encoded category as a continuous quantity, is a common way to produce implausible fills.
The “Multiple” in MICE
The cycle above produces one completed dataset. To capture uncertainty, MICE repeats the whole process $M$ times, and each repetition must inject two kinds of randomness (the next section unpacks them): uncertainty about the fitted model parameters, and the residual scatter of an individual value around its prediction. The result is $M$ completed datasets that differ in their imputed cells.
How large should $M$ be? The old “5 to 10” rule of thumb is dated. The number needed grows with the fraction of missing information and the Monte-Carlo precision required; modern practice often uses more than five, and the honest approach is to check the Monte-Carlo error rather than fix a universal number.
These datasets are not merged into one. Each is analyzed separately and the results combined with Rubin’s rules, which a later section describes properly; it is not simply averaging coefficients.
What It Buys, and What It Assumes
Because it predicts each missing value from the other variables, MICE preserves relationships and correlations far better than mean/median imputation, and, done properly (see below), it carries the uncertainty of the fills into the final answer. It leans on a MAR assumption: that the observed variables in the conditional models explain the missingness. When that holds and the models are well specified, MICE is a strong choice, especially for inference. When predictors are themselves missing, nonlinearities or interactions go unmodeled, categories are rare, or the mechanism is really MNAR, it can still mislead.
Where the Randomness Comes From
This is what separates real multiple imputation from single imputation. Fill every hole with a single best guess and we get one artificially tidy dataset; the downstream analysis then treats those guesses as if they were measured and underestimates its own uncertainty.
Deterministic prediction destroys variance
Deterministic regression imputation (what IterativeImputer does in its default, non-sampling mode) fills each hole with the model’s point prediction.
- Model:
Income = 1000 * Age + 5000. - A missing income for a 30-year-old: the prediction is
1000 * 30 + 5000 = 35,000.
But not every 30-year-old earns exactly \$35,000. Filling all of them with \$35k lays the imputed points on a perfectly straight line, erasing the natural scatter of the data and shrinking the variance of Income. Its correlations with other variables get distorted toward the model’s own structure.
Proper imputation draws from a distribution, using two sources of uncertainty
A correct stochastic imputation replaces the point prediction with a draw, and that draw must reflect two distinct uncertainties:
