Support Vector Machines, Part 1: Geometry, Margins, and Hinge Loss
Build the linear SVM from hyperplane geometry: signed distance, the maximum-margin primal, why the boundaries are fixed at plus/minus one, and the soft-margin hinge-loss objective.
Support Vector Machines series: Part 1: Geometry, Margins, and Hinge Loss · Part 2: The Dual and Support Vectors · Part 3: The Kernel Trick · Part 4: One-Class SVM for Novelty Detection
A Support Vector Machine looks for the widest possible empty “street” between two classes and puts the decision boundary down its center. This first part builds that idea from the ground up: the geometry of a hyperplane, the distance from a point to it, the hard-margin optimization that maximizes the street, why the margin boundaries are fixed at plus and minus one, and finally the soft margin and hinge loss that let realistic, noisy data through. Part 2 re-expresses the problem in its dual form, Part 3 introduces the kernel trick, and Part 4 turns the machinery to one-class novelty detection.
1. Hyperplanes: The Equation of a Decision Boundary
This is a fundamental concept in linear algebra and geometry. To understand why a hyperplane is defined by $\mathbf{w} \cdot \mathbf{x} + b = 0$, we need to look at the geometric relationship between a vector and a plane.
1. The Geometric Definition
A line in 2D (or a plane in 3D, or hyperplane in $n$D) can be uniquely defined by two things:
- A fixed point that lies on the plane, let’s call it $\mathbf{x}_0$.
- A vector that is perpendicular (normal) to the plane, let’s call it $\mathbf{w}$.
2. The Derivation
Let $\mathbf{x}$ be any arbitrary point $[x_1, x_2, \dots, x_n]$ lying anywhere on this hyperplane.
If we draw a vector from the fixed point $\mathbf{x}_0$ to this arbitrary point $\mathbf{x}$, we get the vector $\mathbf{x} - \mathbf{x}_0$.
Since both $\mathbf{x}$ and $\mathbf{x}_0$ lie on the plane, the vector connecting them ($\mathbf{x} - \mathbf{x}_0$) must lie flat on the plane.
By definition, the normal vector $\mathbf{w}$ is perpendicular to every vector that lies on the plane. Therefore, $\mathbf{w}$ must be perpendicular to $(\mathbf{x} - \mathbf{x}_0)$.
The Orthogonality Condition: Two vectors are perpendicular if and only if their dot product is zero.
\[\mathbf{w} \cdot (\mathbf{x} - \mathbf{x}_0) = 0\]3. Expanding the Equation
Let’s distribute the dot product:
\[\mathbf{w} \cdot \mathbf{x} - \mathbf{w} \cdot \mathbf{x}_0 = 0\]Now, look at the second term, $\mathbf{w} \cdot \mathbf{x}_0$.
- $\mathbf{w}$ is a fixed constant vector (the normal).
- $\mathbf{x}_0$ is a fixed constant point on the plane.
- Therefore, their dot product is just a scalar constant.
Let’s define this scalar constant as $-b$.
\[b = -(\mathbf{w} \cdot \mathbf{x}_0)\]Substituting this back into our equation:
\[\mathbf{w} \cdot \mathbf{x} + b = 0\]Summary of Terms
- $\mathbf{w}$ (Weight Vector): Defines the orientation of the hyperplane. It points perpendicular to the surface.
- $b$ (Bias): Defines the position of the hyperplane relative to the origin.
- If $b=0$, the hyperplane passes directly through the origin (because if $\mathbf{x}=\mathbf{0}$, then $\mathbf{w} \cdot \mathbf{0} + 0 = 0$).
- Changing $b$ shifts the plane parallel to itself without changing its orientation.
This is why in SVM and linear algebra, this compact notation represents any flat boundary in any dimension.
2. The Distance From a Point to the Hyperplane
This is a classic vector geometry derivation. To find the distance, we project the vector connecting the plane to the point onto the plane’s normal vector.
The Setup
- The Hyperplane: Defined by $\mathbf{w} \cdot \mathbf{x} + b = 0$.
- The Point: An arbitrary point $\mathbf{x}_i$ that is somewhere in space (not necessarily on the plane).
- The Projection: Let $\mathbf{x}_p$ be the point on the hyperplane that is closest to $\mathbf{x}_i$. This means the line connecting $\mathbf{x}_i$ and $\mathbf{x}_p$ is perpendicular to the plane.
- The Distance ($d$): This is the length of the vector between $\mathbf{x}_i$ and $\mathbf{x}_p$.
The Derivation
Step 1: Define the Relationship Vector Since the line connecting $\mathbf{x}_i$ and $\mathbf{x}_p$ is perpendicular to the plane, it must be parallel to the normal vector $\mathbf{w}$.
We can express $\mathbf{x}_i$ as starting from $\mathbf{x}_p$ and moving a distance $d$ in the direction of the unit normal vector $\frac{\mathbf{w}}{\|\mathbf{w}\|}$.
\[\mathbf{x}_i = \mathbf{x}_p + d \frac{\mathbf{w}}{\|\mathbf{w}\|}\](Note: $d$ here is technically a signed distance. It could be positive or negative depending on which side of the plane the point is. We will take the absolute value at the end).
Step 2: Isolate the Point on the Plane ($\mathbf{x}_p$) Let’s rearrange the equation to solve for $\mathbf{x}_p$:
\[\mathbf{x}_p = \mathbf{x}_i - d \frac{\mathbf{w}}{\|\mathbf{w}\|}\]Step 3: Use the Hyperplane Constraint This is the crucial step. Since $\mathbf{x}_p$ lies on the hyperplane, it must satisfy the hyperplane equation:
\[\mathbf{w} \cdot \mathbf{x}_p + b = 0\]Now, substitute the expression for $\mathbf{x}_p$ from Step 2 into this equation:
\[\mathbf{w} \cdot \left( \mathbf{x}_i - d \frac{\mathbf{w}}{\|\mathbf{w}\|} \right) + b = 0\]Step 4: Distribute and Simplify Expand the dot product:
\[\mathbf{w} \cdot \mathbf{x}_i - d \frac{\mathbf{w} \cdot \mathbf{w}}{\|\mathbf{w}\|} + b = 0\]Recall that the dot product of a vector with itself is the square of its norm ($\mathbf{w} \cdot \mathbf{w} = \|\mathbf{w}\|^2$):
\[\mathbf{w} \cdot \mathbf{x}_i + b - d \frac{\|\mathbf{w}\|^2}{\|\mathbf{w}\|} = 0\]Cancel out one $\|\mathbf{w}\|$ term in the fraction:
\[\mathbf{w} \cdot \mathbf{x}_i + b - d \|\mathbf{w}\| = 0\]Step 5: Solve for Distance ($d$) Move the term with $d$ to the other side:
\[d \|\mathbf{w}\| = \mathbf{w} \cdot \mathbf{x}_i + b\] \[d = \frac{\mathbf{w} \cdot \mathbf{x}_i + b}{\|\mathbf{w}\|}\]Step 6: Absolute Distance Since geometric distance is always non-negative, and $\mathbf{w} \cdot \mathbf{x}_i + b$ could be negative (if the point is on the negative side of the plane), we take the absolute value of the numerator.
\[\text{Distance} = \frac{|\mathbf{w} \cdot \mathbf{x}_i + b|}{\|\mathbf{w}\|}\]Connection to SVM
This formula explains why maximizing the margin works the way it does. For a Support Vector, we enforce that $\lvert \mathbf{w} \cdot \mathbf{x}_{sv} + b \rvert = 1$. Substituting this into the distance formula above gives the one-sided geometric margin, the distance from the hyperplane to the nearest point on either side:
\[\gamma = \frac{1}{\lVert \mathbf{w} \rVert}.\]The full margin width (the distance between the two margin boundaries, which we derive in Section 3) is twice this, $2/\lVert \mathbf{w} \rVert$. We will keep the two names distinct throughout, since both appear in the literature and calling each simply “the margin” invites confusion. Either way, minimizing $\lVert \mathbf{w} \rVert$ maximizes the physical separation between the hyperplane and the support vectors.
3. The Hard-Margin Primal Formulation
This is the culmination of our previous steps. We will now assemble the pieces - the hyperplane definition, the distance formula, and the concept of scaling, to build the complete Primal Formulation of the Support Vector Machine.
1. The Problem Statement
Goal: Given a set of linearly separable data points belonging to two classes ($y \in \{+1, -1\}$), we want to find the optimal linear decision boundary (hyperplane) that separates them.
Definition of “Optimal”: The optimal hyperplane is the one that maximizes the margin, the width of the empty “street” between the decision boundary and the closest data points from either class. Maximizing that width is a useful inductive bias: it favors a boundary that is not pinned tightly to any single point, and it appears in classical generalization bounds. It is not, on its own, a guarantee of better test performance, which also depends on regularization, kernel choice, noise, feature scaling, and validation. We treat the wide margin as a principled prior, not a promise.