- Parameter uncertainty. We do not actually know the regression coefficients; we estimated them from a finite, partly-missing sample. So each imputation first draws a plausible set of coefficients (from their posterior, or via a bootstrap refit) instead of reusing one fixed line. This is the source the “prediction + noise” story omits, and omitting it is exactly why naive stochastic regression still understates uncertainty.
- Residual uncertainty. Even with the coefficients fixed, a real value scatters around the line, so we then add a random residual drawn from the estimated error distribution (roughly, a normal with the regression’s residual standard deviation).
Across the $M$ datasets both the line and the residual vary, so the imputed 30-year-olds scatter around the trend the way real data does, and the spread between datasets encodes how little we truly know. Predictive mean matching is a popular alternative that sidesteps distributional assumptions by donating an observed value from a similar record.
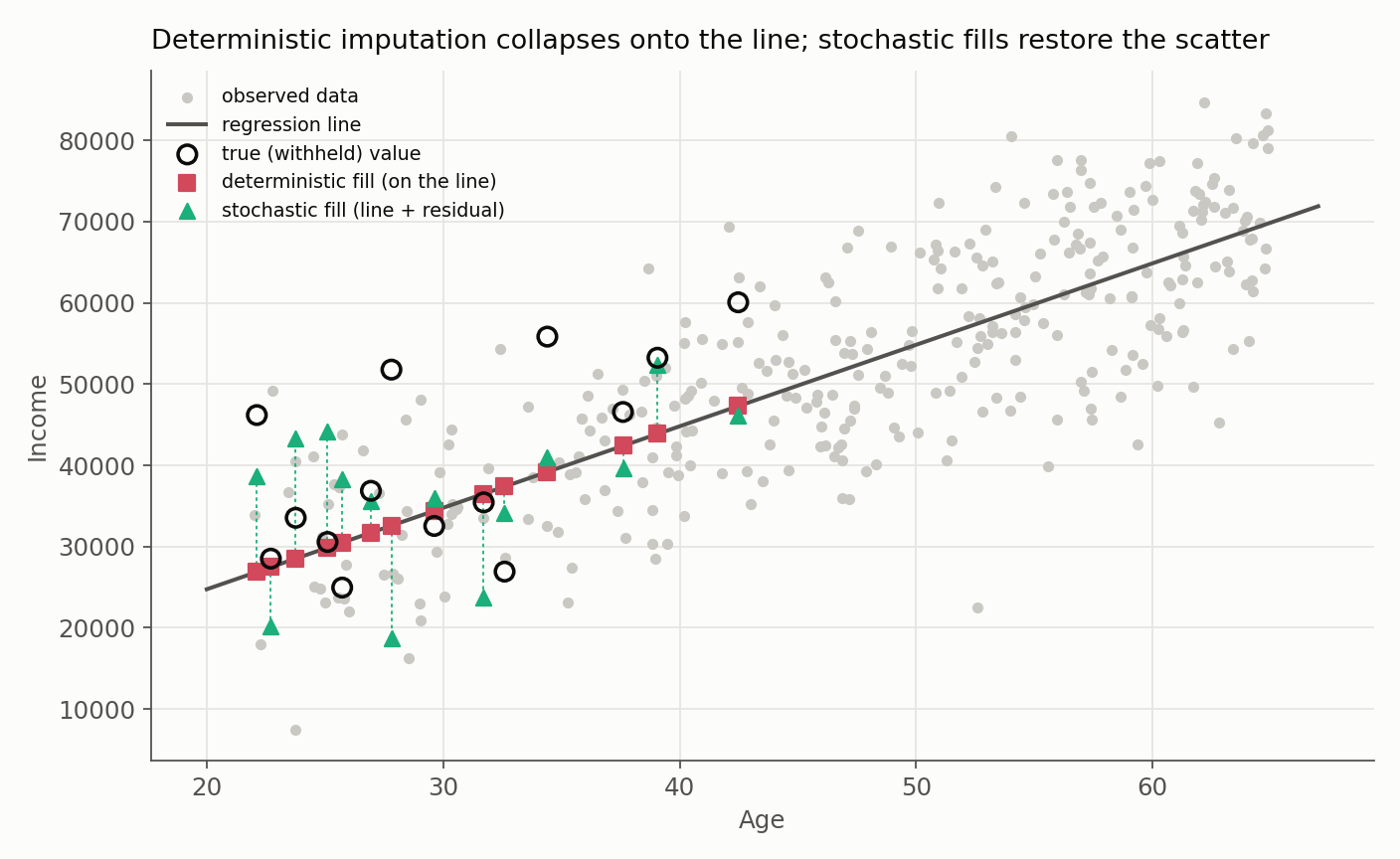
The figure makes the cost of determinism visible. The deterministic fills (squares) lie exactly on the regression line, a row of artificially perfect points that shrinks the variance of Income. The stochastic fills (triangles) scatter around the line just as the true withheld values (open circles) do. Notice too that the missing rows bunch toward younger ages: missingness here depends on the observed Age, the defining feature of MAR.
Combining the datasets: Rubin’s rules, done right
With $M$ completed datasets in hand, we analyze each separately, producing an estimate $Q_m$ of whatever quantity we care about (a coefficient, a mean, a risk ratio) together with its own variance $U_m$. Rubin’s rules combine them. The pooled estimate is the average,
\[\bar Q = \frac{1}{M}\sum_{m=1}^{M} Q_m,\]but the real content is the variance, which has two parts:
- the within-imputation variance $\bar U = \frac{1}{M}\sum_m U_m$, the ordinary sampling uncertainty averaged across datasets;
- the between-imputation variance $B = \frac{1}{M-1}\sum_m (Q_m - \bar Q)^2$, how much the estimate moves because of the missing data.
The total variance is
\[T = \bar U + \left(1 + \tfrac{1}{M}\right) B.\]That extra $B$ term is the whole payoff: standard errors widen to reflect the imputation uncertainty, so confidence intervals stay honest instead of overconfident. Averaging a handful of coefficients and stopping there, as a naive reading suggests, throws that away.
A caveat for predictive ML
Rubin’s rules are built for inference on a well-defined scalar estimand. For a predictive model fed into, say, XGBoost, averaging fitted coefficients across imputations is not generally meaningful (the parameters of arbitrary models are not comparable that way). Sensible options are to pool a clearly defined quantity, to average the predictions of models trained on the different imputations, or, when only out-of-sample predictive performance matters, to use a single well-validated, leakage-safe imputation pipeline. Which one is right depends on whether the goal is inferential standard errors or predictive accuracy, a fork worth making explicit.