2. Deriving the Margin Boundaries (The “Street”)
Let our decision boundary be the hyperplane:
\[H_0: \mathbf{w} \cdot \mathbf{x} + b = 0\]We assume the data is linearly separable. This means we can find a hyperplane where all positive points ($y=+1$) are on one side and all negative points ($y=-1$) are on the other.
The Canonical Scale (The “Scaling Trick”): We can scale $\mathbf{w}$ and $b$ by any constant without changing the position of the hyperplane $H_0$. To make the math unique and solvable, we fix the scale. (NOTE: We discuss on this in much more detail in the next section, so let’s just assume it to be true for now)
We enforce that for the data points closest to the hyperplane (the Support Vectors), the absolute value of the decision function is exactly 1.
This defines two additional hyperplanes that form the edges of our “street”:
Positive Hyperplane ($H_1$): The boundary for the positive support vectors.
\[\mathbf{w} \cdot \mathbf{x} + b = 1\]Negative Hyperplane ($H_2$): The boundary for the negative support vectors.
\[\mathbf{w} \cdot \mathbf{x} + b = -1\]
3. Deriving the Margin Width
Now we calculate the physical width of the street created by $H_1$ and $H_2$.
We use the distance formula we derived earlier: $d = \frac{\lvert \mathbf{w} \cdot \mathbf{x} + b \rvert}{\lVert \mathbf{w} \rVert}$.
Distance from $H_0$ to $H_1$: Take a point $\mathbf{x}^+$ on the positive hyperplane. We know $\mathbf{w} \cdot \mathbf{x}^+ + b = 1$.
\[d_+ = \frac{|1|}{\|\mathbf{w}\|} = \frac{1}{\|\mathbf{w}\|}\]Distance from $H_0$ to $H_2$: Take a point $\mathbf{x}^-$ on the negative hyperplane. We know $\mathbf{w} \cdot \mathbf{x}^- + b = -1$.
\[d_- = \frac{|-1|}{\|\mathbf{w}\|} = \frac{1}{\|\mathbf{w}\|}\]Full Margin Width ($M$): The full width of the street is the sum of these two one-sided margins:
\[M = d_+ + d_- = \frac{1}{\|\mathbf{w}\|} + \frac{1}{\|\mathbf{w}\|} = \frac{2}{\|\mathbf{w}\|}\]
Conclusion: To maximize the full margin width $M$, we must maximize $\frac{2}{\lVert\mathbf{w}\rVert}$.
4. Deriving the Unified Constraint
We need to ensure that no data points are inside the street. They must all be on the correct side of the margin boundaries.
For Positive Samples ($y_i = +1$): They must be on or above the positive hyperplane $H_1$.
\[\mathbf{w} \cdot \mathbf{x}_i + b \ge 1\]For Negative Samples ($y_i = -1$): They must be on or below the negative hyperplane $H_2$.
\[\mathbf{w} \cdot \mathbf{x}_i + b \le -1\]
Combining them: We can cleverly combine these two inequalities into one. Look at the negative case: $\mathbf{w} \cdot \mathbf{x}_i + b \le -1$. If we multiply both sides by $-1$ (and flip the inequality sign), we get: $-(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1$.
Since $y_i = -1$ for these points, this is the same as: $y_i(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1$. For the positive points, $y_i = +1$, so $1(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1$ holds too.
Thus, the Unified Single Constraint is:
\[y_i(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1 \quad \forall i\]5. The Final Primal Formulation
Now we put it all together into an optimization problem.
The Objective: We want to Maximize $\frac{2}{\|\mathbf{w}\|}$. Maximizing $\frac{2}{\|\mathbf{w}\|}$ is mathematically equivalent to minimizing $\|\mathbf{w}\|$. To make the derivatives easier (avoiding square roots), we square the norm. Minimizing $\|\mathbf{w}\|$ is equivalent to minimizing $\|\mathbf{w}\|^2$. By convention, we add a factor of $\frac{1}{2}$.
So, Maximize Margin $\equiv$ Minimize $\frac{1}{2}\|\mathbf{w}\|^2$.
The Formal Primal Problem:
\[\begin{aligned} & \textbf{Minimize:} & & \frac{1}{2}\|\mathbf{w}\|^2 \\ & \textbf{Subject to:} & & y_i(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1 \quad \text{for } i = 1, \dots, n \end{aligned}\]This is a Convex Quadratic Programming problem. Because it is convex, we are guaranteed that if a solution exists, it is the global minimum, the absolute best separating hyperplane.
4. Why the Margin Boundaries Are Fixed at ±1
That is an excellent and very insightful question. It gets to the heart of how the SVM optimization problem is elegantly formulated.
The short answer is: It’s a clever mathematical simplification. We can set the margin boundaries to +1 and -1 without any loss of generality because of the way the hyperplane equation can be scaled.
Let’s break this down into two key concepts: the Functional Margin and the Geometric Margin.
1. The Problem of a “Floating” Definition
First, let’s consider the general equation of our separating hyperplane:
\[\mathbf{w} \cdot \mathbf{x} + b = 0\]For any point $\mathbf{x}_i$, the value of $\mathbf{w} \cdot \mathbf{x}_i + b$ tells us how far that point is from the hyperplane, at least in a relative sense.
However, notice that if we scale w and b by some constant c, we get the exact same hyperplane:
Let’s call $\mathbf{w}^* = c\mathbf{w}$ and $b^* = cb$. The new equation $\mathbf{w}^* \cdot \mathbf{x} + b^* = 0$ defines the exact same line.
This creates a problem. We could have a point close to the margin, but by just scaling up w and b, we can make the value of w . x + b arbitrarily large. This “floating” value is called the functional margin.
- Functional Margin: \(\hat{\gamma} = y_i(\mathbf{w} \cdot \mathbf{x}_i + b)\) (Here, \(y_i\) is the class label, +1 or -1).
The functional margin tells us if a point is correctly classified (if it’s positive), but its magnitude can be changed just by scaling, which isn’t useful for finding a unique, optimal solution.
2. The Solution: Normalization and the Geometric Margin
What we actually care about is the real, physical distance from a point to the hyperplane. This is called the geometric margin. The formula for the shortest distance from a point $\mathbf{x}_i$ to the hyperplane $\mathbf{w} \cdot \mathbf{x} + b = 0$ is:
- Geometric Margin: \(\gamma = \frac{y_i(\mathbf{w} \cdot \mathbf{x}_i + b)}{\|\mathbf{w}\|}\)
Notice that the geometric margin is just the functional margin normalized by the magnitude of w. Now, if we scale w and b by c, the geometric margin remains unchanged:
This is exactly what we want! A stable, meaningful measure of distance.
3. The Elegance of Setting the Margin to 1
The goal of SVM is to maximize this geometric margin for the points closest to the hyperplane (the support vectors). Let’s call the geometric margin for a support vector \(\gamma_{sv}\).
So, our objective is: Maximize \(\gamma_{sv}\)
\[\gamma_{sv} = \frac{y_{sv}(\mathbf{w} \cdot \mathbf{x}_{sv} + b)}{\|\mathbf{w}\|}\]Here comes the clever trick. Since we can scale w and b by any constant c without changing the geometric margin, we can choose a specific scaling that makes our math easier.
Let’s choose to scale w and b such that for the support vectors (the points closest to the hyperplane), the functional margin is exactly 1.
By enforcing this scaling, we are essentially “pinning down” the functional margin to a fixed value. This hyperplane is now in what is called a canonical form.
What does this do to our optimization problem?
The constraint that all points must be on or outside the margin becomes:
\[y_i(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1\]This is because the support vectors have a functional margin of 1, and all other points must be further away.
The objective of maximizing the geometric margin (\(\gamma_{sv}\)) becomes much simpler. Since we defined \(y_{sv}(\mathbf{w} \cdot \mathbf{x}_{sv} + b) = 1\), the equation for the margin simplifies to:
\[\text{Maximize } \gamma_{sv} = \frac{1}{\|\mathbf{w}\|}\]
Maximizing \(\frac{1}{\|\mathbf{w}\|}\)is the same as minimizing\(\|\mathbf{w}\|\), which is, in turn, the same as minimizing \(\frac{1}{2}\|\mathbf{w}\|^2\) (done for mathematical convenience).
This is the punchline: By fixing the functional margin of the support vectors to 1, we transform a complex maximization problem into a much cleaner minimization problem with a simple constraint.