Inference or Prediction? Decide First
Almost every argument about imputation dissolves once the goal is named, because the goal changes what “good” means.
If the goal is statistical inference (unbiased coefficients, honest standard errors, confidence intervals, sensitivity to assumptions), representing uncertainty is the job. Multiple imputation with a compatible analysis model and proper Rubin pooling is often the right tool, and the between-imputation variance is the point, not overhead.
If the goal is prediction (a model scored on held-out data, deployed, monitored), the priorities shift to validation performance, calibration, robustness, and behavior when the missingness rate drifts in production. Here a humble median or mode imputer plus a missingness indicator, fit inside the pipeline, frequently matches or beats elaborate imputation, and some models handle missing values natively: XGBoost, LightGBM, and scikit-learn’s HistGradientBoosting learn a default direction for NaN at each split, so an explicit imputer may be unnecessary. No method earns its place without out-of-sample evaluation.
The failure mode to avoid is importing a procedure designed for inferential uncertainty (multiple imputation plus pooling) and bolting it onto a predictive pipeline by reflex, where a validated single imputation would be simpler, cheaper to serve, and often just as accurate.
A Leakage-Safe scikit-learn Implementation
The single most important implementation rule has nothing to do with which imputer to pick: never fit the imputer on the whole dataset before splitting. Doing so lets the validation and test distributions bleed into training, because the imputed values and any learned statistics “see” data the model is about to be scored on, which silently inflates the reported metric. The same rule covers scaling, encoding, feature selection, and missingness indicators. The fix is to put imputation inside a Pipeline so it is refit on each training fold only:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import numpy as np
import pandas as pd
from sklearn.experimental import enable_iterative_imputer # noqa: F401 (still experimental)
from sklearn.impute import IterativeImputer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import BayesianRidge
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.model_selection import cross_val_score, train_test_split
# X: numeric features with NaNs (e.g. Age, Income, Credit_Score); y: the target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
pipe = Pipeline([
# sample_posterior=True draws from the predictive distribution instead of
# returning the mean; BayesianRidge supplies the required return_std.
("impute", IterativeImputer(estimator=BayesianRidge(), sample_posterior=True,
max_iter=20, random_state=0)),
("model", HistGradientBoostingRegressor(random_state=0)),
])
# CV refits the imputer on each fold, so the held-out fold never touches it.
scores = cross_val_score(pipe, X_train, y_train, cv=5)
pipe.fit(X_train, y_train) # final fit on training data only
What IterativeImputer does and does not do. It is scikit-learn’s MICE-style tool, but the details matter:
- it is still experimental (hence the
enable_iterative_imputerimport); - one call returns one imputed dataset; true multiple imputation means repeating the fit with different seeds and pooling the results separately;
sample_posterior=Truerequires an estimator that reports predictive standard deviations viareturn_std(BayesianRidgedoes);- it works on numeric arrays, so categorical columns need their own encoding or modeling strategy, it is not a drop-in for mixed data;
- bounds can be enforced with
min_valueandmax_value(useful for non-negative income or a realistic age range); - it does not pool downstream results; Rubin’s rules must be applied on top.
For genuine multiple imputation, loop over seeds and combine afterward:
1
2
3
4
5
6
imputations = []
for seed in range(20): # M = 20, not a magic 5
imp = IterativeImputer(estimator=BayesianRidge(), sample_posterior=True,
max_iter=20, random_state=seed)
imputations.append(imp.fit_transform(X_train)) # fit within the training split
# fit the analysis model on each imputation, then combine with Rubin's rules
For inference-grade pooling out of the box, statsmodels has a dedicated MICE module (statsmodels.imputation.mice) that applies Rubin’s rules and returns pooled estimates with confidence intervals. Reach for statsmodels when reporting p-values and intervals, and for the sklearn pipeline when the goal is a validated predictor.
Categorical and Structurally-Missing Values
Categorical columns (Gender, City, Product_Type) need their own strategies, and the same “don’t map one mechanism to one method” caution applies.