So, the hyperplanes \(\mathbf{w} \cdot \mathbf{x} + b = 1\) and \(\mathbf{w} \cdot \mathbf{x} + b = -1\) are not arbitrary; they are the result of a deliberate and elegant mathematical choice to fix the scale of the problem, which simplifies the entire optimization process without losing any generality.
5. Soft Margins and the Hinge Loss
The relationship between Hinge Loss and Support Vector Machines (SVMs) is fundamental; in fact, Hinge Loss is the specific loss function that the soft-margin SVM algorithm is designed to minimize.
To see this connection clearly, let’s look at the goals of each and how their mathematical formulations merge into one.
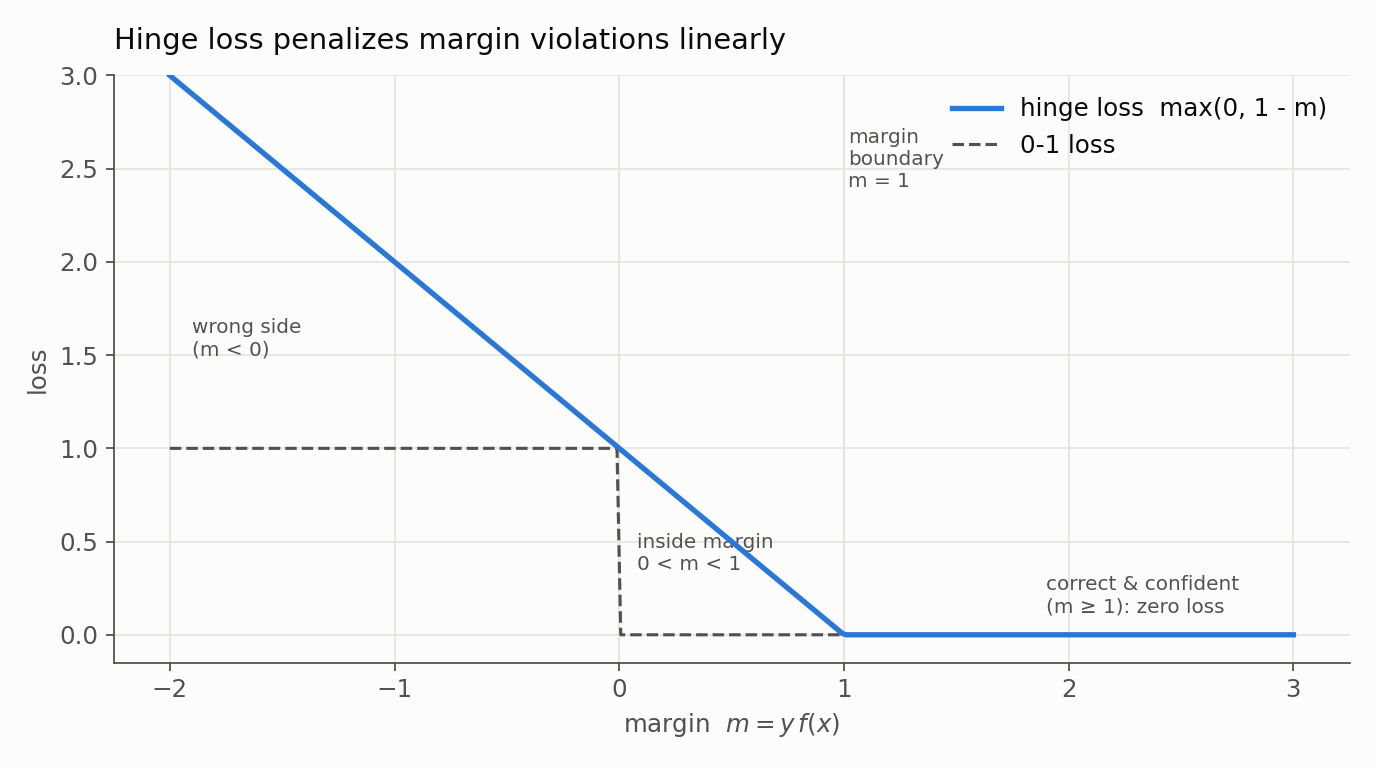
1. What is Hinge Loss?
Hinge Loss is a loss function used for “maximum margin” classification. It’s designed to penalize data points not just for being misclassified, but also for being too close to the decision boundary (i.e., inside the margin).