- Explicit missing category. Replace
NaNwith a distinct level like"Unknown", then let the model learn a weight for it. This is a modeling choice, not a fix for MNAR: it can preserve an informative missingness signal for prediction, but it does not recover the true category distribution or remove selection bias. Use safe assignment,df["Gender"] = df["Gender"].fillna("Unknown"), rather than the chainedinplace=Trueform. - Mode (most-frequent) imputation. A reasonable baseline, but its suitability is not established by MCAR alone. With many missing cells it inflates the majority class and distorts the distribution, so validate it rather than assume it.
- Marginal probabilistic sampling. Filling in proportion to observed frequencies (60%
Red, 40%Blue) preserves the marginal distribution, but because it ignores the other columns it can destroy the relationships between this feature and the rest, exactly what a predictive model needs. - Predictive (classification) imputation. Train a classifier on the other features to predict the missing category. Better at respecting MAR structure, but a single hard prediction is still single imputation: it needs uncertainty, out-of-sample validation, and the same leakage controls (fit inside the training fold only). Rare categories, high cardinality, unseen categories at serving time, and ordinal variables each need separate care.
Two cross-cutting points. First, add a missingness indicator $R_j$ (a 0/1 column flagging where the value was absent) as a candidate feature; it can lift predictive performance when missingness is informative, though it does not by itself correct an unidentified MNAR mechanism. Second, keep “unknown” and “not applicable” distinct: a structurally absent category (a customer with no mortgage) deserves its own explicit state and should not be imputed as if a hidden value existed.
From Mechanism to Method: A Working Recipe
Because no label maps cleanly to one method, treat imputation as a short loop rather than a lookup:
- Audit the missingness. Count the missing fraction per column, look for co-occurring patterns (columns that go missing together), and check whether missingness varies by time, source, or the label. Compare rows with and without a value on the observed variables. These diagnostics can kill an implausible MCAR story, but they cannot prove MAR or rule out MNAR.
- Establish baselines. Line up complete-case analysis (where defensible), median/mode plus a missingness indicator, an explicit constant category, KNN or iterative imputation, model-native handling, and, for a defined inferential estimand, multiple imputation. Do not crown a winner in advance.
- Validate without pretending the truth is known. Mask a subset of genuinely observed values under a realistic missingness pattern and measure imputation error on them; compare observed-versus-imputed distributions; check that key correlations and subgroup behavior survive; and, above all, evaluate the downstream model under cross-validation. Low imputation RMSE alone guarantees neither the best predictor nor unbiased inference.
- Stress-test the assumptions. For plausible MNAR, shift the imputed values by domain-reasonable deltas (a tipping-point analysis) and report whether the substantive decision changes, not merely which imputer scored best.
- Monitor after deployment. Missingness rates drift and new patterns appear. Track the missing rate per feature and source, imputation-fallback frequency, and post-imputation distribution and calibration drift.
Choosing a Starting Point
No row here is a recipe; each is a default to validate, not a verdict.
| Situation | Reasonable starting point | Main caveat |
|---|---|---|
| Low missingness, predictive task | Median/mode + missingness indicator, inside a pipeline | Compare against model-native handling and subgroup effects |
| MAR plausible, inferential task | Multiple imputation with an analysis-compatible model | Pool estimates and variances; check model specification |
| Mixed numeric/categorical MAR | Type-appropriate chained equations | Do not treat encoded categories as continuous |
| Plausible MNAR | Explicit sensitivity or delta adjustment | The missing distribution is not identified from observed data alone |
| Structural “not applicable” | A separate semantic state | Do not impute a value that conceptually does not exist |
| Time-series or grouped data | Group- or time-aware method | Row-wise random imputation can leak future or cross-entity information |
Resources
- van Buuren, S. (2018). Flexible Imputation of Missing Data (2nd ed.). Chapman & Hall/CRC. See multiple imputation in a nutshell and how to generate multiple imputations.
- Rubin, D. B. (1976). Inference and missing data. Biometrika, 63(3), 581-592. (The paper that formalized MCAR/MAR/MNAR.)
- Rubin, D. B. (1987). Multiple Imputation for Nonresponse in Surveys. Wiley. (Rubin’s rules.)
- van Buuren, S. & Groothuis-Oudshoorn, K. (2011). mice: Multivariate Imputation by Chained Equations in R. Journal of Statistical Software, 45(3), 1-67.
- Little, R. J. A. & Rubin, D. B. (2019). Statistical Analysis with Missing Data (3rd ed.). Wiley.
- scikit-learn:
IterativeImputer- thesample_posterior,return_std, andmin_value/max_valuebehavior used above.