For a data point with a true label $y \in \{-1, +1\}$ and a raw model output (or score) $f(\mathbf{x})$, the Hinge Loss is defined as:
\[L(y, f(\mathbf{x})) = \max(0, 1 - y \cdot f(\mathbf{x}))\]Let’s interpret this formula:
- If $y \cdot f(\mathbf{x}) \ge 1$: This means the point is classified correctly and is on or outside the correct margin boundary. The term $1 - y \cdot f(\mathbf{x})$ is zero or negative, so the
maxfunction makes the loss 0. The model is not penalized. - If $y \cdot f(\mathbf{x}) < 1$: This means the point is either on the wrong side of the hyperplane or it is correctly classified but lies inside the margin. The term $1 - y \cdot f(\mathbf{x})$ is positive, and this value becomes the loss. The penalty increases linearly the further the point is from the correct margin.
In essence, Hinge Loss says: “I don’t care about points that are correctly classified with confidence. I only care about penalizing points that violate the margin.”
2. The Soft-Margin SVM Formulation
In the real world, data is rarely perfectly separable. The soft-margin SVM was introduced to handle this by allowing some points to be misclassified or to lie inside the margin. It does this by introducing a slack variable $\xi_i$ for each data point $\text{x}_i$.
The objective of the soft-margin SVM is to solve the following optimization problem:
Minimize:
\[\frac{1}{2}\|\mathbf{w}\|^2 + C \sum_{i=1}^{n} \xi_i\]Subject to the constraints:
- $y_i(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1 - \xi_i$
- $\xi_i \ge 0$
Here:
- Minimizing $\frac{1}{2}\lVert\mathbf{w}\rVert^2$ is equivalent to maximizing the margin.
- $\xi_i$ is the slack variable that measures how much point $i$ violates the margin. If $\xi_i=0$, the point is correctly classified outside the margin. If $\xi_i > 0$, it’s a margin violator.
- Minimizing $\sum \xi_i$ means minimizing the total amount of margin violation across all points.
Cis a hyperparameter that controls the trade-off between maximizing the margin and minimizing the violations.
3. The Connection: Unveiling the Hinge Loss
Now, let’s connect the two concepts. Look at the first constraint of the SVM:
\[y_i(\mathbf{w} \cdot \mathbf{x}_i + b) \ge 1 - \xi_i\]We can rearrange this to express $\xi_i$:
\[\xi_i \ge 1 - y_i(\mathbf{w} \cdot \mathbf{x}_i + b)\]We also know that $\xi_i$ must be greater than or equal to 0. Since the SVM’s objective function includes minimizing the sum of all $\xi_i$, the optimization will naturally push each $\xi_i$ to be the smallest possible value it can be while satisfying both conditions.
Therefore, for each data point, the optimal value of the slack variable $\xi_i$ will be:
\[\xi_i = \max(0, 1 - y_i(\mathbf{w} \cdot \mathbf{x}_i + b))\]This is exactly the definition of the Hinge Loss where the model’s raw score is $f(\mathbf{x}_i) = \mathbf{w} \cdot \mathbf{x}_i + b$.
Re-framing the SVM Objective
Now that we see that the slack variable $\xi_i$ is just the Hinge Loss for point $i$, we can rewrite the SVM’s objective function by substituting it in:
Minimize:
\[\underbrace{\frac{1}{2}\|\mathbf{w}\|^2}_{\text{Regularization Term}} + C \sum_{i=1}^{n} \underbrace{\max(0, 1 - y_i(\mathbf{w} \cdot \mathbf{x}_i + b))}_{\text{Hinge Loss Term}}\]This new perspective makes the relationship crystal clear:
- The SVM objective is a combination of two things:
- Hinge Loss: The sum of the Hinge Loss over all training points. This measures how much the model fits the training data (empirical risk).
- Regularization: The term $\frac{1}{2}\lVert\mathbf{w}\rVert^2$ (also called an L2-regularizer) penalizes model complexity and is responsible for maximizing the margin (structural risk).
The Soft-Margin Dual and the Role of C
Deriving the dual of this soft-margin problem (the same Lagrangian machinery we develop in Part 2, now with multipliers for the slack constraints too) produces a pleasant surprise: the dual objective is unchanged. The slack variables and $C$ do not appear in the quadratic form. Their only effect is to cap each multiplier from above:
\[\begin{aligned} & \max_{\alpha} & & \sum_{i} \alpha_i - \frac{1}{2} \sum_{i} \sum_{j} \alpha_i \alpha_j y_i y_j (\mathbf{x}_i \cdot \mathbf{x}_j) \\ & \text{subject to} & & 0 \le \alpha_i \le C \quad \text{and} \quad \sum_{i} \alpha_i y_i = 0. \end{aligned}\]So the move from hard to soft margin adds exactly one thing to the dual: the box upper bound $\alpha_i \le C$. That single bound is what produces the “bounded support vector” case in the KKT analysis of Part 2.
The hyperparameter $C$ trades off the two terms, and it is worth reading in both directions:
- Large $C$ penalizes violations heavily, pushing toward a narrower, less regularized boundary that fits the training data closely (and can overfit).
- Small $C$ tolerates more violations in exchange for a wider, more regularized margin.
The effect on test accuracy or on the number of support vectors is not monotonic in $C$, so tune it by validation rather than assuming “more $C$ is better.”
In conclusion, Hinge Loss is not just related to SVM; it is the loss function that defines the classification error that the soft-margin SVM aims to minimize. This perspective shows that SVMs are part of a broader family of machine learning models that work by minimizing the sum of a loss function and a regularization term.
6. A Worked Example, End to End
Everything so far has been abstract. Let’s ground it in a dataset small enough to check by hand. Take four positive points and four negative points in 2D:
- Class +1: (2,2), (2,3), (3,2), (3,3)
- Class −1: (0,0), (0,1), (1,0), (1,1)
By symmetry, the widest street runs along the line $x_1 + x_2 = 3$, with normal direction $\mathbf{w} \propto (1,1)$. Canonical scaling pins the two nearest points, (2,2) and (1,1), to functional margin $\pm 1$: solving $\mathbf{w}\cdot(2,2)+b = 1$ and $\mathbf{w}\cdot(1,1)+b = -1$ together gives $\mathbf{w} = (1,1)$ and $b = -3$.
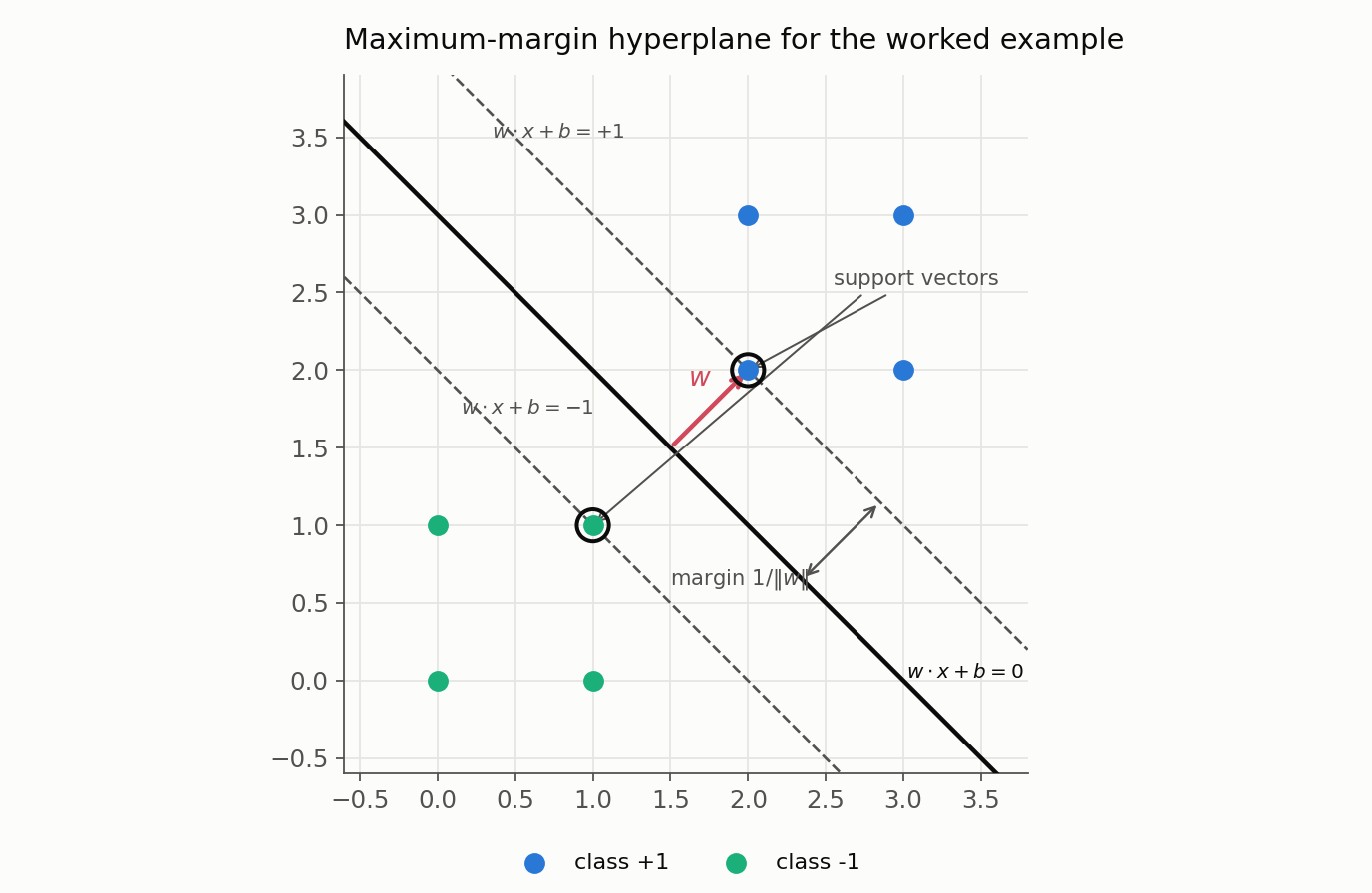
Now verify the pieces, all from the decision score $\mathbf{w}\cdot\mathbf{x}+b = x_1 + x_2 - 3$:
- Functional margins $y_i(\mathbf{w}\cdot\mathbf{x}_i+b)$: the two nearest points, (2,2) and (1,1), score exactly $\pm 1$, so their functional margin is $1$; every other point scores $\ge 2$ in magnitude. All constraints hold, and only (2,2) and (1,1) are active, which makes them the support vectors.
- Margins. $\lVert\mathbf{w}\rVert = \sqrt{2}$, so the one-sided margin is $1/\sqrt{2} \approx 0.707$ and the full width is $2/\sqrt{2} = \sqrt{2} \approx 1.414$, exactly the distance between (2,2) and (1,1).
- An unseen point at $(1.5, 2.0)$ scores $1.5 + 2.0 - 3 = 0.5 > 0$, so the model predicts class $+1$.
Fitting this in scikit-learn (approximating the hard margin with a large C) recovers the same numbers exactly:
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
from sklearn.svm import SVC
X = np.array([(2,2),(2,3),(3,2),(3,3),(0,0),(0,1),(1,0),(1,1)], float)
y = np.array([1, 1, 1, 1, -1, -1, -1, -1])
clf = SVC(kernel="linear", C=1e6).fit(X, y)
print(clf.coef_[0], clf.intercept_[0]) # [1. 1.] -3.0
print(clf.support_vectors_) # [[1. 1.] [2. 2.]]
print(clf.dual_coef_[0]) # [-1. 1.] (alpha * y for each SV)
print(clf.decision_function([[1.5, 2.0]])) # [0.5] -> class +1
We revisit this exact model through the dual in Part 2, where those two support vectors reappear as the only points with non-zero $\alpha$.
Making it non-separable. Now drop one mislabeled point into the mix: a class $-1$ example at $(2.5, 2.5)$, deep in positive territory. Under the same boundary it scores $2.5 + 2.5 - 3 = 2$, so its functional margin is $y(\mathbf{w}\cdot\mathbf{x}+b) = (-1)(2) = -2$, and its hinge loss (its slack) is $\max(0, 1 - (-2)) = 3$. The hard margin now has no feasible solution, but the soft margin simply pays that hinge penalty. The hyperparameter $C$ decides how hard the model fights to reduce it: a large $C$ bends the boundary toward the intruder, a small $C$ keeps the street wide and absorbs the violation. That is the hard-to-soft transition made concrete, on the same dataset rather than a disconnected new one.
One practical note the toy example hides: SVMs are not scale invariant. The margin is measured in raw feature units, so a feature with a large numeric range dominates $\lVert\mathbf{w}\rVert$. In real pipelines, standardize first:
1
2
3
4
5
6
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
model = make_pipeline(StandardScaler(), SVC(kernel="linear", C=1.0)).fit(X, y)
model.decision_function([[1.5, 2.0]]) # signed, distance-like confidence
With the linear SVM and its soft-margin objective in hand, we can re-express the whole problem in a form that reveals the support vectors and opens the door to non-linear boundaries. Continue to Part 2: The Dual and Support Vectors.